[chromium]
name=Chromium build for Fedora $releasever - $basearch
baseurl=http://spot.fedorapeople.org/chromium/F$releasever/
enabled=1
gpgcheck=0
在 Django 的 View 中调用 syncdb
完全吃不消 SAE 的 MySQL 各种限制了,无数次地清空数据库 -> 重新初始化 -> 导入 SQL 文件。
为什么不能在 Django 中建立好 Model 后,直接从 Django 的 View 里 syncdb 呢。
from django.http import HttpResponse
def syncdb(request):
from django.core.management import call_command
from cStringIO import StringIO
import sys
old_stdout = sys.stdout
sys.stdout = mystdout = StringIO()
mystdout.write('<pre>')
call_command('syncdb')
mystdout.write('</pre>')
sys.stdout = old_stdout
mystdout.seek(0)
return HttpResponse(mystdout.read())
什么时候再把 South 整合进去就完美啦~~~ ;-)
Long polling
这两天在公司的项目里用了 Long polling,了解了它的实现原理,其实不像它的名字那么玄乎,只是 Ajax 和 HTTP 的类似小妙招的办法。
先解释一下 Long polling 是什么:
首先得说到传统的 Polling,Polling 是 Ajax 隔一段时间去抓取服务器上的数据,检查数据是否更新,但这样有很大问题,首先是每次请求会实用一个 HTTP request,对应的服务器就得建一个新的线程来处理这个 HTTP request,消耗网络流量、服务器资源不说,绝大多数情况下,数据短时间内是不会更新的,也就是说绝大多数的 Ajax 请求都只能无功而返。
而 Long polling 就是用来解决这个问题的。
它的核心是:
1. 做一个超时非常长的 Ajax 请求,并且在错误捕获代码里不断执行自己。2. CGI 部分接收到请求后在限定的时间内(Ajax 超时时间内)每隔一段时间(例如一秒)对数据库进行查询,可以使用 sleep 类似的方法。
3. 如果有新的数据则返回,如果即将到 Ajax 超时的时间则返回一个错误值,比如 404,这样那个非常长的 Ajax 请求会再发一个过来,继续查询。
这个办法的最大价值是有效减少了 HTTP 请求数,对服务器而言就不用开启新的线程去处理它,旧的线程如果不是因为超时,则只会在数据已经更新的情况下返回数据。可以节约大量资源,而且实时性更高。
目前,人人网的消息提示、Web 版阿里旺旺、新浪微博的新微博提示应该都是使用这种方法做的。
但这个办法对开发有
所以最好做好两套配置,一套用于产品环境的多线程环境,
我依然对那位在现有架构下想出这种办法的人表示钦佩。
这儿有范例代码,简单又实用:http://stackoverflow.com/questions/333664/simple-long-polling-example-code
几个手机的性能测试。
趁着职务之便,能接触到不少手机,所以本着见啥测啥的精神,就有了此文。
目前测试软件只有 Quadrant Advanced,如果谁知道有其它测试软件,尤其针对应用程序 Load 时间的,欢迎推荐。
最后声明一下:本测试纯属个人兴趣,如果对某商品起到了促销作用纯属巧合,影响了某商品的销量也概不负责啊。
| 测试项目\测试机型 | Sharp 8128u | Nexus One | HTC Incredible | Samsung i9000 | |
| 设备配置 | CPU | 高通 7x27(ARMv6) | 高通 QSD8250(ARMv7) | 高通 QSD8650(ARMv7) | 三星 GT-I9000 |
| 主频 | 122.88MHZ-600MHz | 245MHz-1113.6MHz | 128Mhz-1228.8MHz | 100MHz-1000Mhz | |
| BogoMIPS | 429.72 | 662.40 | 662.40 | 99.73 | |
| 机身内存 | 407316KB | 412052KB | 422908KB | 333416KB | |
| 屏幕分辨率 | 800x480 | 800x480 | 800x480 | 800x480 | |
| GPU | Adreno ?? | Adreno 200 | Adreno 200 | PowerVR SGX 540 | |
| OS | 点心OS(2.1-update1) | MIUI 1.3.18(2.2.1) | HTC Sense 2.0 | TouchWiz 2.1 | |
| Kernel | 2.6.29-perf | 2.6.35.9 | 2.6.32.28-ck2-CFS | 2.6.29 | |
|
Quadrant Advanced 1.1.6 (2010-12-30) |
总分 | 272 | 1279 | 1372 | 850 |
| CPU | (因AAC解码崩溃无法继续 ) | 4050 | 4768 | 716 | |
| Memory | 617 | 1042 | 829 | 1765 | |
| I/O | 382 | 654 | 575 | 640 | |
| 2D | 100 | 263 | 276 | 302 | |
| 3D | 261 | 391 | 392 | 827 | |
旧年总结和新年计划。
今天大年初一,祝大家新年走大运,工资节节高。
白天串了一天亲戚,晚上来想想一下去年都做了些什么比较有意义的事情,新年又应该做些什么了。
2010 旧年总结:
职业上
- Nitrate 进入稳定阶段,成功将推入公司内部,将旧的 Testopia 关掉,成为测试部唯一测试用例管理工具。
- 成功将 Nitrate 推入 Fedorahosted,正式开放源代码,并计划在 Fedora 15 的时候推广到 Fedora 社区内部测试,并计划在 Fedora 16 的时候正式使用,替代掉现有 Wiki 系统。
- 成功拿下 RHCE 和 Certified Scrum Master 认证,前者早就拿过只是刷新一下,后者让我对软件工程管理有了新的认识。
- 因感到个人技术瓶颈,离开了 Red Hat,寻找新的发展。
生活上
- 买了一套房子,正式成为房奴。
- 经过了近三年的发展,和女朋友感情进入平稳阶段,吵闹的事情减少了很多。
- 爷爷经历了84危机,好在平稳度过,目前已经无恙。
2011 新年计划:
职业上
- 寻找新的发展,并寻找转型机会,希望能将 Red Hat 先进的工作流和管理经验带入其它公司。
- 继续参加培训,提高自身水平。软件开发、管理课程、礼仪、沟通与交流、心理学/哲学方面都是不错的主题。
- 探索一些新的领域,例如互联网,移动开发,高负载下的性能优化等等。
- 启动新的项目,作为个人历练用,因为是个人项目,所以有更多“研发”的工作,用一些新的经验,新的思路,新的想法。已经有了目标,一是重写 Nitrate,二是编写一个新的项目管理工具,将 Scrum 的理念带入其中。
- 参与 Django 项目开发,适时提交补丁。
生活上
- 如果不出问题,应该会在今年结婚。
- 去考一个车本,驾驶是现在必备的技能。
- 学学喝酒。
- 阅读更多、更广泛的书籍,不再局限于软件开发方面。
- 去旅游。
- 学习一下乐器,家里的 MIDI 键盘和吉他都买了好久了,一直没动力去认真学,打算用学习编写软件的方法,跳过理论,直接实践了。
- 照顾好家人,常回家看看,尤其家里老人,可能时日无多。
希望到明年这个时候,回过头来,计划都能够完成。
春运又到了,献上更新版抓黄牛脚本。
好不容易搞定了火车票(当然不是通过酷讯或者黄牛),把去年写过的抓黄牛脚本重写了一下,提供给各位还在等待购买火车票的 Programmer 使用。说是抓黄牛,自然还包括普通转票者。原理还是通过轮询酷讯网站上的内容,但是增加了几个新特性:
- 用 re 提供的正则表达式替换掉了 SGMLParser 提高效率
- 可以轮询多个地址了,比如我到吉安和井冈山都可以,所以我要遍历两个地址
- 可以将转向链接直接打印在屏幕上了
- 提供了 Python 3 的 Package 级支持,但是因为 re 模块变更,正则表达式在 Python 3 里无法运行,暂时没心思更新了。
尽管酷讯推出了秒杀器,不过还是觉得不妥,一是没任何输出,谁知道它是否真的能秒到,二是不跨平台,在 Mac 和 Linux 上暂时无法使用。
Patches are welcome. :-)
#!/usr/bin/python
# encoding: utf-8
#
# Catch the yellow cattles script
#
# Author: Xuqing Kuang <xuqingkuang@gmail.com>
# New features:
# * Use regexp to instead of SGMLParser for performance
# * Polling multiple URL at one time.
# * Print out the redirect URL.
# * Basic packages compatible with Python 3
# TODO:
# * Use one regexp to split the href and text of link
# * Update re package usage to compatible with Python 3
import time
import os
import re
try:
import urllib2 as urllib
except ImportError: # Python 3 compatible
import urllib.request, urllib.error
urls = (
"http://piao.kuxun.cn/beijing-jinggangshan/",
"http://piao.kuxun.cn/beijing-jian/",
)
keyword = '3张'
sequence = 60
class TrainTicket(object):
"""
Catch the yellow cattle
"""
def __init__(self, urls, keyword, sequence = 60):
self.urls = urls
self.keyword = keyword
self.sequence = sequence
self.cache=[]
self.html = ''
self.links = []
if hasattr(urllib, 'build_opener'):
self.opener = urllib.build_opener()
else: # Python 3 compatible
self.opener = urllib.request.build_opener()
self.result = []
self.re_links = re.compile('<a.*?href=.*?<\/a>', re.I)
# self.re_element = re.compile('', re.I) # Hardcode at following
self.requests = []
for url in urls:
if hasattr(urllib, 'Request'):
request = urllib.Request(url)
else: # Python 3 compatible
request = urllib.request.Request(url)
request.add_header('User-Agent', 'Mozilla/5.0')
self.requests.append(request)
def get_page(self, request):
"""
Open the page.
"""
try:
self.html = self.opener.open(request).read()
except urllib.HTTPError:
return False
return self.html
def get_links(self, html = ''):
"""
Process the page, get all of links
"""
if not html:
html = self.html
self.links = self.re_links.findall(html)
return self.links
def get_element(self, link = ''):
"""
Process the link generated by self.get_links().
Return list of the href and text
"""
# FIXME: have no idea how to split the href and text with one regex
# So use two regex for temporary solution
href = re.findall('(?<=href=").*?(?=")', link) # Get the href attribute
if not href: # Process the no href attr
href = ['']
text = re.split('(<.*?>)', link)[2] # Get the text of link a.
href.append(text) # Append to the list.
return href
def get_ticket(self, request = None):
"""
Generate the data structure of tickets for each URL.
"""
if not request:
request = self.requests[0]
self.get_page(request)
self.get_links()
i = 0
while i < len(self.links):
link = self.get_element(self.links[i])
if not link:
continue
url = link[0]
name = link[1]
if name and name.find(keyword) >= 0 and url not in self.cache:
self.result.append((
i, name, url,
))
self.cache.append(url)
i += 1
return self.result
def print_tickets(self):
"""
Process all of URLS and print out the tickets information.
"""
while 1:
self.result = []
try:
print('Begin retrive')
for request in self.requests:
print('Begin scan %s' % request.get_full_url())
self.get_ticket(request)
print('Found %s urls.' % len(self.links))
for r in self.result:
print('Index: %s\nName: %s\nURL: %s\n' % (
r[0], r[1], r[2]
))
print('Scan finished, begin sleep %s seconds' % self.sequence)
time.sleep(self.sequence)
except KeyboardInterrupt:
exit()
except:
raise
if __name__ == '__main__':
tt = TrainTicket(urls, keyword, sequence)
tt.print_tickets()
高内聚、低耦合、SOA 和测试驱动。
软件工程:
随着软件工程的不断膨胀,功能的扩展变得愈发困难,因为增加一点点小功能而导致的 Regression 可能会越来越多,同时,因为项目越来越大,参与的人越来越多,代码的结构化、模块化便成了高质量产品非常重要的特性之一。
高内聚和低耦合,其实是好的模块化编程必须具备的两项特点,高内聚,我的理解模块独立完成特定,不重复实现其他模块已经实现过的逻辑,而低耦合,即模块与模块之间的直接连接要尽量低下,耦合性高,会导致牵一发而动全身,将导致未来的代码维护和功能扩展愈发艰难。
最简单的模块化即现在 Web 开发的 MVC 架构,数据库的建模部分由 Model 完成,页面展示由 Views 完成,而之间的协调和逻辑关系由 Controller 完成,以一个 Product 项目的创建为例,它会在创建时同时创建好另外两个字段的默认值 - Version 和 Component,当 Views 接收到用户的输入后,然后将它传递给 Controller,Controller 将会判断输入的合法性并同时创建好另外两个字段的类,再通过调用 Models 提供的方法将这三个类在数据库中持久化下来。
这需要在开发前定一套统一的 API,这样各个模块才能无障碍地随意调用。
那么这样的好处在哪里?其实是非常明显的,页面显示部分不用关注数据库会提供什么养的类型,而数据库也不用关注用户会提供什么格式的数据,都会因为中间 Controller 的调度和转化被统一起来,进而达到程序的模块化,以及开发人员的专职化。
以我自身经验为例,如果要和前端配合同时完成一套功能,我们会约定好我给他什么样的 Ajax method,参数是什么,返回的是什么样的格式,这样我们两个能够同时编写不同的代码,但到功能完成之时,将两个代码放在一起,直接就能运行起来。
SOA:
那么程序与程序之间的整合,使之同时完成一项功能如何才能做到?
传统的方法有提供 RPC 接口,轮询数据库或者文件系统,但是问题在哪里?
- XML-RPC 同样会出现错误,而且缺乏 Error handler
- 数据库和文件系统的轮询有很高的风险,首先轮询文件系统就以为着这个目录里的文件要小心放置了,因为不小心就会被程序轮询到,而因为轮询造成的数据库损坏的可能性更加难以纠正。
- 很低的内聚性,很高的耦合性,为了同步两个程序间的数据,可能得克隆一份对方程序里的数据结构和逻辑方法,一旦任何一方的数据结构或逻辑改变,将导致同步失败。
- 不实时,因为轮询总是有时间间隔的,轮询频繁会导致系统负载加重,轮询频率低了又容易等待时间过长。
那么程序之间的整合如何才能更好地做到,这就需要将 SOA 的思想引入进来了,SOA - Service Orient Architechture,面向服务的架构,程序与程序之间不再是程序,而是一个个的服务,这个服务可以通过 RPC 来实现对自身方法的调用,但是还有很重要的一点,是要将自身正在做的事情告诉别的程序。
下图是 Nitrate 项目目前的结构,其实我觉得它是模块化开发的一个典范了。
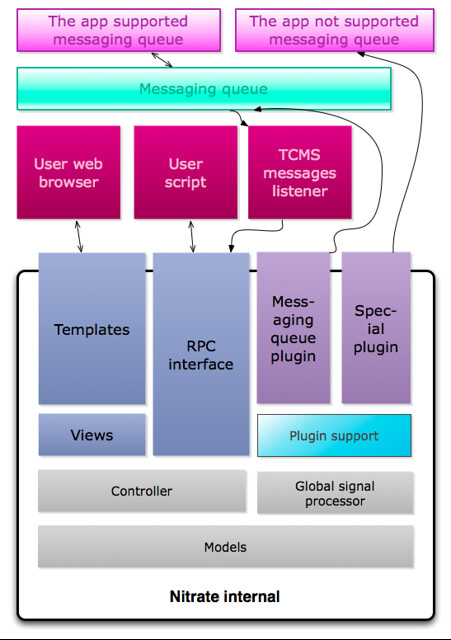
Nitrate 是标准的 MVC 架构,我来解释一下它的工作流,除了基本的 Web UI 界面和 XML-RPC 界面外,我们还提供了 Global signal processor(后简称 GSP)用于监听所有 Models 的信号,目前信号有三种 - Initial,对应于数据库的 SELECT 语句,Create 对应于数据库的 Insert 语句,Update 对应于数据库的 Update 语句,所有被注册的 Models 一旦发生以上动作将会出发对应的信号,然后 GSP 将信号推入 Plugin support(后简称PS),由它以线程方式将 Signal,Models 和触发消息的 Model Instance 交由 Plugin 处理。
这里我将 Plugin 分为了两类:
一类是 Special plugin,用于整合一些特殊的程序,这些程序不带有消息队列支持,它是以传统工具整合方式工作的,接受到信号后会根据已经定义好的参数判断信号是否符合条件,如符合则通过该 Special 程序提供的 RPC 接口将 TCMS 中的改动同步进该程序中,事实上该方法危险性较高,而且需要将对方的数据库表格和参数定义在插件里。
第二类是 Messaging queue plugin,这是我最偏好的方法,目前支持的 Messaging queue(以后简称 MQ)是 QPID,它将 Models 的 Signal 转译成 MQ 的数据格式,然后直接推入 MQ,然后别的需要 Nitrate 数据的程序可以提供第三方的一个 Sync middleware,作为两个程序间的桥梁对数据进行选择性的同步,这样的好处是逻辑不用重复实现,双方共享的数据之需要存在 Sync middleware 程序中即可,不影响双方逻辑和数据库结构。而 Nitrate 本身也提供了 TCMS Messenging listener 用于监听 MQ 内的 message,例如如果 Bugzilla 新创建了一个 Product,Nitrate 将很快便能监听到并在数据库中创建一份相同的 Product 供用户使用,全程自动化,智能化,无人干预。
“能听能说”的程序才能较好地整合到其它程序中,“听” 提供了 XML-RPC 接口,别的程序可以通过它更改 Nitrate 中的数据,“说”提供了 MQ 的支持,别的程序可以监听 Nitrate 中数据的变化,并以此为依据对自身数据进行添加、更改,而且不用存储对方数据表,不用了解对方的业务逻辑,只需要写好中间的 Sync middleware 即可,好处多多,其乐无穷。
测试驱动
在之前的 Scrum 培训总结中,我说到了 CI(Continuous Integration)是 Scrum 所要求必备的,那么为什么单元测试如此重要?
下面的图可以充分说明这点:
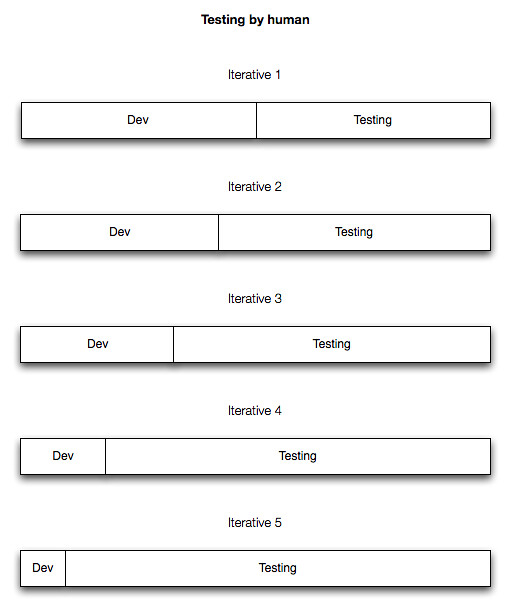
尽管手工测试可以降低编码时间,但这也仅仅是在项目非常非常小,而且没有后期维护成本的情况下。从上图可以看出,在第一个迭代的时候,开发如果和测试的时间是一样长,这或许可以生产出一个高质量的产品,但是到第二个迭代的时候,开发人员仅仅向软件中加入了很少的 Feature,但是测试却不能减少他们的工作量,依然要进行一遍完整的测试,而且还要检查是否有因为新加入的 Feature 导致的 Regression,到第三个迭代的时候开发的时间更加少,到第五个迭代后开发已经完全没用了,尽管测试占用的时间比例很大,但是依然无法保证测试完成,产品推到生产环境下会发现问题多多,开发人员就成了救火队员,下个迭代可能要用整个迭代的时间,去修上个迭代造成的 Bug,软件将停滞不前。
那么针对不同类型的语言和软件类型,有什么 Unit Testing 的方式呢?
这要从语言的类型和特点说起了。
* HTML,CSS - 前段,结构远远大于逻辑的语言。因为浏览器的兼容性问题,它是最难进行自动化测试的语言,但是依然是有办法的,可以使用类似 Dogtail 类的自动UI点击程序,判断 Console 中的错误输出,或者使用 W3C Validator 一类的工具,对它进行错误判断。
* Python/PHP/Java - 后端,结构和逻辑并重的语言。其实它是最好编写 Unit testing 的语言,因为它只负责一件事情:提供 API 供调用,我们只需要模拟输入,判断程序是否会出现 Error 即可,Django 提供了很好的 Unit testing 框架,可以模拟客户端的提交数据,以检测 Views 和 Controller 能否正常工作,Models 能否对数据库正常读写,或者 ForeignKey 的正确性也可以通过 UT 进行验证,Java 也提供了 JUnit 等工具。
* Javascript/其它 UI 语言 - 前端,结构和逻辑并重的语言。这是最有意思的地方,很多人说 UI 类的语言的 UT 非常难以编写,因为无法验证最终的正确性,其实仔细观察就可以看出,这类语言,其实只是调用了后端提供的 API,也就是说,对于此类语言,一检查提供给后端的 API 的参数是否正确,二检查能否将后端的返回正常生成数据结构并反应在页面上即可。前者依然可以通过检查后端的出错情况,而后者可以通过更改编码方式,将逻辑层和显示层拆分解决,例如后端返回的数据需要生成一个按钮,只需要将生成按钮的代码拆分,并通过单元测试检查按钮是否正常生成并符合条件即可,因为只要能正常生成,基本上现实在页面上不会出太大问题,这是基本功能了。
另外说一句有意思的事情,前两天听说了另一种 UT 的方式,名称叫 Monkey,写一个程序在屏幕上随机乱点,只要程序能稳定跑上几个小时就算通过,这来源于让猴子敲键盘,总有一天能敲出莎士比亚全集的传说。这也算是很有创意了,只是我觉得这不能叫 UT,可能只能叫 RT(Random Testing)了,缺点很明显,一是无法针对某个功能,二难以重现(可重现的 Bug 对开发人员很重要),三难以统计。
字符串反转和判断素数的 Python 语言算法范例
第一个是反转字符串,前两种是我出来丢人的,请直接看第三种。
方法1:
取出最大长度并 -1,以此为索引,依次递减,并将结果加入数组。
def reverse(string):
if not string:
return string
str_list = []
i = len(string) - 1
while(i >= 0):
str_list.append(string[i])
i -= 1
return ''.join(str_list)
方法2:
类似 C 中的位移操作,使用一个中间变量 t 记录临时值,然后将前后为置换,时间主要花在将字符串转换成数组上,实际遍历只需要上面方法的一半,但比上面方法要多消耗一个临时变量 t 的内存。当然,如果用 C 就可以直接指向内存,这样最节省内存,但是 Python 可能没更好办法。
但因为对 str 操作会造成 TypeError,所以还需要组成一个临时数组并在最后合并。
def reverse2(string):
if not string:
return string
idx = 0
length = len(string) - 1
h_length = length / 2 # Half of length
# 'str' object does not support item assignment for Python
# Use C to solve it will be better.
# So we convert it to be a list from the string.
str_list = [x for x in string]
while(idx <= h_length):
t_idx = length - idx
# Use varible t to store the temporary string
t = str_list[t_idx]
# Start to move the bit
str_list[t_idx] = str_list[idx]
str_list[idx] = t
idx += 1
return ''.join(str_list)
方法3:
由 @Cotton 提供,直接用数组的方式,通过本用来做间隔数的段落进行反向遍历,我只能赞叹一句,Python 太强大了!
def reverse3(string):
return string[::-1]
另一个是求素数,没想出什么比较好的算法,只能递归,但是因为除法(求余)非常缓慢,所以我对此算法非常不满。
方法1:
这里使用一个 range 直接生成一个数组,并用 for 递归,因为我觉得一次生成数组的速度应该比多次改写一个变量速度要快,但是自然,消耗内存稍大,如果对内存有要求,也可用 while 加递减代替。
def is_prime1(num):
# Initial to presume it's a prime
rt = True
# It seems every number is possible to be the one, so it have to make a range.
for i in range(2, num):
if num % i == 0:
rt = False
break
return rt
方法2:
由 jyf1987 提供,双数的判断一次解决(但是 3、5 的倍数如何能更快地排除呢?),剩下的是单数的递归,同时引入平方根(很好的想法,因为大于平方根后的数的计算已经没有意义,因为另一个数必然也是之前计算过的,因为 N = a*b,所以 N=M^2),降低运算量,引入 xrange 降低内存使用量,因为是原生实现,我相信应该不会比直接用 range 生成数组更慢。
from math import sqrt
def is_prime2(num):
# Checking the Type/value
if type(num) != int:
raise TypeError
if num < 2:
raise ValueError('The number must be great than 1')
# Inital to presume it's a prime
rt = True
sq_num = int(sqrt(num))
# First we detect is it prime for 2
if num == 2:
return rt
if num % 2 == 0:
rt = False
return rt
# Now, start to detect the odd number
# Because all of even number could division by 2, then how about 3? -_-#
for i in xrange(3, sq_num, 2):
if num % i == 0:
rt = False
break
return rt
冰天雪地三十六度翻转跪求更好算法~嘿嘿。。。
QPID 消息队列初步
QPID 是一种高性能 Message Bus,目前因为牵扯到工具的 SOA 架构,我的项目中将会整合它,以将自身对数据库的修改提交到 Message Bus 中, 供其它程序监听调用。
目前主流的 Message Bus 主要有以下几种:
而之所以选择 QPID 是因为它有以下几个优点(引用源):
- Supports transactions
- Persistence using a pluggable layer — I believe the default is Apache Derby
- This like the other Java based product is HIGHLY configurable
- Management using JMX and an Eclipse Management Console application - http://www.lahiru.org/2008/08/what-qpid-management-console-can-do.html
- The management console is very feature rich
- Supports message Priorities
-
Automatic client failover using configurable connection properties -
- http://qpid.apache.org/cluster-design-note.html
- http://qpid.apache.org/starting-a-cluster.html
- http://qpid.apache.org/cluster-failover-modes.html
- Cluster is nothing but a set of machines have all the queues replicated
- All queue data and metadata is replicated across all nodes that make up a cluster
- All clients need to know in advance which nodes make up the cluster
- Retry logic lies in the client code
- Durable Queues/Subscriptions
- Has bindings in many languages
- For the curious: http://qpid.apache.org/current-architecture.html
而对我而言,QPID 比较有优势的地方是,一有 Python 的 bindding(Perl 的兄弟对不起了),二是源代码比较充足。
为此我写了两个基类,简单地调用了 QPID Python 中的 Receiver 和 Sender,相对于 message_transfer 方法,这种方法可以传递 Dictionary 对象,一共三个文件,其实也可以合在一起使用。
#!/usr/bin/python
import qpid
import qpid.messaging
import logging
logging.basicConfig()
class QPIDBase(object):
def __init__(self, host='10.66.93.193', port='5672', queue_name='tmp.testing', username='guest', password='guest'):
"""
Arguments:
host
port
queue_name
username
password
"""
self.host = host
self.port = port
self.queue_name = queue_name
self.username = username
self.password = password
self.connection = None
self.session = None
def init_connect(self, mechanism='PLAIN'):
"""Initial the connection"""
url = 'amqp://guest/guest@%s:%s' %(self.host, self.port)
self.connection = qpid.messaging.Connection(
url = url, sasl_mechanisms=mechanism,
reconnect=True, reconnect_interval=60, reconnect_limit=60,
username=self.username, password=self.password
)
self.connection.open()
def init_session(self):
"""Initial the session"""
if not self.connection:
self.init_connect()
self.session = self.connection.session()
def close(self):
"""Close the connection and session"""
self.session.close()
self.connection.close()
#!/usr/bin/python
import qpid.messaging
from datetime import datetime
from base import QPIDBase
class QPIDSender(QPIDBase):
def __init__(self, **kwargs):
super(QPIDSender, self).__init__(**kwargs)
self.sender = None
def init_sender(self):
"""Initial the sender"""
if not self.session:
self.init_session()
self.sender = self.session.sender(self.queue_name)
def send(self, content, t = 'test'):
"""Sending the content"""
if not self.sender:
self.init_sender()
props = {'type': t}
message = qpid.messaging.Message(properties=props, content = content)
self.sender.send(message)
def typing(self):
"""Sending the contents real time with typing"""
content = ''
while content != 'EOF':
content = raw_input('Start typing:')
self.send(content)
if __name__ == '__main__':
s = QPIDSender()
s.send('Testing at %s' % datetime.now())
s.close()
#!/usr/bin/python
from pprint import pprint
from base import QPIDBase
class QPIDReceiver(QPIDBase):
def __init__(self, **kwargs):
super(QPIDReceiver, self).__init__(**kwargs)
self.receiver = None
def init_receiver(self):
"""Initial the receiver"""
if not self.session:
self.init_session()
self.receiver = self.session.receiver(self.queue_name)
def receive(self):
"""Listing the messages from server"""
if not self.receiver:
self.init_receiver()
try:
while True:
message = self.receiver.fetch()
content = message.content
pprint({'props': message.properties})
pprint(content)
self.session.acknowledge(message)
except KeyboardInterrupt:
pass
self.close()
# Test code
if __name__ == '__main__':
r = QPIDReceiver()
r.receive()
代码非常简单,容易读懂,使用方法是在一台 Linux Server 上安装好 qpid-cpp-server, 并且启动后,在 Client 上安装 python-qpid,然后修改一下 base.py __init__ 方法的 host 字段,或者在代码中自行指定好服务器地址,即可直接执行测试。
需要说明的是 QPID 返回的数据结构,包含可以为 Dictionary 对象的 properties 和只能为纯文本的 content 两个属性,也就是说可以将数据结构保存到 properties,而消息名称保存成 content 中,即:
try:
while True:
message = self.receiver.fetch()
content = message.content
pprint({'props': message.properties})
pprint(content)
self.session.acknowledge(message)
except KeyboardInterrupt:
pass
一个终端执行 receiver.py 监听消息,再开一个终端执行 sender.py,将会如以下输出:
$ python ./receiver.py
{'props': {u'type': u'test', 'x-amqp-0-10.routing-key': u'tmp.testing'}}
'Testing at 2010-12-06 14:54:59.536093'
如果有兴趣试下 QPIDSender.typing() 方法,再把 Kerberos 的用户名读出来,就可以做一个 IM 啦~
问题:现在似乎 Sender 发出的消息一次只能有一个 Receiver 接收,也就是现有代码不能用于 SOA,而这理论上应该是不应该的,依然在探索。
(可以尝试打开两个 receiver.py 测试)
Scrum 敏捷培训小节
敏捷里最重要的事情:
人、沟通、可用的软件、适应变化。
敏捷的特点:
- Self-Organize
- Cross-Functional
- Practice
- Learning
- Transparency
- Simplicity
- Inspect & adapt
- Iterative
3355 - 敏捷开发的基本构成:
3种角色:
- CSM(Certified Scrum Master)
- Product owner
- Team
5 种特性:
- Courage 勇气
- Force 专注
- Commitment 承诺
- Openess 开放
- Respect 尊重
Invest 模型:
- Independent
- Negotiable
- Valuable
- Estimatable
- Small
- Testable
PDCA:
- Plan
- Do
- Check
- Action
燃尽图:
在一个迭代内,将 Task 一点一点完成的线性图,正常情况下应该呈开始很平缓,中期急速下降,后期继续平缓的曲线,因为初期调查代码,寻找解决方案,Task 无法按量完成,中期快速完成 Task,后期快完成时速度减缓。不过这种情况不是绝对发生。
=====================
敏捷我的理解是,Product Owner 将用户的需求以 User Story 的方式写出来,由 Dev Team 分解成 Task,以自愿认领、自我估算开发时间的方式,以迭代的周期(1周太短,1月太长),以最终有价值的可用的软件为目标的开发方式。
它和传统开发模式的最大区别是,不再以需求为导向,也不用再写大量的需求文档,而将重点转移到了在每个迭代的周期结束时提供可用的软件为目标,换而言之,即不再以要求在特定时间内完成所有功能,而是通过短时间的迭代开发,快速交付可用的软件给用户,并及时得到反馈以决定下一个迭代的 Task。
敏捷的要求是 Product Owner 必须在每一个迭代的开始,公布 User Story,由 Team 拆分成 Task 并估算工作量,自愿认领 Task 并给与 Product Owner 承诺可以在这个迭代内完成,而这个迭代内,Product Owner 必须给予 Team 不被打扰的环境,和不会变化的 Task,尽一切力量在迭代结束时可以交付可用的软件,并在迭代结束时开启 Review 会议总结该迭代内的收获和教训,以及向 Customer 展示这个迭代内完成的功能。
敏捷对 Team 的要求是 Self-Organize 和 Cross-Fuctional,即“自组织”与“跨职能”,因为任务都是 Team 自行申请的,即可以做到自行规划开发计划,而“跨职能”则是指 Team member 能够主动去担当一些别的职位的工作,例如设计,测试等等。
而对项目的跟踪,也是通过 Task 的完成情况进行的,而具体表现,就是燃尽图。
我认为敏捷最大的优势有以下几个:
- 快速迭代,短期交付可用的软件给客户,可以及时得到反馈,如有问题,可以及时得到修改。
- Feature value,特性价值,对用户需求进行评估,优先完成最具有价值的特性。
- Task 自评估,自认领,自组织和跨职能,充分调动 Team 主人公精神,减少和 Product Manager 在认知上的矛盾,可以真正达到 6 倍速。
- Transparency,项目进度一目了然,工程问题容易暴露。
- Test driven 测试驱动开发,降低测试工作量,有效保证产品质量。
Django 应用程序调试
这里要介绍的是,全面的 Django app 调试,从最简单的打印变量,到使用 Django 自带的 Debug Middleware 调试 SQL,最后到全面的 Django debug toolbar 的使用。
2. Django debug context processor[1](中级)
3. Django debug toolbar[2](更简单而强大。。。 -_-#)
这是最简单的办法,在启动了 django-admin runserver 后,可将变量打印到终端上,适用于临时性的排错,当然还有其它办法,只是我觉得这种办法最简单。
下面是简单范例。
from pprint import pprint from django.http import HttpResponse from myapp.core.models import Case def index(request, template = 'index.html'): c = Case.objects.select_related('author').get(pk = 100) pprint(str(c.query)) # 打印 C.objects.get(pk = 100) 调用的 SQL pprint(dict(c)) # 打印 C.objects.get(pk = 100) 的世纪内容。 return HttpResponse(c.__dict__)
二、Django debug context processor[1]
该 Middleware 主要用于调试 SQL 执行情况,能够将所有的数据库查询 SQL 及花费时间打印出来,但是它要求代码使用 RequestContext,普通的 Context 和 render_to_response() 便无法直接使用了,如果之前代码使用 Context 构建,可能需要重写这部分代码。
其实我推荐在开始编写代码的时候,就使用 django.views.generic.simple.direct_to_template 来渲染页面,像如下:
from django.views.generic.simple import direct_to_template def index(request, template = 'index.html'): ... return direct_to_template(request, template, { 'parameters': parameters, 'case': c, })
下面说安装和使用方法:
在 settings.py 的 'TEMPLATE_CONTEXT_PROCESSORS' 段中加入 'django.core.context_processors.debug',如下:
# RequestContext settings
TEMPLATE_CONTEXT_PROCESSORS = (
'django.core.context_processors.auth',
'django.core.context_processors.request',
'django.core.context_processors.media',
'django.core.context_processors.debug',
'myapp.core.context_processors.processor',
...
)
在 settings.py 中加入 'INTERNAL_IPS',用于识别开发机地址,内容写入本机 IP 地址即可:
# Needed by django.core.context_processors.debug:
# See http://docs.djangoproject.com/en/dev/ref/templates/api/#django-core-context-processors-debug
INTERNAL_IPS = ('127.0.0.1', )
然后,在共享模板的开头(别告诉我你一个页面一个模板文件。。。),加入生成 SQL 列表的代码:
<body id="body">
{% if debug %}
<div id="debug">
<p>
{{ sql_queries|length }} Quer{{ sql_queries|pluralize:"y,ies" }}
{% ifnotequal sql_queries|length 0 %}
(<span style="cursor: pointer;" onclick="var s=document.getElementById('debugQueryTable').style;s.display=s.display=='none'?'':'none';this.innerHTML=this.innerHTML=='Show'?'Hide':'Show';">Show</span>)
{% endifnotequal %}
</p>
<table id="debugQueryTable" style="display: none;">
<tr class="odd">
<td>#</td>
<td>SQL</td>
<td>Time</td>
</tr>
{% for query in sql_queries %}
<tr class="{% cycle odd,even %}">
<td>{{ forloop.counter }}</td>
<td>{{ query.sql|escape }}</td>
<td>{{ query.time }}</td>
</tr>{% endfor %}
</table>
</div>
{% endif %}
...
</body>
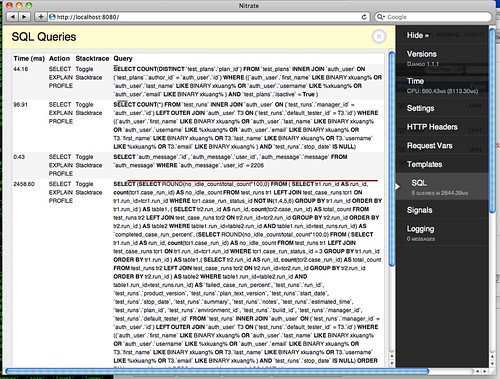
最终生成的效果是在页面顶部,增加了一个 XX Quueries 项,点击 (Show) 后如下:

Django debug toolbar 是我到目前为止见过的安装最简单,功能最强大的调试工具,它的主要特性有:
* 更加完善的 SQL 调试(比 Django debug processor 更加精准,Django debug contect processor 无法处理关系查询(Select related))
* 记录 CPU 使用时间(可惜没有针对代码级的 profile,希望未来的版本能增加这个功能)
* 完整记录 HTTP Headers 和 Request 请求
* 完整记录模板 Context 内容,包括 RequestContext 和直接传入的变量
* 记录 Signals
* python logging 模块的日志支持
安装也比较简单,可以使用 yum 直接安装,也从上面的地址下载后,直接使用 setuptools 通用的安装方法安装即可。
$ tar zxvf robhudson-django-debug-toolbar-7ba80e0.tar.gz $ cd robhudson-django-debug-toolbar-7ba80e0 $ python ./setup.py build $ sudo python ./setup.py install
如需确保安装正常,从 Python shell 里看看能否 import 即可,不出错,即安装正常:
$ python Python 2.6.1 (r261:67515, Feb 11 2010, 00:51:29) [GCC 4.2.1 (Apple Inc. build 5646)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import debug_toolbar >>>
然后是配置你的 settings.py。
我的调试 settings.py 和在产品服务器上运行的是不一样的,我也建议最好将二者分开,因为 Django app 开启 Debug 后对性能损耗非常严重。
将下面红字加入你自己的 settings.py 文件:
MIDDLEWARE_CLASSES = (
...
'debug_toolbar.middleware.DebugToolbarMiddleware',
)
INSTALLED_APPS = (
...
'debug_toolbar'
)
TEMPLATE_DIRS = (
...
'/Library/Python/2.6/site-packages/django_debug_toolbar-0.8.3-py2.6.egg/debug_toolbar/templates/', #按需修改!指向 debug_toolbar 的模板目录。
)
DEBUG_TOOLBAR_PANELS = (
'debug_toolbar.panels.version.VersionDebugPanel',
'debug_toolbar.panels.timer.TimerDebugPanel',
'debug_toolbar.panels.settings_vars.SettingsVarsDebugPanel',
'debug_toolbar.panels.headers.HeaderDebugPanel',
'debug_toolbar.panels.request_vars.RequestVarsDebugPanel',
'debug_toolbar.panels.template.TemplateDebugPanel',
'debug_toolbar.panels.sql.SQLDebugPanel',
'debug_toolbar.panels.signals.SignalDebugPanel',
'debug_toolbar.panels.logger.LoggingPanel'
)
然后使用 django-admin.py runserver 启动测试服务器,下图是 Django debug toolbar 的 SQL 查询页面。
相关链接:
[1] http://www.djangosnippets.org/snippets/93/
[2] http://github.com/robhudson/django-debug-toolbar/downloads
Django 下的 Kerberos 登录
Kerberos 这种统一用户名和密码进行登录的方式在各大公司(尤其外企)内部应该都得到广泛应用,它以其安全、高效和易于管理等特性得到了很多系统管理员的喜爱。
目前网上对于 Kerberos 登录原理的描述都过于复杂,其实它的实现非常简单,当你向一个部署了 Kerberos 的应用服务器发起登录请求的时候,服务器会去 /etc/krb5.conf 里描述的 KDC 服务器用 Kerberos 协议发起一个登录请求,如果用户名密码验证通过,将会向服务器发一个票(Ticket),否则将会引出一个错误。然后服务器可以将票发给客户端,以后客户端就可以用这张票进行其它操作。与火车票和电影票一样,Kerberos 的票,也是有使用时间限制的,如果不经过特殊设置,这张票的超时时间大约是 6 个小时。
而在 Django 里使用 Kerberos 登录,有两种办法,一种是由 Django 直接向 KDC 验证密码,另一种是在 Apache 上使用 mod_auth_kerb 模块,由浏览器来处理登录请求。
这两种办法其实都是对 Django Auth Backend 的重载,所有的 Auth Backend 都位于 django/contrib/auth/backends.py 里,这里[2]也有一个使用 Email 来进行验证的范例,我受此启发,写了这两个例子,希望也能抛砖引玉,能给你们更多启发。
第一种 - 由 Django 直接向 KDC 验证密码:
这种办法比较简单,需要在 web server 上装好 python-kerberos 包,并且配置好 /etc/krb5.conf,详细的配置方法,最好咨询 IT 部门,配置成功后在服务器上用 Kerberos 上有的普通用户运行 kinit,如果能够密码验证通过就行。
并且在 Django 的 settings.py 里写入类似下面这行,定义 Kerberos 的 Realm:
# Kerberos settings KRB5_REALM = 'EXAMPLE.COM'
与上面的 Email 验证例子类似的是,我们需要对 authenticate 方法进行重载,加入 kerberos 认证代码,python-kerberos 已经提供了 checkPassword 方法。
try:
auth = kerberos.checkPassword(
username, password, '',
settings.KRB5_REALM
)
except kerberos.BasicAuthError, e:
return None
完整代码如下:
import kerberos
from django.conf import settings
from django.contrib.auth.backends import ModelBackend
from django.contrib.auth.models import User
class KerberosBackend(ModelBackend):
"""
Kerberos authorization backend for TCMS.
Required python-kerberos backend, correct /etc/krb5.conf file,
And correct KRB5_REALM settings in settings.py.
Example in settings.py:
# Kerberos settings
KRB5_REALM = 'EXAMPLE.COM'
"""
def authenticate(self, username=None, password=None):
try:
auth = kerberos.checkPassword(
username, password, '',
settings.KRB5_REALM
)
except kerberos.BasicAuthError, e:
return None
try:
user = User.objects.get(username=username)
except User.DoesNotExist:
user = User.objects.create_user(
username = username,
email = '%s@%s' % (username, settings.KRB5_REALM.lower())
)
user.set_unusable_password()
user.save()
return user
第二种:Apache 上使用 mod_auth_kerb:
这种方法略有复杂,部署它需要向 KDC 申请一个 keytab 文件,以授权该 Web Server 向 KDC 发起请求,并且需要安装和配置 mod_auth_kerb(很简单,后面有),并且 /etc/krb5.conf 一点也不能少。
但是好处也是非常明显的,上面那种依然是使用 Django Auth Contrib 的 Session Manager 来负责登录信息的维持,但是这种方法将能够完全使用 Kerberos 自身提供的 Features,包括登录维持,和 kinit 的支持,也就是说,只要在本机上使用 kinit 成功登录过一次,用 Firefox (目前似乎在 Linux 上只支持该浏览器)访问部署了 mod_auth_kerb 的网站,将都不再需要登录。
它的原理包括两种条件,一种是没有在本机执行 kinit 的,使用 Firefox 直接访问服务器,服务器将会返回一个 401 Authorization Required 错误,这时 Firefox 会弹出对话框询问你的 Kerberos 用户名和密码,并提交你的密码。另一种在本机已经执行过 kinit 的,Firefox 会去读取你客户端的 Kerberos ticket 缓存,如果没有过期的话,就会使用它。无论哪种办法,Firefox 都将在 HTTP Header 里添加一个 'Authorization' 段,并且加入 Basic Authorization 验证方式,例如我本机上的:
Authorization Basic eGt1YW5nOkxvdmVvZnJvYWQuMTIz
使用这种部署方式,在 Django 1.1 版本以下,还没有比较好的解决办法,但好在 Django 1.1 提供了 RemoteUserBackend 后端,依然在 django/contrib/auth/backends.py 路径里,通过阅读它的代码,我们可以看到它其实依然是个 ModelBackend 的继承,而 Django 的 Request Handler 已经默认将 HTTP Meta 里的 REMOTE_USER 段给加入处理范围之内了,因此 RemoteUserBackend 的 ’authenticate‘ 与 ModelBackend 不太一样。 :-)
其实代码都已经写好,我们只需要处理一下拿到用户后的处理办法('configure_user' 方法)和处理用户名的方法('clean_username' 方法)就可以了。
我这里在拿到用户后,出于保护密码的原则,为该用户设置了一个无效密码('user.set_unusable_password()' 方法),并且设置了该用户的 Email。 同时,因为 RemoteUserBackend 默认返回的用户名是 ‘[username]@[KRB5_REALM]',所以我也把后面的 REALM 给去掉,直接贴代码:
from django.conf import settings
from django.contrib.auth.backends import RemoteUserBackend
class ModAuthKerbBackend(RemoteUserBackend):
"""
mod_auth_kerb modules authorization backend for TCMS.
Based on DjangoRemoteUser backend.
Required correct /etc/krb5.conf, /etc/krb5.keytab and
Correct mod_auth_krb5 module settings for apache.
Example apache settings:
# Set a httpd config to protect krb5login page with kerberos.
# You need to have mod_auth_kerb installed to use kerberos auth.
# Httpd config /etc/httpd/conf.d/<project>.conf should look like this:
<Location "/">
SetHandler python-program
PythonHandler django.core.handlers.modpython
SetEnv DJANGO_SETTINGS_MODULE <project>.settings
PythonDebug On
</Location>
<Location "/auth/krb5login">
AuthType Kerberos
AuthName "<project> Kerberos Authentication"
KrbMethodNegotiate on
KrbMethodK5Passwd off
KrbServiceName HTTP
KrbAuthRealms EXAMPLE.COM
Krb5Keytab /etc/httpd/conf/http.<hostname>.keytab
KrbSaveCredentials off
Require valid-user
</Location>
"""
def configure_user(self, user):
"""
Configures a user after creation and returns the updated user.
By default, returns the user unmodified.
Here, the user will changed to a unusable password
and set the email.
"""
user.email = user.username + '@' + settings.KRB5_REALM.lower()
user.set_unusable_password()
user.save()
return user
def clean_username(self, username):
"""
Performs any cleaning on the "username" prior to using it to get or
create the user object. Returns the cleaned username.
For more info, reference clean_username function in
django/auth/backends.py
"""
return username.replace('@' + settings.KRB5_REALM, '')
Django 是一个很强大的框架,虽然缺点和优点都同样的明显,有些甚至是由于 Python 语言或者类库造成的问题,但是因为其使用的便利性,高效的开发,而且其开发小组也非常活跃,使其特性的添加非常频繁,而且网上也有大量资源,例如 Django Snippets 网站,因此依然有着非常巨大优势。而通过阅读它的代码,往往都能获得更多启发。
链接:
写了个监视酷讯火车票的 Python 程序
受不了了,买火车票买不到,只好盯上黄牛票了,可是没法不停地刷页面啊,刚刚就错过了一个发布了 20 分钟的黄牛票,打电话回去时已经打不通了。。。-_-#
就写了个程序来解决这个问题,粘了一堆代码(参考太多,头一次写这种东西,原作者勿怪),总算成了,可能有 bug,欢迎提交 patch 或者更好的解决办法。
可以通过修改下面的参数来修改程序执行:
url = "http://piao.kuxun.cn/beijing-jinggangshan/" # 把火车票的搜索地址粘在这里,这里假设是北京到井冈山的 key = "2张" # 搜索关键字,我得俩人啊。。。 sequence = 60#60 * 5 # 搜索间隔,给服务器压力别太大,每分钟一次就行了。
#!/usr/bin/python
# encoding: utf-8
import urllib2
import mailbox
import time
import os
import re
from sgmllib import SGMLParser
class URLListName(SGMLParser):
is_a=""
name=[]
def start_a(self, attrs):
self.is_a=1
def end_a(self):
self.is_a=""
def handle_data(self, text):
if self.is_a:
self.name.append(text)
url = "http://piao.kuxun.cn/beijing-jinggangshan/"
key = "2张"
sequence = 60#60 * 5
request = urllib2.Request(url)
request.add_header('User-Agent', 'Mozilla/5.0')
opener = urllib2.build_opener()
data = opener.open(request).read()
ticket_name = URLListName()
ticket_name.feed(data)
cache=[]
while 1:
try:
print "beign retrive"
data = opener.open(request).read()
ticket_name.feed(data)
print "beign scan"
for result in ticket_name.name:
if result and result.find(key) >= 0:
if result in cache:
pass
else:
print "found:" + result
cache.append(result)
print "scan finished, begin sleep " + str(sequence) + " seconds."
time.sleep(sequence)
except:
raise
[转] 我们都是海盗党
很好的博客,希望能传播开,大家都能看见,希望封网的上级领导也能看见。
原文在:http://www.mindmeters.com/showlog.asp?log_id=9481
上上周末,我没有到电影院排队去看《三枪》,而是蜗居在家,抱着电脑看《海盗电台》(The Boat That Rocked)。顺便坦白一下,这是未经许可,用电驴非法下载观看的。因为我确定地知道,这种“非主流”的文艺片,是几乎不可能通过广电总局的审查而正规上映的。
影片讲述了一个发生在1966年英国的半真实故事觉。那时,国有的BBC是播放正统古典音乐的重地,每周留给摇滚和流行乐的时间只有2个小时。但与此同时,有一个地下的“海盗电台”(Pirate Radio)却在秘密地7×24小时地播放摇滚和流行歌曲。2500万人(超过英国总人口的一半)都在听这个电台的音乐。这个摇滚的根据地建立在北海的一艘渔船上。一群“有头脑、无信仰”的年轻DJ聚集于此,而他们的头头是一个名叫昆汀的精明商人。他利用听众的狂热支持拉到了许多广告赞助,并且绞尽脑汁来规避政府的管制。
当然,就在这帮DJ在海上过着他们所鼓吹的“音乐、性和大麻”的嬉皮生活之时,充满正义感和责任心的政府已经感到责无旁贷了。他们担心这种没有节制的“靡靡之音”会腐蚀英国的青少年,“就像肮脏的下水沟,夹带着不负责任的商业行为,还有不道德”。
负责管理国家电台的大臣道曼迪早就打算拿这帮法外之徒祭刀,他发誓要在一年之内关闭掉这个海盗电台。领命行事的下层官员于是摩拳擦掌,警告海盗电台的广告客户,甚至不惜化装“潜伏”上船来找出漏洞。
但大英帝国毕竟是一个口口声声讲法治的国家,政府不能随意屏蔽其波段,也没有英勇无畏的城管弟兄帮忙“钓鱼”。既然现有的法律管束不了这帮混球,于是,他们只好创造出一个新的触犯海洋法案来让海盗电台违法(因为他们的电台干扰,“使这个国家中肩挑炸鱼薯片经济的伟大渔业家们,无论男女,生命受到了威胁”),并且成功地在议院获得了通过。
最终,按照官方的报道来理解,“扫黄打非”取得了重大胜利。渔船在逃避执法人员追捕的过程中引擎爆炸而自沉,海盗电台被取缔,DJ们跳海,后被自愿赶来的听众所营救。
根据影片结尾所述,到1967年的夏天,海上电台的黄金时期已经结束。但是,自由的梦想并没有死亡。今天,英国有296个独立电台终日播放摇滚和流行音乐。摇滚文化也浴已经成为今日的主流之一牙。
有关这部电影的一切,我不是在《参考消息》,而是通过像“豆瓣”这样的网站了解到的。我还注意到,豆瓣上有32408位朋友评价了这部电影,除了少数留学海外的同胞,估计他们中的绝大多数和我一样,是通过BTchina、VeryCD、迅雷这样的网站下载观赏。
据说,很快我们也将生活在一个没有“黄色”,没有“盗版”,没有志愿工作的“字幕组”的新时代。假如真是这样,我想我们只能寄希望于自己获得热爱艺术的江青同志赏识,躲在“内部放映室”里批判“资产阶级腐朽生活”。
关于音乐,还有另外一个完全真实的故事。1999年,18岁的大学退学生Shawn Fanning仅用三个月时间创作出了一个改变网络生活的软件。通过结合档案搜索、交换、即时传输等已有的一些技术,人们能够很方便地把音乐从CD转化成MP3格式,并联网进行音乐的交流和分享。很快,他开办了一家以Napster(他上学时的绰号湿头发)命名的互联网公司,提供平台供用户上传、检索和下载音乐作品。
这家公司开创了互联网上免费的潮流,并很快吸引到数千万用户。人们不再购买昂贵的CD唱片,这让几大唱片公司非常愤怒。1999年,国际五大唱片公司起诉Napster,指其涉及侵权歌曲数百万首,要求每支盗版歌曲赔偿10万美元。2000年2月,法院判定Napster败诉。Napster提出上诉,二审依然判其败诉。几经讼战,2002年6月,Napster宣告破产。
尽管Napsrer的商业冒险失败了,但它的创意却激发了更多的后来者。像苹果这样信奉“海盗精神”的公司设计出了更先进的商业模式(出售iPod播放器,在iTunes上销售定价0.99美分的MP3歌曲)。今天,人们享受音乐的成本大大降低了,但音乐工业并没有因此死掉,衰亡的只是CD唱片而已。有才华的艺人也发掘出更多的渠道赚钱(中国的特色发明是彩铃)。
转述这两个故事,其实只想重申以下三点常识:第一,创新就像蓬勃的野草,不会循规蹈矩地生长在规划好的田地里,必然跟现有的环境秩序相冲突;第二,创新会引发一系列新问题,监管者需要慎重考虑是用理性的方式处理,还是用粗暴的手段打压;第三,只要是真正好的创新,不管道路如何曲折,假以时日一定会成为市场新的主流。
格子的世界
今年年初以来,在互联网领域创业的许多朋友开始感觉到一种不好的变化,就像《海盗电台》里DJ听到新法案颁布时的感慨:“我们正站在山的顶峰,朋友再过去就只有下坡了。或许将来会有更好的日子,但我表示怀疑……”
从强制安装“绿坝”到无证视频网站的关闭,从“魔兽”的无法落地到谷歌的失灵,再到饭否、译言、BTchina等众多网站因为“技术故障长期维护中”,以及最近的WAP网站计费暂停,移动广告联盟被禁,未备案网站悉数被关……中国互联网业的生存环境比十年来的任何时候都要严酷。
这实在是一件让人感到杯具的事情。互联网产业或许是中国经济过去10年最大的惊喜,也是最干净最生机勃勃的一个部分。仅仅依靠着本土创业者的汗水和智慧,国际风险资本的投入和国际资本市场的哺育,就创造了一个全球第二大的市场,网络经济的规模逼近1000亿元。
与潜规则、厚黑学和传统智慧所主宰的其它产业不同,中国互联网产业里洋溢的是一种舶来的“海盗精神”:冒险进取、无拘无束、颠覆传统、破环现有的游戏规则、抢夺既得利益者……正是这种海盗精神成就了美国的微软、苹果、Amazon、Google、Facebook、Twitter, 也成就了中国的腾讯、阿里巴巴、百度、盛大、携程、新浪等等。
因为工作关系,我结识了这些被关网站的一些创业者,在我看来,他们是一帮极其简单善良,充满了理想主义情怀的年轻人。他们主观上和客观上都没有破坏和谐社会与腐蚀青少年的意识行为。
但或许是因为已经有超过3亿的网民、突破7亿的手机用户,或许是技术的洪流冲垮了一道道行业篱笆,让我们的政府深感责任重大,“看得见的手”要取代“看不见的手”。十年前,只有一个信息产业部是真正管理互联网的,今天,工信部、文化部、广电总局、新闻出版署、公安部、商务部、中宣部、国新办等N多个部门都有权力去干预。
我不明白,这究竟是一种进步,还是一种倒退? 中国互联网过去10年的成功,某种意义是一种“无政府主义”的成功,是“自由市场”的胜利。但我们正在做的事情,却是在把一张原本平坦的互联网世界,人为地划分成一个个的“格子世界”?而且进入每一个格子,都需要一张通行证。
当然,我们可以相信政府官员们这样做是出于充分的理由。“扫黄打非、保护知识产权、斩断色情产业链、保护未成年人“等任何一面旗帜的举起都是为了维护公众利益。而且我们的官员们也习惯了”家长、保姆和导师”等多重角色的扮演。
但是,为了维护所谓的公众利益,我们是不是就一定要开动强大的行政机器,是不是因为有个别小孩违规喝了啤酒就把所有的酒吧关掉呢?
坦白说,互联网需要的是管理而不是管制。创新的好坏应该交由市场来评判,市场评判不了的,交由法律来裁决。
在一个成熟的法制国家,政府或者其他公司首先看你的创新有没有侵权违法,然后可以上法院告你,申请强制执行,在宣判之前,你还有机会要求第三方的“听证”,即使输掉了,你还有上诉权。除非你像Napster一样官司彻底输了,你在商业上就死了,但在中国,你的网站突然死亡了,你连被谁拔掉网线的都未必知道,因为有权封你的衙门很多,更不要说找地方讲理。
“如果宪法第一修正案保护像我这样的人,我相信它能保护所有人,因为我是最下贱的人渣。”这是美国传记电影《性书大亨》中色情杂志大亨拉里弗林特的名言。
在我们这,爱流眼泪的温总理也一再强调“法治天下”。他还做出过具体的阐述:第一,宪法和法律的尊严高于一切。第二,在法律面前人人平等。第三,一切组织和机构都要在宪法和法律的范围内活动。
但实际上,我们推行的是“德行天下”。谁拥有道德裁判权呢?是“以德服人”的政府官员。按照卡尔马克思的理论,“每个社会的道德体系完全是其生产方式和阶级结构的产物。统治阶级的利益将成为社会的占优势的道德体系。”
海盗的梦
性产业是人类历史上最古老的产业,即使有一天.com消亡了我相信性产业也不会消亡。互联网和手机仅仅只是提供了一个更加廉价和方便的信息传播和沟通渠道,但即使斩断了这两条通路,你认为就能在中华大地上解决这个问题吗?有本事把东莞给平了,看看广东的GDP会不会下来?
至于知识产权保护。它作为一项法律制度存在,归根结底是一种多方利益平衡机制。今天,所谓的知识产权保护已经变成一种商业武器,被财大气粗的大公司用来对付狡猾的“海盗”。但即使在欧美,传统的知识产权体系也已经被互联网冲击得摇摇欲坠,因为获益的是大公司,而非真正的创造者和需求者。
正如诺贝尔经济学奖获得者斯蒂格利茨所说的,“知识只有通过共享才能有更多的公众价值,因此限制知识的传播必然会使整体社会运行效率低下。所以有效的知识产权制度不应影响到知识的使用和传播。如果单独一方或者局部利益团体对知识使用拥有绝对的权力,这就人为地增加了垄断,垄断因素又扭曲了社会资源的分配,并最终抑制更多的创新”。
从Linux开始,以BT、山寨为高潮,“海盗”式的创新打破了原有的利益平衡,全世界的商业力量都在通过协商,争吵、角力甚至一轮轮诉讼来寻求新的平衡。旧的法律已经不适应时代发展,我们应该寻求一个更优的法律解决方案。
但这个方案绝对不是一个“办证”的方案。现实已经给我们揭示了这样的一种可能:当越来越多的主管机关对互联网实施越来越严格的审批制度或许可证制度时,风险资本必然流向拥有资源和后台的一方,胡雪岩式的智慧也会压倒苹果的“长尾”谷歌的“免费”,而最终被扼制的就是创新活力。
于是,当国外的大公司争先恐后地打造出大平台来吸引更多的创业者时,中移动、央视这样的“正规军”们却在用暂停WAP收费,收编暴风影音这样“堂而皇之”的方式来挤压创业者的生存空间。
更危险的还在于,“每一个民企被限入的领域,都是民企和全体国民被迫向特殊利益集团输送利益的管道(吴敬链语)。”只要权力配置资源的格局不改变,单纯的创业者要么出局,要么就得像黄光裕那样选择买通权力,为自己获得某种不对称的特权,同时向权力所有者输送利益。到那时候,中国的互联网业就会像房地产业一样开始堕落。
今天,互联网还只是刚刚度过它的幼儿期,未来的成长不可限量。但我们对待互联网的态度,其实可以折射出我们对待创新的态度。
如果我们真的想要成为一个“自主创新”的伟大国家,那么政府就应该真正理解“自主创新”的涵义:每个人每个机构都可以成为创新的主体,创新的思想可以自由的交流,创新的成果可以无障碍地传播。换句话说,创新的前提恰恰是思想的真正解放。
反之,如果我们真的把无国界的互联网变成局域网,如果必须官员们点头才能决定什么人有权搞创新和什么是好的创新,如果只有中科院、中移动、中国联通、CCTV这样的“三好学生”才有资格去实现创新,那么,这样的“自主创新”恐怕“只是一个传说”。
我希望自己能成为“海盗党”的一员。在巨人与大卫之间,站在大卫这边;在庙堂与江湖之间,站在江湖这边;在新思想与旧道德之间,站在新的这边;在天理与人欲之间,站在人欲这边;在权威与叛逆之间,站在叛逆这边;在和谐与变革之间,站在Change这边……
有些时候,我必须承认,自己会对所处的这个社会感到失望,但因为身边总有不放弃希望的朋友,总能看到排除万难的创业者一再被打倒又一再爬起来,所以我们也不会因为失望而选择绝望。
就像在电影《海盗电台》里,最后沉船时,DJ“伯爵”对着话筒喊出的话:“时光匆匆流逝,政治家们会用尽手段让世界变得更美好,但世上的青年男女会继续做梦,把梦编织成歌曲……今晚值得悲伤的是,在未来会有很多很棒的歌,然而我们没有机会去播放了。但相信你我,好歌会继续写下去,它们会在世界各地被欢唱……”
Google Wave 使用体验
Google Wave 拿到有些日子了,写写这两天对它的感觉。
这东西到底是什么?团队协作平台?Email 接替者?Wiki?BBS?它给我的感觉什么都不是,而是展示 Google 网页开发实力,和最新 Web 开发技术的一个测试产品,也有可能是因为它目前的不完善导致定位不明确吧。
打开 Wave 之后,就会看到浏览器的加载小滚轮一刻不停地滚动着,因为它需要时刻不断地连接到服务器上,获取好友以及消息的信息,在 Wave 的演示视频上我们可以看到,当 Contacts 在某个”波“里打的字,会即时显示在页面上。这是 Google 强大云计算的佐证。
奇异的滚动条,有点像 Aperture 里的风格,颠覆了传统滚动条的概念,点击直接贴伏在 Bar 上地向上按钮的时候,页面会轻轻地向上地滚动一点点,但是将 Bar 直接向下拖到底,页面不是跟着滚动着到底,而是会像开了”平滑滚动“似地划过浏览器。加上所有可以随意伸缩、最小化的面板。这是最新 Web 开发技术的佐证,而这其中有 Google 很大的功劳。
不过我依然觉得它定位不明确,缺乏 BBS 的公开,Wiki 的开放,Email 的便于查询,团队协作平台的目标性
一个 Wave 就是一个话题,用空格键在所有未读的回复间切换,对于不感兴趣的 Wave 可以 Archive 掉。用户可以很轻易地上传各种文档到自己的 Wave 中(拖拽上传对 Safari 似乎无效)。超酷的操作方式似乎才是 Wave 的全部。
我倒希望它能在未来的版本中进一步完善。
有账号的可以加我 Wave - xuqingkuang # googlewave.com
十月总结
到月末了,对这两个月做一下总结。
首先是 VirtLAB,这个从三月开始的自动化测试项目,该项目用于在 QE 团队内部替代 RHTS,由于是重新设计的 Database schema,所以我可以充分发挥 Django 自身的优势,也是因为通过 VirtLAB,使我的 Django 水平得到了极大提高,同时由于 UI 前端是自己编写的,所以对 Javascript 也远远胜过之前。现在无论是 Django 本身的 ORM,Template,Form 都很难难到我了,自定义 ORM model field、Form 的 RequestContext Processor,Field 和 Template 的 Tag、Filter 也都得心应手。
在这两个月里,VirtLAB 发展到了 2.0,主要是增加了 Queue,用于在一台机器上建立一个 Job 队列,可以同时在一台机器上排上多个 Job,一个一个重启电脑,重装系统后执行测试脚本的特性;另一个就是晚上趁着没人的时候,自动根据数据库覆盖率(在哪些机器上运行过),跑测试的功能,所以界面也换成了夜间的风格。
新版本极大地提高了自动化功能,由测试人员编写好测试脚本,白天可以由测试人员自己提交 Job 在不同的机器上执行并实时观测运行过程,晚上下班后程序也会将那些在一些机器上没有跑过的测试执行一遍,最终做到每一个测试脚本在所有的机器上都执行一遍,以检查系统是否能够在不同类型的机器上稳定运行。
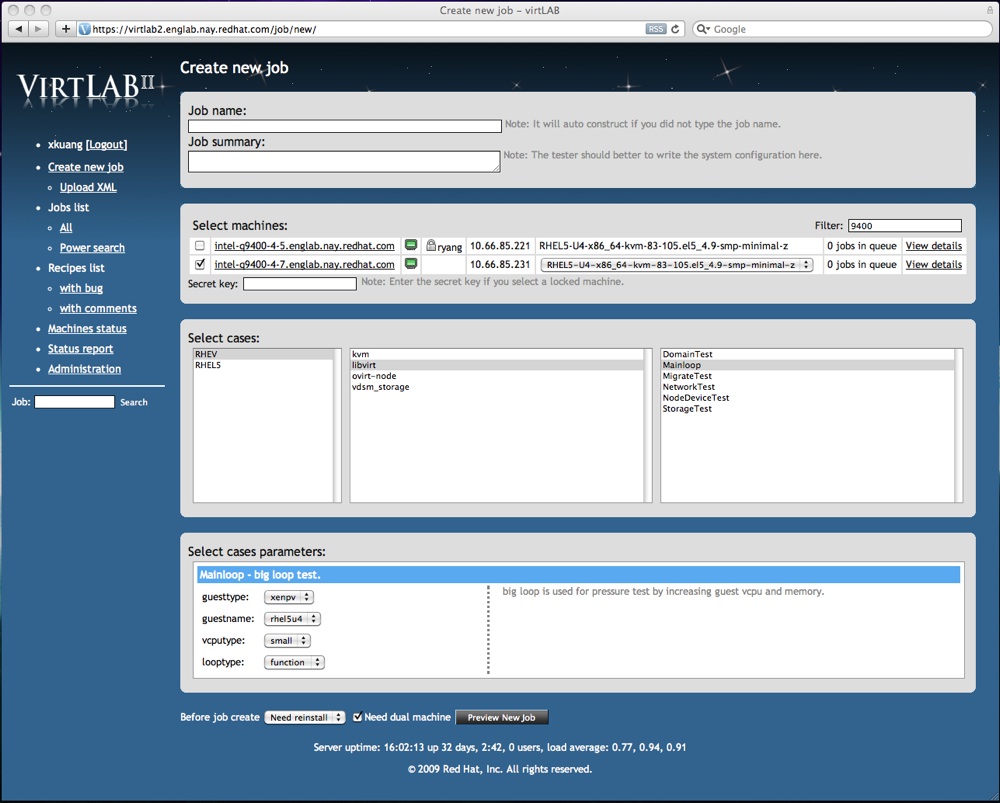
另一个是用于手动测试的 TCMS(与 Testopia database schema 完全兼容的 Test Case Management System),半年前将它撂下,现在又重新捡起来了,经过 VirtLAB 的磨砺,而且新版本里可以加表,所以我对这个代码进行了重构,使用了大量 Django 自身的特性,比如 ACL 和自带的 Admin Page。和 VirtLAB 一样,使用了 python-kerberos 做了个 Kerberos 的用户名密码验证。因为 Testopia 的数据表结构比较复杂,所以对整个 Models 进行了重构,用 ForeignKey 和 ManyToManyField 重新进行了组织,自行编写了 TimeAsTimeDeltaField 来处理 Test Case 的 Estimated Time。
UI 也经过丹青的重新设计,变得更加的方便、易用。
总之,是个脱胎换骨的版本。
明天,30 号就是正式内部使用的日子,svn 的版本号也相当吉利 2046。我们将正式用它来代替服役了很长时间的 Test Runner 和根本不成熟且有版权问题的 Testopia。
下一步计划 - 更加地自动化:
VirtLAB 将对每台机器加上 Tag,以后选机器不用去看主机名了,只要选好自己需要的配制,比如要 Intel 的处理器啊,要超过 4G 内存啊,就可以自动根据所选条件,自动选择空闲的机器,最快速地完成需要完成的 Job。
TCMS 将进一步对代码进行重构,进一步 Django app 化,同时完成 Report,以及和外部程序沟通的功能,目前只能将 Failed 的 Case 用 File a bug 链接直接提交到 Bugzilla 上,下一步将和 VirtLAB 和 ATP 整合,直接在 TCMS 里操作 VirtLAB 里的测试脚本。
BTW: 前一端时间公司内部开始使用 Redmine 进行内部项目管理,这个用 Rails 编写的工具确实有很多独到的特性,可以看看。
搞定梦幻手机 - Palm Pre

Palm Pre 是继 iPhone 之后唯一一个让我心动的手机,Android 虽然也让我感到很兴奋,但是因为它缺乏中心设计,也没有什么特别的创意,对它始终缺乏购买的欲望。
但是 Palm Pre 基于 Linux,全新的卡片式操作系统,实体键盘,手势操作,对云(主要是 Google)的全面支持,以及对苹果 iTunes 的支持,非常方便而且跨平台的 SDK,让我实在不能不趁着现在低价(2000+)赶紧入手一台。
大概就是这样了,办下天翼手机卡,找人去电信机房查号,刷 1.0.3 激活手机并写入 MEID/ESN,升级 1.1 写入 AKEY/HOME SID/NID 搞定童话,写入 AN/AAA 搞定 EVDO。
现在有 qinray 的 1.1 ROM,刷机写号更方便了,而且不用担心激活的问题了,但是写入 MEID/ESN 这步最好还是在 1.0.x 里做,因为 1.1 里的地址有所变化,反正我是写入后无效,重启后会自动复原。
Treo8 是个很好的 Palm 论坛,如果有兴趣可以去看一下:http://www.treo8.com/bbs/forum-33-1.html
现在还缺好用的中文输入法,无法发中文短信,但这都不是问题,因为"LInux 无限可能"。
root@castle: /var/home/root # uname -a Linux castle 2.6.24-palm-joplin-3430 #1 175.1.23 armv71 unknown
机器终于 Crash 了。。。
用苹果本子五年,头一次看见四国,兴奋ing。。。
我的主要工作是给公司内部写自动化测试工具,当然是使用 Django,这个 Web framework 越用越好用是我和我的设计师的共识。
工作配置主要是浏览器 Safari + Firefox,不过感觉还是 Webkit 比 Firefox 某种程度对开发者更加易用一些,比如 Firefox 的 form 是不能嵌在表格内部的,Safari 则可以。其它还有很多,比如 Safari 对 HTML/CSS 扩展比 Firefox 更加实用和简易,Javascript 执行速度也更快。
编辑器是 TextMate + MacVIM,TextMate 主要负责多文件的编辑,用起来还是很舒服的,MacVIM 主要是不想用鼠标的时候,全心写代码的时候用,主要用了 http://code.google.com/p/yy-vimscript/ VIM plugin 和 snippets,用 SynergyKM 共享了台式机的键盘鼠标用。
操作系统是 Snow Leopard 10.6 10A421a,我已经将它用于生产系统,系统平时还是非常稳定的,平时开一个礼拜也没问题(只待机),这次崩得很没头脑。-_-#
最新的苹果系统性能的确有极大提高,从前一篇 nbench 测试贴也能看出来,全部自带的应用程序都是 64bits,完全抛弃了 ppc 代码,体积也更小。完全重写的 Finder 打开和预览文件的性能也比之前版本高出很多,尤其是 Quake 3(32bits) 在我的本子上标准画质从 227fps 猛增到 540fps。现在就等着其它软件厂商推出64bits 的应用软件了,我目前只有 Tweetie 和 Perian 是 64 位的,其它的还是 32 位的。试着去编译过一些自由软件,但是编译始终在变量类型上会出问题,或者更加难缠的链接错误。这一版本承诺的功能也基本都已完成,不过 ZFS 去哪儿了?!-_-#
OS X 在界面上始终保持一致性和继承性,新的系统多是在细节上进行优化,而极少去颠覆之前的设计,我在设计思想上是非常赞同这一观点的。
跑题,打住。。。
又加了三台电脑的 nbench 测试成绩
这次把自己的笔记本和台式机,还有一台虚拟机服务器都跑了一下,得到了以下结果。
其中我的笔记本,Macbook Pro (2008 Early),内置了 Intel Core 2 Duo T8300 的处理器,得到测试冠军,工作站 HP XW4600 虽然使用的处理器是 2.5Ghz E7200 的,但是比起 2.4GHz 的 T8300,性能还是有一定差距的。所以不要迷信 Intel 处理器的主频,真的有差别。
跑自己的服务器纯粹是因为我的 Web server 在上面反应真的比较慢,所以跑了一下,那个 Xen 的版本比较老了,还是 3.0.x 的,新版本能够支持 Intel VT 和 AMD-V 技术,相信性能会好不少,因为是处理器直接支持虚拟化的,只是我手头暂时没有机器测试,RHEL 5.4 里将要内置的 KVM 也很值得期待。
| Macbook Pro(T8300) | Mac OS X 10.6.0 Beta1 | 20.190 | 37.898 | 22.963 |
| HP XW4600(E7200) | Fedora 11 | 17.013 | 36.669 | 16.797 |
| RHEL in Xen(AMD 8356) | RHEL 5.3 Running in Xen | 11.694 | 14.412 | 9.201 |
详情请到 http://xuqingkuang.is-programmer.com/2006/10/10/nbench.6107.html 查看,测试的详细日志那里都有。
Rate My Life Quiz!
| This Is My Life, Rated | |
| Life: | |
| Mind: | |
| Body: | |
| Spirit: | |
| Friends/Family: | |
| Love: | |
| Finance: | |
| Take the Rate My Life Quiz | |
刚看到 TualatriX 上 Rate My Life Quiz 的链接,顺道也给自己做了下测试,结果还行,除了 Friends/Family 以外都还可以。
很奇怪我的 Body 指数居然是最高的,难道是因为没什么不良嗜好而且保持了良好睡眠?!不过北京的气候真的让人感觉很不舒服,在“你是否生活在一个有污染的环境中”的选项上,我毫不犹豫地打了一个勾,要没它估计就 10 分满分了。。。
Friends/Family 和 Love 虽然是最低,可能因为我已经有了稳定关系了,而且比较恋家,所以还是相对地高的~(^_^)
Finance 项现在在开源节流,还是颇有成效的,每个月还能有少许赢余,要点是买东西之前好好想想那个东西是否真的对你的生活有促进作用,而不仅仅是一时冲动或者 Hobby,家里有个财务顾问还是很不错的。 ^o^
别的人的测试地址在下面,请允许我把你们的地址贴出来:
Contrast: http://contrast.yo2.cn/archives/41840
TualatriX: http://imtx.cn/archives/1282.html
在 Fedora 上安装并使用 Chromium
Chromium 官方只提供了 for 乌班兔的 deb 包,好在从 Solidot 上看到已经有好心人在 Fedora 上也编译了一份,经过试验运行起来没有问题,功能也已经比较完备了,可以满足最基本使用需求,速度却比 Firefox 要快了很多,基于对 Webkit 的好感,以后它就是我的主力浏览器了(这话前两天好像刚说过 :-p)。
我也写了个的 repo 文件,以便于用 yum 升级,内容很简单,把下面内容以文件名 chromium.repo 存放到 /etc/yum.repos.d 里就好了:
如果想偷一把小懒的话,也可以去 http://www.box.net/shared/rbyeny0bge 里下载,并放到 /etc/yum.repos.d,不过 box.net 好像被墙了,可能需要翻墙。。。
然后在终端里运行 # yum install chromium,就可以了
Opera 10 Beta 1 running on Fedora 10
刚刚试了一下 Opera 10 beta 1,深深被这个界面漂亮,性能出色的浏览器吸引了,以后它就是我的主力浏览器了。
虽然之前也用过早期版本的 Opera,但是一直觉得 Opera 的界面太过于复杂,菜单太长,而且 Javascript 解释有问题,所以一直只是装完了试试就删除了。
今天装版本 10 beta 1,菜单被极度精简化了,设置选项也简单很多,简单设置一下,字体也变得和 Firefox 一样优秀,只是虽然通过了 ACID 3 测试,但是 Javascript 在 Flickr 的的上传页面依然除了些不兼容的现象 - 选择文件对话框无法打开。
不过依然是个出色的浏览器。
关于字体的设置,其实很简单,编译一下 /usr/share/opera/defaults/font.ini,禁用掉 X Core Fonts 支持:
; One can disable xft or core fonts if necessary
;engine:xft=blacklist
engine:x11=blacklist
;engine:xft=blacklist
engine:x11=blacklist
并且把对应语言的中文字体改掉,我这里是文泉驿的微米黑:
; Known fonts that solves specific problems
; family:mincho|gothic=japanese good try-first
; family:kochi*=japanese good try-first
family:WenQuanYi Micro Hei|WenQuanYi Micro Hei Mono*=chinese-s try-first
; family:baekmuk*=korean good try-first
; family:mincho|gothic=japanese good try-first
; family:kochi*=japanese good try-first
family:WenQuanYi Micro Hei|WenQuanYi Micro Hei Mono*=chinese-s try-first
; family:baekmuk*=korean good try-first
OK, enjoy your opera,我要去折腾我的 ibus 光标跟随了,希望能有 sci-qtimm 之类的 ibus 模块。
最后差点忘了要说一句:RnVja0dGV++8jOiuqeS9oOW7uuaIkOWFqOS4lueVjOacgOWkp+eahOWxgOWfn+e9kQo=
图片需要翻墙。
让闲着没事干的机器去算外星人去。
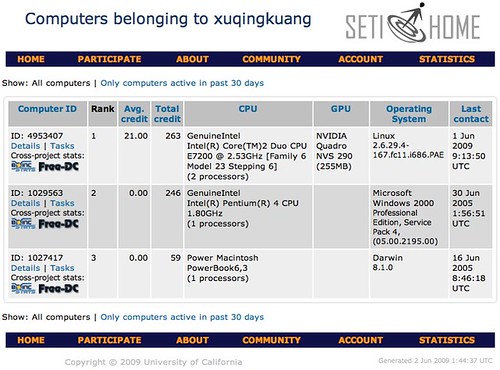
办公室有闲电脑?拿来算外星人吧。
前一段时间 SETI@Home 项目组又发了好几封邮件,需要更多计算力量和赞助来处理大量的数据(有说是共有 15T,有说是每天 10G,一年300G ?! -_-#)。
装上服务器的 Linux(其它平台也可以),装上 Boinc,就让它自己跑吧,有 NVIDIA 显卡的可以开启 CUDA,确实可以提高运算速度。
详情可以参考:
http://zh.wikipedia.org/wiki/SETI
也有更多项目等待你的参与:
寻找引力波的 Einstein@Home: http://einstein.phys.uwm.edu/
了解了解蛋白质折叠的 Folding@home: http://folding.stanford.edu/
BTW: 现在电脑的性能确实突飞猛进,几天算的相当我之前一个月的运算量了。
端午节快乐!
端午节快乐!
今天公司人事发信,我这才知道端午节在国外叫 Dragon Boat Day,确实很贴切啊,龙舟节,所以 Happy Dragon Boat Day! :-)
BTW: is-programmer.com 的服务一直很稳定,得多谢 galeki。
多吃粽子。
简单办法搞定 Linux 上蓝牙和 USB 线 GPRS 拨号上网。
移动 TD-SCDMA 测试用的话费积攒到了 4000 多元了,女朋友消化得实在太慢,怎么办呢。
刚好趁着外出,把测试的 3G USIM 卡插上 Nokia E71(因为附送的熊猫山寨机太差了。。。-_-#),拿来给笔记本 GPRS 无线上网。
首先安装好 pppd 和 wvdial,把手机的 USB 连接模式改成 PC Suite,这样才能把手机当猫用,如果使用 Connect PC to Web 的话,屏幕上会出现 Nokia Connect to Internet 的盘符。
然后在 /etc/wvdial.conf 里写下如下代码,不用对 cmnet 接入点做特别设置,直接就会连接好了。
[Dialer nokia-usb]
Modem = /dev/ttyACM0
Baud = 3600000
Init1 = ATZ
Init2 = ATQ0 V1 E1 S0=0 &C1 &D2
Init3 =
Modem Type = USB Modem
Area Code =
Phone = *99#
Username = ppp
Password = ppp
Ask Password = 0
Dial Command = ATDT
Stupid Mode = 1
Compuserve = 0
Force Address =
Idle Seconds = 0
DialMessage1 =
DialMessage2 =
ISDN = 0
Auto DNS = 1
New PPPD = yes
[Dialer nokia-bluetooth]
Modem = /dev/rfcomm0
Baud = 3600000
Init1 = ATZ
Init2 = ATQ0 V1 E1 S0=0 &C1 &D2
Init3 =
Area Code =
Phone = *99#
Username = ppp
Password = ppp
Ask Password = 0
Dial Command = ATDT
Stupid Mode = 1
Compuserve = 0
Force Address =
Idle Seconds = 0
DialMessage1 =
DialMessage2 =
ISDN = 0
Auto DNS = 1
New PPPD = yes
Modem = /dev/ttyACM0
Baud = 3600000
Init1 = ATZ
Init2 = ATQ0 V1 E1 S0=0 &C1 &D2
Init3 =
Modem Type = USB Modem
Area Code =
Phone = *99#
Username = ppp
Password = ppp
Ask Password = 0
Dial Command = ATDT
Stupid Mode = 1
Compuserve = 0
Force Address =
Idle Seconds = 0
DialMessage1 =
DialMessage2 =
ISDN = 0
Auto DNS = 1
New PPPD = yes
[Dialer nokia-bluetooth]
Modem = /dev/rfcomm0
Baud = 3600000
Init1 = ATZ
Init2 = ATQ0 V1 E1 S0=0 &C1 &D2
Init3 =
Area Code =
Phone = *99#
Username = ppp
Password = ppp
Ask Password = 0
Dial Command = ATDT
Stupid Mode = 1
Compuserve = 0
Force Address =
Idle Seconds = 0
DialMessage1 =
DialMessage2 =
ISDN = 0
Auto DNS = 1
New PPPD = yes
写好后用 root 运行:
wvdial nokia-usb
应该就可以上网了。
如果要用蓝牙的话,需要先安装 bluez,建立 /dev/rfcomm0 设备,我是在 Fedora 10 上测试的,很奇怪改好 /etc/bluetooth/rfcomm.conf 后,重启蓝牙服务无效,所以还是手工绑定那个设备吧。
用下面命令绑定设别:
rfcomm 0 (Bluetooth MAC Address) (Internet Dialer Channel)
如果不知道蓝牙的 MAC 地址的话,可以用下面命令进行搜索。
hcitool scan
如果不知道 Internet Dialer Channel 的话,可以用下面命令查找:
sdptool search DUN
然后再执行上面的 rfcomm 命令,然后用下面命令拨号。
wvdial nokia-bluetooth
方法应该说比较简单了,Enjoy your wireless life 吧 :-)
在网上交易的不是商品,而是信誉
最近这两天恰逢315,电视上的消费者维权节目颇多,网上关于消费者维权,尤其是网上消费维权的新闻和消息也很多。其中,淘宝作为国内最大的网上购物场所,被推到了风头浪尖。其实,我相信,只要按照淘宝的流程走,在淘宝上购买商品,是非常安全的。
今天,恰好我的头一次交易纠纷被解决了,事情如我所愿,所有货款连带邮费完全退给了我,从这件事情上,我更加信任淘宝作为国内 B2C 老大的公信力。
上个月末,想为沉睡已久的 iPod 买根数据线,但是我的 iPod 是 3 代黑白屏,必须通过 Firewire(1394) 充电和同步数据,于是在网上搜索,因为担心外地交易出问题,购买实物我一直只买本地商家的商品,问过多家店铺,但找寻未果,后来问到一家店铺,店主说可以与 iPod 同步,但价格异常便宜,只要 15 元,心想应该不是原厂的,但只要能同步数据,就豁出去了吧,于是拍下,只是邮费上有所问题,商家需要 12 元快递费,但在网上交易多次的我深知本地快递一般 5 块即可,于是让商家修改邮费,但商家只克扣了 5 元邮费,依然需要 7 元,想想算了,只要能同步数据就行,于是支付了 22 元。
第二天中午收到线,包装还可以,很小的线拿了很大的 2.5 寸硬盘盒的盒子包装,但拿出来一看,线明显不是全新,和商家描述有出入,插上 iPod,开始充电了,心里一阵激动,可是却没有启动 iTunes,启动完成之后我手工启动了 iTunes 发现没有 iPod,用 dmesg 查看内核信息,就好像 Firewire 上没有插入任何设备一样,没有任何提示,插拔试了几次,皆是如此。
于是打电话给商家要求退货,好在商家离我不远,趁着午饭时间中午就去了一趟,说明事由之后,询问店主是否还有别的线可以使用,店主回答没有,我说那我只好退货了,然后店主从钱包里拿出 15 元,扔在桌上,说只退货物的费用,运费不退,我据理力争,但店主依然不退运费,我一气之下把线和包装盒扔在店主柜台上,直接回到公司,用电脑在支付宝上申请了全额退款,经过近一个月的周折,商家期间在超时之前点击拒绝退款,最终依然到了由淘宝来判决货款走向的地步。
很高兴,支付宝依然是偏向于消费者的,下面是在支付宝上举证和留言的截图:
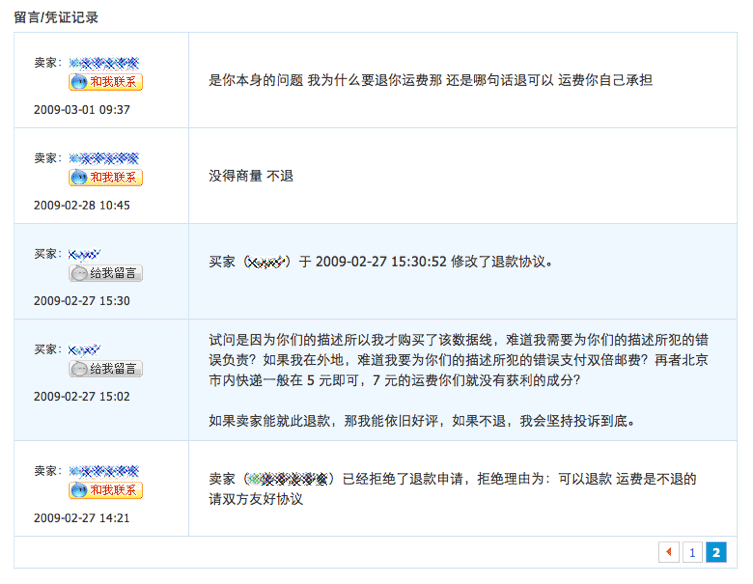
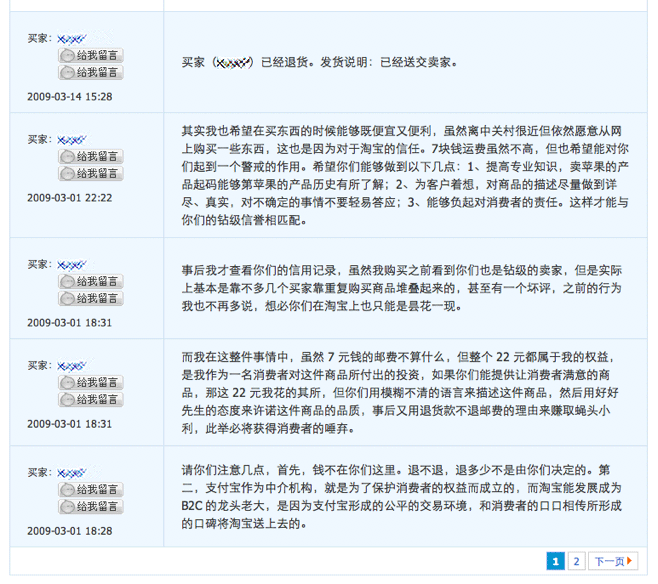
而得偿所愿的结果:
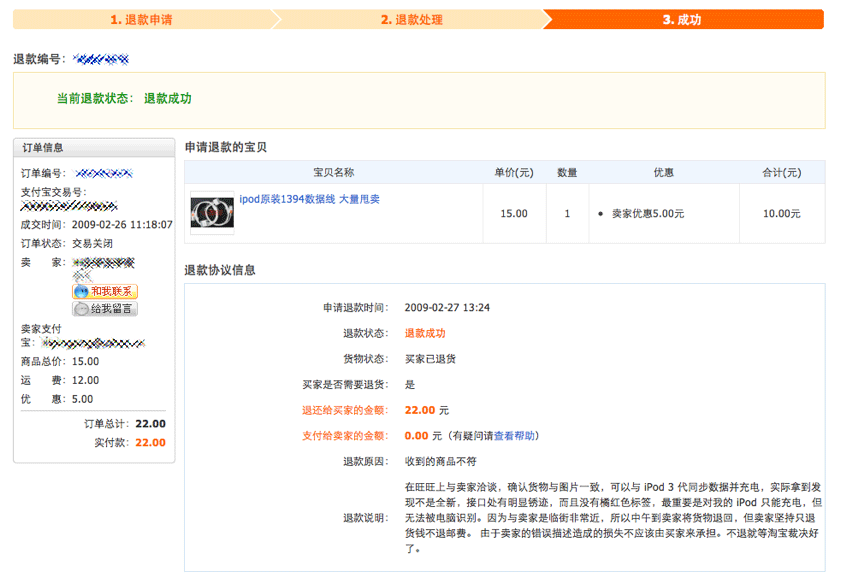
22 元的线真的不算什么,7 块钱的运费也不算什么,但是一分一毫都不去争取,当自己更大的利益收到侵害的时候,如何能拿得出争取的勇气?
所以我相信,自己的权益,是可以争取回来的。
然后,我想说下在淘宝上购买商品的流程,和注意事项:
- 自然是寻找自己需要的商品
- 找到商品后点击旺旺图标,联系商家,咨询商品情况,一定要问得非常非常详细,因为事后判定责任方的就在购买前咨询那段,如果让商家落下口实拒不退款,那支付宝也保不了你。常用的问题包括:“多长时间能到啊,物品和图片是否一致啊,我想要的功能是否都有啊,等等。。。”。我现在意识到电脑版的旺旺比网页版的旺旺更加重要,因为电脑版的旺旺有举证功能,我买这根线的时候因为只有 Mac 机,所以用的是网页版旺旺,好在所有的证据都指向我这里有利,商家也不敢举证。所以,旺旺咨询阶段非常重要。
- 谈后之后,确认购买了,拍下之后付款,付款方式一定要选支付宝,所以开一个支付宝帐号也是必须的,即使麻烦一点。如果商家让你单独给他的帐号上汇款,那哪怕换一个商家也不要从他那里买,一般让直接汇款的人都是骗子,钱要是打过去了,基本就不用指望货物或者钱还能回来了,所以,支付宝是所有保障工作中的核心中的核心,必不可少。
- 在支付宝支付后,物品状态会变成“买家已付款,等待卖家发货”,卖家发货后,就是等待你确认收货了,收到货物以后,第一件事情是必须仔细检查货物的外观是否完好,如果外观有问题可能是快递公司的问题,也有可能是商家那里的问题,所以不要签收,退了,让商家再寄一份,如果商家要求加邮费,除非那东西对你比较重要,而且别处买不到,否则就退钱。签收后要检查所有功能是否完好,如果功能正常,其实如果商家不着急的话,那还是可以先用两天,确定没问题了,再去确认的,如果确认没问题了,确认之后,那就到此,不用再往下看了,如果有问题,请继续读下去。
- 如果发生问题,得和商家联系了,最好是通过旺旺,电话或者手机也可,如果商家离你不是很远,建议还是花点时间亲自去一趟,虽然这会花费一些时间,但是买东西碰到假货的机率毕竟比买到真的少很多,和商家商量一下解决办法,比如换货,退货只有到万不得已再可以使用,因为确实很伤和气,俗话说闷声发大财嘛,退款的时候要注意,如果是因为你的原因造成的问题,那可能邮费和中间发生的其它费用就得由你来承担的,谁让你一开始不说清楚,如果是商家发生的问题,尤其是对商品的描述问题,那承担责任的就非他莫属了,坚决退款,连邮费乱七八糟其它费用一起退,其实连误工车费的也可以报,确实以前有人这么干过,不过那太废周折,咱折腾不起,把属于自己的那份拿回来就行了。
- 然后就是上淘宝上退款了,退款流程是这样的:
- 首先是你申请退款,发起退款协议,如果商家不同意退款协议,则需要你修改协议,这时你一定要坚持立场,提交证据(留言限制 200 字),但是如果不是你出的问题,那绝对要寸步不让,可以在协议里加几句话,但是退款金额不变,提交之后又是商家确认是否同意新协议,这可能会有几个来回,但是每次提交后都会进入为期十天的超时期,所以要经常关注自己的退款流程,因为退款不会给你写信、或者旺旺上提醒你,超过十天后,如果商家没有任何反应,那会视他同意退款协议,进入你的退货阶段,这时你已经将货物快递或者亲自送到商家手里,如果已经送回,则可以直接确认,则又进入商家确认收货阶段,超时期依然是十天,这时商家仍然有机会驳回你的退款协议的,但驳回后你再次修改协议后,商家如果再次驳回,则没有超时期了,这时可以去帮助页面里给淘宝留一个言,说明你的情况,把交易号,退款页面地址都写清楚,这里限制 1000 字,说明你与商家已经没有继续协商下去的可能。淘宝会在 48 小时内给你的邮箱发一封信,说明支付宝的工作人员会在 30 天内处理交易纠纷,让你注意超时。
- 进入到这个阶段,就可以静静地等待了,支付宝工作人员如他们所说,会在一个月内处理你的纠纷,这包括了超时期,如果证据指向你无错,那购买商品的金额最终还会回到你的手里。
最后祝所有的朋友都能淘到自己喜欢的商品,少受点退款的折腾,也希望所有的商家能向我给卖给我线的那位商家中的留言一样:
- 提高专业知识,对自己所销售的商品有足够的了解。
- 为客户着想,对商品的描述尽量做到详尽、真实,对不确定的事情不要轻易答应;
- 能够负起对消费者的责任。
Python 技巧:@classmethod 修饰符
通常情况下,如果我们要使用一个类的方法,那我们只能将一个类实体化成一个对象,进而调用对象使用方法。
比如:
class Hello(object):
def __init__:
...
def print_hello(self):
print "Hello"
def __init__:
...
def print_hello(self):
print "Hello"
要用 print_hello() 就得:
hlo = Hello()
hlo.print_hello()
Hello
hlo.print_hello()
Hello
如果用了 @classmethod 就简单了。
[转帖] Python 中 switch 的解决办法
其他语言中,switch语句大概是这样的
switch (var)
{
case value1: do_some_stuff1();
case value2: do_some_stuff2();
…
case valueN: do_some_stuffN();
default: do_default_stuff();
}
{
case value1: do_some_stuff1();
case value2: do_some_stuff2();
…
case valueN: do_some_stuffN();
default: do_default_stuff();
}
而python本身没有switch语句,解决方法有以下3种:
Spotify - 超好用的音乐共享软件
从 CNBeta 的新闻上看有 Spotify 这款音乐共享软件,据说是 uTorrent 的创始人 Ludvig Strigeus 写的,Down 下来了一份,试了一下,果然不同凡响。
延时很短(几乎没有),而且都是很新的金曲,最关键的是曲子都很好听!
下载链接在: www.spotify.com/en/download/
目前只支持 Windows 和 Mac,如果想在 Linux 上用,可以使用 wine,这里有篇 Guide:
www.spotify.com/en/help/faq/wine/
=========================================================
我这里只对如何注册说一下,现在 Spotify 对英国境外的人都使用邀请方式(在英国的朋友有福了;-)),而包括我在内都是没有邀请码的。
所以按照新闻走,去 www.proxz.com/proxy_list_uk_0_ext.html 上找个英国的代理,在使用前最好 ping 一下,看看能否连上。
我用的是 212.241.180.239:81 这个地址。
然后去改代理,Mac OS X 在 System Preferences 的 Network 的 Advanced 里。
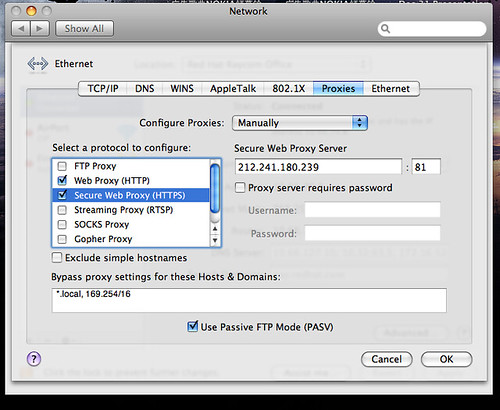
把 HTTP 和 HTTPS 的代理都选上,都改掉,然后访问:
www.spotify.com/en/get-started/
应该就是注册新帐号的页面了 ;-)

Spotify 不但是很好的音乐共享软件(其实仅限于从服务器上抓下音乐来,好像不能自己把音乐共享出去),而且还是很好的 Last.FM 客户端,在 Preferences 里填入 Last.FM 帐号后就可以自动连接 Last.FM。
最关键的是它是完整长度的试听,只是不能下载(可以 HiJack 下来,哈~)
很值得一试喔 ;-)
=========================================================
手头有五个邀请,想要的可以留邮箱。
=========================================================
用邀请码注册还是会区分国家,所以还得用代理注册。
你好,2009。
这一年,我们经历了春运期的南方雪灾,经历了汶川地震,经历了经济危机,同时也经历了中国第一届奥运会,经历了神七上天。
2008 给我们带来了不可磨灭的记忆。
再见,过去了的丰富的 2008。
你好,我们将迎接你,2009。
Happy new year to everybody. :-)
日版 D2C Key Wii 改版美版完美教程(持续更新)
前两天在逛 Wii 论坛上看到了目前市场上有很多韩版 Wii 改美版后进行销售的帖子,遂看到了居然有改区一说,于是乎想在自己的日版(已经加了 D2C 直读)的情况下尝试一下改区,没想到因为之前已经升级到 3.4J,降级后改版反而效果更好(Photo、Wii Shop Channel 都可以直接使用),后又去兔子那里改了下 D2C 直读的跳线,使原本只用 Starfall 的全区支持也更加完善。
现放出方法。
概况是:
- 通过网络升级到 3.4J
- 通过 这篇教程 进行降级,降级后进系统查看就应该已经是 3.2J,不过这个教程耗时稍长,但是确实完美。
- 使用 AnyRegion Changer 改区,并且安装 3.2U 系统。
- 找个 JS 帮你焊掉 D2C 芯片的 JP2 跳线(JP1 是美版,JP1 + JP2 是日版),或者先用 Starfall 顶着。
- 删掉 News 和 Weather 频道,并且用美版的替换(我还没做)。
- 用 Starfaill 开启频道全区支持并去掉光盘自动更新检查。
如果不出问题,改区之后原本系统里的 WII Shop Channel 已经是 49(美国),而且可以正常使用。
而我后来为了删帐号又改成了 1(日本),进去后也无恙,结果又改成 49 后进入报了 205958 错,改成 1 后,尝试删除帐号,输入序列号后又出现了 206651 错误,现在依然在尝试解决。所以在改区后如果 Wii Shop Channel 可以使用的话,建议不用删除帐号。
待续(晚上贴图,上传改版软件,贴具体办法)。。。
Django 的 Form 真的很好用。
Django 的 Form 表单真的很好用,完全把以往繁琐的表单操作完全抽象出来,成了一个独立的组件。
该系统的最大特色就是与模板无关,表单元素完全在一个文件里就可以定义好,以后也可以随时扩充,修改,很方便。
为了使用富文本编辑器我还使用了 InPlaceEditor,之所以用它是因为它基于强大的 TinyMCE 编辑器,同时提供了很好的 Ajax 支持,为了使用它我还使用了 django-tinymce,这个东西理论上应该找不到编译好的包,可以用 easy_install 安装(在 Fedora 10 里的 python-setuptools-devel 包里),总之就是怎么方便怎么来啦。 :-)
OK, Let's get start it.
在 app 目录里建立一个 forms 的目录,touch 一个 __init__.py,然后在其中写下 newapp.py 文件,如下内容:
from django import forms
from tinymce.widgets import TinyMCE
TYPE_CHOICES = [
[1, 'Desktop Computer'],
[2, 'Laptop'],
]
class NewProduct(forms.Form):
name = forms.CharField()
type_id = forms.ChoiceField(choices=TYPE_CHOICES)
description = forms.CharField(widget=TinyMCE(mce_attrs={})
添加 View 里某个方法(比如 index)填上:
def index(request):
from testproject.app.forms.newapp import NewProduct
new_form = NewProduct()
return render_to_response('testform.html', { 'new_form' : new_form })
然后改模板,类似如下:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD XHTML 1.01//EN"> <html lang="en"> <head> <title>New Product</title> </head> <body> <h1>New Product</h1> <form action="." method="POST"> {{ new_form.as_table }} <p><input type="submit" value="Submit"></p> </form> </body> </html>
够好用吧?一个 form 定义好以后直接使用 as_table 方法就可以转换成表格。
如果需要更多自定义参数,也可以像访问数据库一样直接调用 form class 里的属性,如下:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD XHTML 1.01//EN"> <html lang="en"> <head> <title>New Product</title> </head> <body> <h1>New Product</h1> <form action="." method="POST"> {{ new_form.name }} {{ new_form.type_id }} {{ new_form.description }} <p><input type="submit" value="Submit"></p> </form> </body> </html>
在 Django 的官方教程里,设计一个 form class 的 ChoiceField 使用的是 Tuple,而我这里经过试验,List 也是可以的,而之所以使用 List,是因为这样可以通过数据库,向 ChoiceField 里添加数据,如:
from django import forms
from tinymce.widgets import TinyMCE
from testproject.app.models import ProductTypes
types = ProductTypes.objects.all()
TYPE_CHOICES = []
for type in types:
TYPE_CHOICES.append([type.id, type.name])
class NewProduct(forms.Form):
name = forms.CharField()
type_id = forms.ChoiceField(choices=TYPE_CHOICES)
description = forms.CharField(widget=TinyMCE(mce_attrs={})
嘿嘿,基本到此,还是比较简单的,附带一个我的 TinyMCE 的设置作为结尾好了。
from django import forms
from tinymce.widgets import TinyMCE
from testproject.app.models import ProductTypes
types = ProductTypes.objects.all()
TYPE_CHOICES = []
for type in types:
TYPE_CHOICES.append([type.id, type.name])
class NewProduct(forms.Form):
name = forms.CharField()
type_id = forms.ChoiceField(choices=TYPE_CHOICES)
description = forms.CharField(widget=TinyMCE(mce_attrs={'theme' : "advanced",
'skin' : "o2k7",
'skin_variant' : "silver",
'elements' : 'elm3',
'mode' : 'textareas',
'theme_advanced_toolbar_location' : "top",
'theme_advanced_toolbar_align' : "left",
'theme_advanced_resizing' : 'true',
'plugins' : "safari,pagebreak,style,layer,save,iespell,xhtmlxtras",
'theme_advanced_buttons1' : "fontselect,fontsizeselect,|,cut,copy,paste,pastetext,|,bullist,numlist,|,undo,redo,|,link,unlink",
'theme_advanced_buttons2' : "",
'theme_advanced_buttons3' : "",
})
不知道 Rails 或者其它 Web Framework 是否也有比较优秀的特色功能,希望也能有人能够介绍一下。
一不小心,看到 Mac OS X 10.5.6 里的新东东。
今天打开 System Preference 发现 OS X 10.5.6 里多了个新的 Trackpad 选项,还有视频图解如何使用 Multi-Touch,我火星了?!
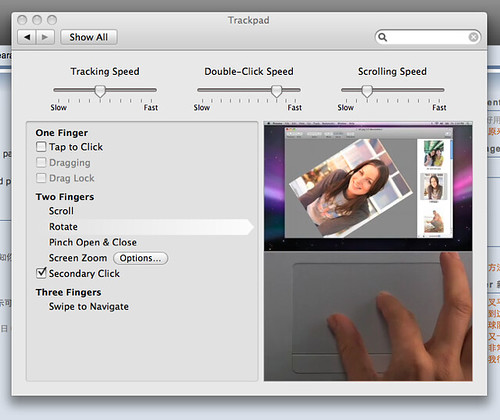
===========================================
附记:刚才在一班上看到可以在经典的铝外壳本上(最后一代非 Unibody)可以开启四指 Multi-Touch 的 kext 内核模块,
上传到了这里:http://www.box.net/shared/kp8jsregu2
经过测试,可用。
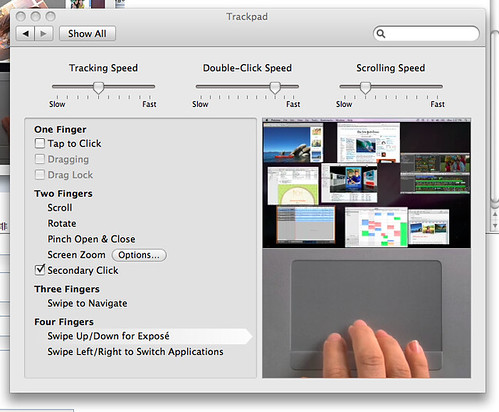
苹果净干些非能力不可为而不为之的事情。 -_-#
说来说去还是搞了 ReadyNAS 了。。。 -_-#

一下子手痒没忍住,还是搞了 ReadyNAS,很满意。
性能有点 XX,现在在用我的 Linksys WRH54G 当有线路由备份东西,每秒钟大约 3M 左右,和 Firewire 800 每秒 24M 的写入速度真的差好多。
装上 SSHToggle add-on,登上去一看,虽然早知道它是基于 Linux 的,但是一些发现还是让我吃了一惊。
nas:/bin# cat /proc/cpuinfo cpu : Infrant Technologics, Inc. - neon version: 0 fpu : Softfpu ncpus probed : 1 ncpus active : 1 BogoMips : 186.36 MMU : version: 0 LP : HW.FW version: 0.1 FPGA : fpga000000-0 Configuration: 0 AHB arbitraion : 7 CPU id : 0 Switch : 0 ASIC : IT3107
再用 file 看了下 Binrary,居然是 Sparc 的。。。 -_-#
nas:/bin# file /bin/ls ls: ELF 32-bit MSB executable, SPARC, version 1 (SYSV), for GNU/Linux 2.2.0, dynamically linked (uses shared libs), stripped
Bash 版本有点老:
nas:~# echo $BASH_VERSION 2.05b.0(1)-release
不过还是一个基本可玩的系统,只要是基于 Linux 的,就都有搞头~
找空跑跑 benchmark ...
JavaScript 加密器
给软件写个彩蛋,但是又不想随便被别人看见,于是乎给脚本加下密就成了必须的了,不是为了 Property software,而是来个 Easter egg 来取乐 :-)
找来找去,找到一个 JavaScript Compiler 还不错,经过测试可以在 Firefox 和 Safari 上正常使用(IE 就不考虑了,手头也没机器测试),普通的 Encrypt 工具可能可以支持 Safari,但是对 Firefox 的支持可真的是非常一般。
地址在:http://www.virtualpromote.com/tools/javascript-encrypt/
比如经典的 Hello World:
alert("Hello World");
被加密后就成了:
var enkripsi="cngpv'0:'00Jgnnm'02Umpnf'00'0;'1@"; teks=""; teksasli="";var panjang;panjang=enkripsi.length;for (i=0;i<panjang;i++){ teks+=String.fromCharCode(enkripsi.charCodeAt(i)^2) }teksasli=unescape(teks);document.write(teksasli);
看不懂了吧? ;-)
不过使用 JavaScript Compiler 有限制,生成的代码必须以单独的文件存放,而且文件还得写上 JavaScript 的标记段,因为其实它的原理是将加密的内容,解密后直接插入 DOM 树里形成的,如果不这样做,将会在浏览器窗口中直接看到解密后的 JavaScript 代码,从这种意义上说,它就不仅仅是 JavaScript 的 Compiler 了,HTML、CSS 一类也可以用它加密。
而且为了让加密后的代码能够更加容易地调用,我们最好还能够写成 Function 的模式。
这里是可供调用的完整的代码:
<script type="text/javascript">
function helloworld() {
alert("Hello World");
}
</script>
function helloworld() {
alert("Hello World");
}
</script>
加密后的代码就成了:
var enkripsi="'1Aqapkrv'02v{rg'1F'00vgzv-hctcqapkrv'00'1G'2Cdwlavkml'02jgnnmumpnf'0:'0;'02'5@'2C'02'02'02'02cngpv'0:'00Jgnnm'02Umpnf'00'0;'1@'2C'5F'2C'1A-qapkrv'1G"; teks=""; teksasli="";var panjang;panjang=enkripsi.length;for (i=0;i<panjang;i++){ teks+=String.fromCharCode(enkripsi.charCodeAt(i)^2) }teksasli=unescape(teks);document.write(teksasli);
把它单独存成一个文件(比如 foo.js),然后引用它:
<script type="text/javascript" src="/js/foo.js"></script>
以后,只要在程序中调用 helloworld 函数就可以显示 Hello World 了。 :-)
QuartzGL ?!
这 Tiger 里据称就是原来的 Quartz 2D Exteme,到 Leopard 里换了个名字叫 QuartzGL 了。刚刚在 Quartz Debug 的 Tools 菜单里看见有开启它的选项,所以就开了一下,用 xbench 跑了跑测试,结果居然比不开性能还差,而且还导致一些应用程序的不兼容现象出现(QuickSliver 启动画面成一半透明白框,据说Dashboard也会有问题),所以我还是关了。
开启方法是:
$ sudo defaults write /Library/Preferences/com.apple.windowserver QuartzGLEnabled -boolean YES
恢复方法是:
$ sudo defaults write /Library/Preferences/com.apple.windowserver QuartzGLEnabled -boolean NO
注销即可,不过我为了测试结果的准确性重启了电脑。
开了后的结果:
Results 179.93 System Info Xbench Version 1.3 System Version 10.5.5 (9F33) Physical RAM 2048 MB Model MacBookPro4,1 Drive Type FUJITSU MHY2200BH Quartz Graphics Test 144.47 Line 181.54 12.09 Klines/sec [50% alpha] Rectangle 145.47 43.43 Krects/sec [50% alpha] Circle 235.46 19.19 Kcircles/sec [50% alpha] Bezier 78.55 1.98 Kbeziers/sec [50% alpha] Text 190.48 11.92 Kchars/sec OpenGL Graphics Test 164.98 Spinning Squares 164.98 209.29 frames/sec User Interface Test 271.05 Elements 271.05 1.24 Krefresh/sec
没开的结果:
Results 206.56 System Info Xbench Version 1.3 System Version 10.5.5 (9F33) Physical RAM 2048 MB Model MacBookPro4,1 Drive Type FUJITSU MHY2200BH Quartz Graphics Test 192.86 Line 176.63 11.76 Klines/sec [50% alpha] Rectangle 232.50 69.41 Krects/sec [50% alpha] Circle 189.12 15.42 Kcircles/sec [50% alpha] Bezier 189.01 4.77 Kbeziers/sec [50% alpha] Text 185.73 11.62 Kchars/sec OpenGL Graphics Test 167.72 Spinning Squares 167.72 212.76 frames/sec User Interface Test 296.17 Elements 296.17 1.36 Krefresh/sec
完整的测试结果在:http://db.xbench.com/merge.xhtml?doc1=327066&doc2=327063
注意:因为单独的图形结果和完整测试不是同一个时间完成,所以数据有所偏差
一个 Django 的超简单的数据库应用
昨天 Launch & Learn 的时候,做了个简单的 Django 的数据库应用,以配合 Li Li Zhang 的 ORM Course。
其实用 Django 做数据库应用真的很简单,不过比较适合用于重头设计的 Database Schema,然后用 syncdb 来同步数据库。
目前 Django 对 ForeignKey 和 One to One, One to Many, Many to Many 支持得都不错,最大的缺陷还是缺乏 Join 的支持导致多表联查的性能不好,这也是我在做开发的过程中碰到的最大问题。
其实用 Django 重头做一个数据库开发非常简单,用下面几步就可以了。
FIRST: Create new project and a new app with django-admin.py $ django-admin.py startproject [project_name] $ cd [project_name] $ django-admin.py startapp [app_name] SECOND: Edit the settings.py file to adjust db settings and installed apps. THIRD: Edit the [app_name]/models.py to modeling the database schema FOURTH: Edit the [prject_name]/urls.py to adjust the path of URL. FIFTH: Edit the [app_name]/views.py to realize your function. SIXTH: To run the manage.py to start the test server in the project. $ ./manage.py runserver THE END: Use your browser to navigate to your http://localhost:8000 and enjoy in it. :-)
这里提供了一个范例,也是昨天在 Launch and Learn 上演示过的:www.box.net/shared/6036abumgv 中的 lnl.tar.bz2 文件,里面提供的 Steps 其实就是上面那段,只是代码中也提供了注释以方便阅读。
用 Synergy 共享两台电脑的键盘鼠标
情况:
因为公司另有一台性能很强劲的 Linux 工作站,自己有台 mac 笔记本,在两台电脑间来回切换让人很郁闷,所以就想让一套键盘鼠标在两个系统上都能使用上,把两台电脑当成一台电脑用。
之前用过 Synergy,所以又重新打起了它的主意,唯一和以前不同的是,现在我懒了很多,都不愿意用命令行来做这种配置工作了。。。 -_-#
安装:
Mac 从 http://sourceforge.net/projects/synergykm 上下载 SynergyKM,并且安装,会在 System Preferences 里增加 SynergyKM 一项。
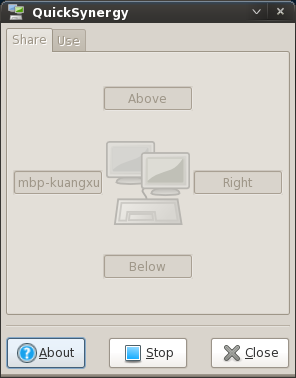
Fedora 9 用 yum install quicksynergy synergy 来安装 Synergy 程序,然后会在 GNOME 菜单下的 internet 项下增加 QuickSynergy 一项。
配置:
我这里是把 Fedora 工作站当成服务器,共享它的键盘鼠标,而我的笔记本放在工作站的左边,所以在 QuickSynergy 的 Share 标签页左边写上 Macbook Pro 的主机名,然后点击 Execute。
如图:
然后在 Mac OS X 的 System Preferences 里启动 SynergyKM,选择 Connect to shared keyboard and mouse,然后在 Client Configuration 里写上服务器的主机名或者 IP 地址,点上 Apply Now,然后再回到 General 标签页里,点击 Turn Synergy On,如果下面的 Status 显示了 Connected 则连接成功。
如图:
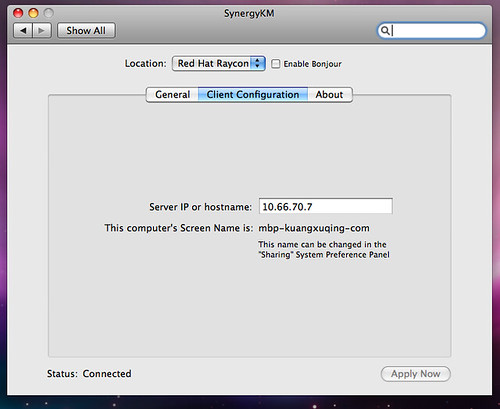
好了,现在可以试试把台式机的鼠标指针“跨过”屏幕左边,直接挪到左边的 Mac 上进行操作了。
不仅如此,Synergy 还能在两台电脑间共享剪贴板,真正是把两台电脑当成一台用。
不过好像有点 Bug,在 Fedora 机器上开着一个菜单的时候,鼠标是被局限在 Fedora 的机器上的。
在博客上加上 Fedora 10 发布计时器
Fedora Project 提供了 Fedora 10 的发布倒计时器,只要在自己的博客边栏里加上下面的 HTML 代码,效果看我的博客旁边。
-
<script id="fedora-banner" type="text/javascript"
-
src="http://fedoraproject.org/static/js/release-counter-ext.js?
-
lang=en_US"></script>



scribes 编辑器,不错,不错
自定义了很多 HTML 标签,总算用起来比较顺手了。
稍后把 javascript、python 和 css 的 templates 都完善一下,就发上来。
最好用这个地址看:
记下给 iPhone 做 ipa 和 ringtone 的方法
IPA:
- 因为每次用 scp 把 .app 拷进 iPhone 实在是太 XX,所以还是做成 ipa,拖进 iTunes 让它自己同步的好!
- 准备工作:
- 首先,需要一份被破解了的 MobileInstallation, for iPhone OS 2.1 的一搜就有很多 - Google,然后用 scp 复制到 iPhone 的 /System/Library/MobileInstallation.framework 里,否则未经过 Apple 签名的程序都无法安装;
- 找一份已经被破解的程序,比如 WeDict Pro;
- 开始干活:
- 再去 iTunes App Store 上找到 WeDict Pro 的页面,并且用鼠标右键点击其中的图标,选择 Copy iTunes Store URL,并且粘贴到一个文本编辑器里,比如这个:http://phobos.apple.com/WebObjects/MZStore.woa/wa/viewSoftware?id=287799252&mt=8;
- 把其中的 phobos.apple.com 替换成 phobos.apple.com.edgesuite.net,并且粘贴到浏览器地址栏中打开,可以看到乱七八糟的东西;
- 打开源代码,并且在其中搜索“100x100-75”,然后把整个地址全部复制下来,并粘贴到浏览器地址栏里打开;
- 这时可以看到 WeDict Pro 的图标了,然后把 100x100 换成 512x512,并重新打开,出现了超大图标;
- 把打图标保存到电脑里,起名为 iTunesArtwork(不要扩展名,如果有必要的话,可能需要借助终端重新命名);
- 随便找地方建个目录,叫 package,并且在 package 里再建一个目录叫 Payload(区分大小写);
- 把刚弄的 iTunesArtwork 弄到 package 目录里,并且把权限改成 665(为什么是 665?!我也不知道),再把破解好的程序弄到 Payload 目录里;
- 给 Payload 里的程序加上执行权限(需要 Mac OS X 或者 Linux,Windows 应该不行),比如 WeDict Pro 就是 chmod 755 Payload/WeDict\ Pro/WeDictPro
- WeDict Pro 不用做,但别的程序可能要做的一步:用 Property List Editor(Mac OS X Only) 修改 Payload 程序里的 Info.plist,加上“SignerIdentity”段,内容是“Apple iPhone OS Application Signing”,并且保存;
- 最后打包:
- 到 package 目录里,用 WinRAR 把 iTunesArtwork 和 Payload 目录打进一个 .zip 文件里,或者 Mac OS X 的 Compress 2 items,Mac 上会生成一个 Archive.zip 文件
- 把生成的 zip 文件,重新命名为一个 .ipa 文件(比如我的 WeDict Pro.ipa),把它拖进 iTunes,大功告成
- iPhone 就那么几个铃声,听多了多无聊啊,scp 拷上去的每次 iTunes 同步后都丢,怎么办,做成 iTunes 能认的不就行了
- BTW: 现在 iTunes 可以创建铃声,不过仅限于从 iTunes Store 上购买的曲子,所以基本还是白搭
- 首先准备好 mp3 文件,然后用 QuickTime 打开(QuickTime 需要注册一下,否则无法进行编辑),裁剪到合适的段落,不能超过 40 秒,否则能拖进 iTunes 可是无法同步
- 然后用 Edit 菜单下的 Trim to Selection,并且导出成 AAC
- 实际上导出是 .mov 的扩展名,把它改成 .m4r,然后拖进 iTunes 就可以了
娱乐一下,听首歌(say a word in heart)
http://224.cachefile7.rayfile.com/2954/zh-cn/preview/c05e32e4188142f9d71ab56266d8f44a/preview.mp3
来源:www.lansin.com 说句心里话 say a word in heart 说句心里话 say a word in heart 我也想家 I think my home too 家中的老妈妈已是满头白发 often think my mother is white in hair 说句实在话我也有爱 say a word in heart I have love too 常思念梦中的她 often think a sleep her a sleep her 来来来既然来当兵 come~come (lai)~~but became a soldier 来来来就知责任大 lai~~~~~~I know duty is big 你不扛枪我不杠枪 you don't carry gun I don't carry gun 谁保卫咱妈妈 who guard our mom (protect the mother) 谁来保卫她 who come guard her 谁来保卫她 who come guard her !!!?!?!??!??
没事对三个 Web Framework 的 Mail-list 数量也做个比较
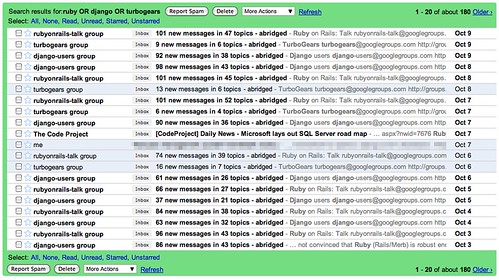
结果是:TurboGears 真的没人用了吗。。。
Django 和 TurboGears ORM 性能测试完成
连续插入、查询、更改、删除 1000 个记录的测试,其实 ORM 比起在 MySQL 里直接执行真的慢多了(我的代码也得进一步优化)。。。
Django:
TurboGears:

下载在:http://www.box.net/shared/877kl03ht7
可以看出 Django 在 Insert 和 Select 动作上速度比较快,而在 Update 和 Drop 上稍慢一些。
这是因为 TurboGears SQLObject 提供了一个 get 方法可以直接获取数据库中对应 id 号的字段,而在做 DROP 操作时我使用了 clearTable 来直接清空表,而 Django 是一条条查询,一条条 delete。
总体上我还是对 Django 的性能比较满意的,这帮人在性能上的优化很 BT ...
PS: 下午给 SQLAlchemy 也做了个简单测试,还没搞明白怎么回事,执行 1000 次插入数据,结果实际只插入了一条,查询语句也有问题,不过性能已经能用”惨不忍睹“来形容了。
如下:
Insert Speed: 0.176656007767Select Speed: 0.0367720127106
Update Speed: 0
Drop Speed: 0
近况
有了新 email: xkuang at redhat.com, 可能要暂时和 gentoo 分开一段时间了, 全身心泡入 fedora 和 mac os x 上... -_-#
近期要推出一个 Django 和 TurboGears 的 MySQL ORM 性能对比, 和 Ajax 使用难易程度的对比, 还请期待. ;-)
ps: 好在 yum 还算比较好用, mac os x textmate 用来做 python 开发也不算差.
批量更改 mp3 id3 标签编码
不想用 id3mod,自然有自由软件的解决办法。
$ wget http://quodlibet.googlecode.com/files/mutagen-1.14.tar.gz $ sudo easyinstall mutagen-1.14.tar.gz Processing mutagen-1.14.tar.gz Running mutagen-1.14/setup.py -q bdist_egg --dist-dir /tmp/easy_install-0hg6pP/mutagen-1.14/egg-dist-tmp--Dn1sG zip_safe flag not set; analyzing archive contents... mutagen 1.14 is already the active version in easy-install.pth Installing moggsplit script to /usr/local/bin Installing mutagen-inspect script to /usr/local/bin Installing mutagen-pony script to /usr/local/bin Installing mid3iconv script to /usr/local/bin Installing mid3v2 script to /usr/local/bin Installed /Library/Python/2.5/site-packages/mutagen-1.14-py2.5.egg Processing dependencies for mutagen==1.14 Finished processing dependencies for mutagen==1.14然后切到 mp3 的目录里,比如我的“~/Desktop/周杰伦/魔杰座”,直接执行:
$ cd ~/Desktop/周杰伦/魔杰座
$ find . -name \*.mp3 -exe mid3iconv -e GBK {} \;
Updating ./01 魔杰座.mp3
Updating ./02 女儿红.mp3
Updating ./03 东方之殿.mp3
Updating ./04 红楼梦中.mp3
...
拖入 iTunes,搞定~在 Mac OS X 上为 Django 安装 MySQL-python 1.2.2
在 Mac OS X 上安装 MySQL-python 花了一点点功夫, 记一下:
先去 Sun 网站上下载最新版本的 MySQL, 再去 djangoproject.org 上下载最新版本的 Django 1.0 release, 并且正常安装.
然后用 easyinstall mysql-python, 发现无法正常安装.
查看 easyinstall 的下载路径, 用下面的命令下载并且解压缩
然后修改 site.cfg, 修改下面内容:
由
改成
否则会出现找不到 MySQL config 的问题:
然后修改 _mysql.c, 把第 37 到 39 行注释掉, 如下:
否则会出现:
然后再用 python ./setup.py build 编译
然后再用 python ./setup.py install 安装
然后用下面的命令进行测试:
如果能正常输出就没有问题了 :-)
先去 Sun 网站上下载最新版本的 MySQL, 再去 djangoproject.org 上下载最新版本的 Django 1.0 release, 并且正常安装.
然后用 easyinstall mysql-python, 发现无法正常安装.
查看 easyinstall 的下载路径, 用下面的命令下载并且解压缩
$ cd /tmp $ curl -o MySQL-python-1.2.2.tar.gz http://internap.dl.sourceforge.net/sourceforge/mysql-python/MySQL-python-1.2.2.tar.gz $ tar xvf MySQL-python-1.2.2.tar.gz $ cd MySQL-python-1.2.2
然后修改 site.cfg, 修改下面内容:
由
#mysql_config = /usr/local/bin/mysql_config
改成
mysql_config = /usr/local/mysql/bin/mysql_config
否则会出现找不到 MySQL config 的问题:
... File "/tmp/easy_install-nHSsgl/MySQL-python-1.2.2/setup_posix.py", line 24, in mysql_config EnvironmentError: mysql_config not found
然后修改 _mysql.c, 把第 37 到 39 行注释掉, 如下:
//#ifndef uint //#define uint unsigned int //#endif
否则会出现:
In file included from /usr/local/mysql/include/mysql.h:47,
from _mysql.c:40:
/usr/include/sys/types.h:92: error: duplicate 'unsigned'
/usr/include/sys/types.h:92: error: two or more data types in declaration specifiers
error: command 'gcc' failed with exit status 1
然后再用 python ./setup.py build 编译
$ python ./setup.py build running build running build_py copying MySQLdb/release.py -> build/lib.macosx-10.5-i386-2.5/MySQLdb running build_ext building '_mysql' extension gcc -fno-strict-aliasing -Wno-long-double -no-cpp-precomp -mno-fused-madd -fno-common -dynamic -DNDEBUG -g -Os -Wall -Wstrict-prototypes -DMACOSX -I/usr/include/ffi -DENABLE_DTRACE -pipe -Dversion_info=(1,2,2,'final',0) -D__version__=1.2.2 -I/usr/local/mysql/include -I/System/Library/Frameworks/Python.framework/Versions/2.5/include/python2.5 -c _mysql.c -o build/temp.macosx-10.5-i386-2.5/_mysql.o -g -Os -arch i386 -fno-common -D_P1003_1B_VISIBLE -DSIGNAL_WITH_VIO_CLOSE -DSIGNALS_DONT_BREAK_READ -DIGNORE_SIGHUP_SIGQUIT gcc -Wl,-F. -bundle -undefined dynamic_lookup -arch i386 -arch ppc build/temp.macosx-10.5-i386-2.5/_mysql.o -L/usr/local/mysql/lib -lmysqlclient_r -lz -lm -lmygcc -o build/lib.macosx-10.5-i386-2.5/_mysql.so ld: warning in build/temp.macosx-10.5-i386-2.5/_mysql.o, file is not of required architecture ld: warning in /usr/local/mysql/lib/libmysqlclient_r.dylib, file is not of required architecture ld: warning in /usr/local/mysql/lib/libmygcc.a, file is not of required architecture
然后再用 python ./setup.py install 安装
$ sudo python ./setup.py install Password: running install running bdist_egg running egg_info writing MySQL_python.egg-info/PKG-INFO writing top-level names to MySQL_python.egg-info/top_level.txt writing dependency_links to MySQL_python.egg-info/dependency_links.txt reading manifest file 'MySQL_python.egg-info/SOURCES.txt' reading manifest template 'MANIFEST.in' writing manifest file 'MySQL_python.egg-info/SOURCES.txt' installing library code to build/bdist.macosx-10.5-i386/egg running install_lib running build_py copying MySQLdb/release.py -> build/lib.macosx-10.5-i386-2.5/MySQLdb running build_ext creating build/bdist.macosx-10.5-i386 creating build/bdist.macosx-10.5-i386/egg copying build/lib.macosx-10.5-i386-2.5/_mysql.so -> build/bdist.macosx-10.5-i386/egg copying build/lib.macosx-10.5-i386-2.5/_mysql_exceptions.py -> build/bdist.macosx-10.5-i386/egg creating build/bdist.macosx-10.5-i386/egg/MySQLdb ...
然后用下面的命令进行测试:
$ cd ~ $ python Python 2.5.1 (r251:54863, Apr 15 2008, 22:57:26) [GCC 4.0.1 (Apple Inc. build 5465)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import MySQLdb >>> MySQLdb.apilevel '2.0' >>> import django >>> print django.VERSION (1, 0, 'final')
如果能正常输出就没有问题了 :-)
苹果归来
自从今年年初就把我的小黑贡献给了天津人民,用了半年多 DELL,总算又搞回苹果本本。
好长时间没用,都有点生疏了。。。 -_-#
上周四那天中央电视台的人来采访红旗,我给他们做了桌面演示,把我的 Compiz Fusion 的桌面给他们看了。12 号那天晚上获知要在东方节目中播出,没想到居然是和番茄花园牵扯到了一起。
其实我一直是没用过番茄花园的,平时都是使用绝对正版的,和苹果机附带的 Mac OS X 和 Linux 系统,顶多用 wine 跑跑一些免费的 Windows 软件。很多时候我也是这么鼓励我周围的朋友这么做的。
这周五把那台 DELL 本本换给了公司,因为我即将离开那里,等我在新公司扎下根来,我会过来向大家汇报一下的。
现在努力专攻 Django 和 Python,还请多多交流!
对了,新拿到的本本是 Macbook Pro MB133,有空会做份 nbench 测试并且放上来的。
好长时间没用,都有点生疏了。。。 -_-#
上周四那天中央电视台的人来采访红旗,我给他们做了桌面演示,把我的 Compiz Fusion 的桌面给他们看了。12 号那天晚上获知要在东方节目中播出,没想到居然是和番茄花园牵扯到了一起。
其实我一直是没用过番茄花园的,平时都是使用绝对正版的,和苹果机附带的 Mac OS X 和 Linux 系统,顶多用 wine 跑跑一些免费的 Windows 软件。很多时候我也是这么鼓励我周围的朋友这么做的。
这周五把那台 DELL 本本换给了公司,因为我即将离开那里,等我在新公司扎下根来,我会过来向大家汇报一下的。
现在努力专攻 Django 和 Python,还请多多交流!
对了,新拿到的本本是 Macbook Pro MB133,有空会做份 nbench 测试并且放上来的。
用 Wine 将 Google Chrome 运行于 Linux 之上
如图:

运行平台是 Red Flag Desktop 6.0 SP1 Update。
环境是 wine 1.1.3 带 winetricks,安装后运行
$
例如:
然后点击桌面上图标就可以运行了。
不过目前仍然存在一些问题:
https 协议似乎无法访问,会导致一个“错误2(net::FAILD): 未知错误”。
标签页拖出来以后是一个黑块。
不过浏览普通网页够用了,所以可以先凑合用着。
主要参考了 LinuxTOY 这篇文章。
运行平台是 Red Flag Desktop 6.0 SP1 Update。
环境是 wine 1.1.3 带 winetricks,安装后运行
$
winetricks riched20 riched30 flash allfonts
安装控件和 Flash 插件。
然后从网上下载 Google Chrome(从前一篇日志的地址),并安装,安装时需要 root 帐户(但不推荐用 root 帐户平时使用系统),可以用 sudo 切过去然后再改变文件的所有者和路径来改回普通用户。
安装后选择不要立刻启动 Chrome,否则会崩溃。
需要编辑一下桌面上的“谷歌浏览器.desktop”文件,把 Exec 那行末尾添上:--new-http --in-process-plugins例如:
Exec=env WINEPREFIX="/home/xqkuang/.wine" wine "C:\\windows\\profiles\\xqkuang\\Local Settings\\Application Data\\Google\\Chrome\\Application\\chrome.exe" --new-http --in-process-plugins
然后再把 Windows 中的 simsun.ttc 和 simhei.ttf 拷贝出来,放到 ~/然后点击桌面上图标就可以运行了。
不过目前仍然存在一些问题:
https 协议似乎无法访问,会导致一个“错误2(net::FAILD): 未知错误”。
标签页拖出来以后是一个黑块。
不过浏览普通网页够用了,所以可以先凑合用着。
主要参考了 LinuxTOY 这篇文章。
自从有了 Google Chrome,可以甩掉其它 Webkit 的浏览器了。
一直就对 Mac OS X 下的 Safari 颇有好感,可惜 Windows 版的 Safari 太鸡肋。
一直用 Arora for Windows 和 Midori for Linux 代替 Safari 在其它平台上的使用,主要就是因为 Webkit 是唯一一个在百度空间上可以不使用 FCKEditor 的浏览器。
白天一直都在 Linux 上工作,晚上才回到家,把玩了一下,感觉非常不错,性能非常不错,占用率在可接受范围之内。 :-)

下载地址在:http://cache.pack.google.com/chrome/install/149.27/chrome_installer.exe
这里还有一个有趣的漫画(由“译言”翻译):http://yeeyan.googlecode.com/files/GoogleChrome.pdf
一直用 Arora for Windows 和 Midori for Linux 代替 Safari 在其它平台上的使用,主要就是因为 Webkit 是唯一一个在百度空间上可以不使用 FCKEditor 的浏览器。
白天一直都在 Linux 上工作,晚上才回到家,把玩了一下,感觉非常不错,性能非常不错,占用率在可接受范围之内。 :-)
下载地址在:http://cache.pack.google.com/chrome/install/149.27/chrome_installer.exe
这里还有一个有趣的漫画(由“译言”翻译):http://yeeyan.googlecode.com/files/GoogleChrome.pdf
以普通用户编包
RPM:
## 建目录
$ cd ~
$ mkdir rpm
$ cd rpm
$ ls /usr/src/redflag/ | xargs mkdir -pv
mkdir: 已创建目录 “BUILD”
mkdir: 已创建目录 “RPMS”
mkdir: 已创建目录 “SOURCES”
mkdir: 已创建目录 “SPECS”
mkdir: 已创建目录 “SRPMS”
$ cd RPMS
$ ls /usr/src/redflag/RPMS | xargs mkdir -pv
mkdir: 已创建目录 “athlon”
mkdir: 已创建目录 “i386”
mkdir: 已创建目录 “i486”
mkdir: 已创建目录 “i586”
mkdir: 已创建目录 “i686”
mkdir: 已创建目录 “noarch”
## 写 rpmmacros 定义变量
echo "%_topdir $HOME/rpm" > ~/.rpmmacros
## 开始 rpm -ivh xxx.src.rpm 开始编包吧。
Portage:
写一个 Overlay ;-)
## 建目录
$ cd ~
$ mkdir rpm
$ cd rpm
$ ls /usr/src/redflag/ | xargs mkdir -pv
mkdir: 已创建目录 “BUILD”
mkdir: 已创建目录 “RPMS”
mkdir: 已创建目录 “SOURCES”
mkdir: 已创建目录 “SPECS”
mkdir: 已创建目录 “SRPMS”
$ cd RPMS
$ ls /usr/src/redflag/RPMS | xargs mkdir -pv
mkdir: 已创建目录 “athlon”
mkdir: 已创建目录 “i386”
mkdir: 已创建目录 “i486”
mkdir: 已创建目录 “i586”
mkdir: 已创建目录 “i686”
mkdir: 已创建目录 “noarch”
## 写 rpmmacros 定义变量
echo "%_topdir $HOME/rpm" > ~/.rpmmacros
## 开始 rpm -ivh xxx.src.rpm 开始编包吧。
Portage:
写一个 Overlay ;-)
Samsung Omnia i900 开箱视频
太囧了。。。
播放时请打开音响。
播放时请打开音响。
PHP 页面跳转的代码
做麦当劳网站的时候写了个页面跳转的代码,足够精简,贴在这里备忘,效果如下图:
1 $connect = mysql_pconnect($host, $username,$password); 2 mysql_select_db("test"); 3 4 $start = $_GET['start']; 5 $limit = "25"; 6 $query_all = "SELECT id FROM test WHERE disabled=0"; 7 8 $result_all = mysql_query($query_all); 9 $num=mysql_numrows($result_all); 10 11 // 设置前后页变量 12 $prve=$start-$limit; 13 $next=$start $limit; 14 15 // 设置向前翻页的跳转 16 if ($prve >= 0) { 17 echo "<a href=test.php?start=$prve _fcksavedurl=test.php?start=$prve _fcksavedurl=test.php?start=$prve _fcksavedurl=test.php?start=$prve>上一页</a>"; 18 echo " "; 19 echo "\n"; 20 } 21 22 // 显示页码 23 if ($num > $limit) { 24 $nextstart = 0; 25 $pstart = $start; 26 for ($page = 0; $page < ($num/$limit); $page ) { 27 $pagedisplay = $page 1; 28 if($page != $pstart / $limit) 29 echo "<a href=\"test.php?start=$nextstart\">"; 30 else 31 echo "<font color=\"black\" size=\"3\">"; 32 33 echo "[$pagedisplay] "; 34 35 if($page != $pstart / $limit) 36 echo "</a>"; 37 else 38 echo "</font>"; 39 40 echo "\n"; 41 42 if ($page > 0 && ($page % 20) == 0) { 43 break; //退出循环 44 } 45 46 $nextstart = $nextstart $limit; 47 } 48 } 49 50 // 设置向后翻页的跳转 51 if ($next < $num) { 52 echo " "; 53 echo "<a href=test.php?start=$next _fcksavedurl=test.php?start=$next _fcksavedurl=test.php?start=$next _fcksavedurl=test.php?start=$next>下一页</a>"; 54 echo "\n"; 55 }
今天中国第一家苹果直销店在北京三里屯开张

今天,中国第一家苹果直销店在北京三里屯开张,早有听说前一天晚上就有人在这里排队,真正到了之后才知道这里真正是人山人海。
旁边两个巨大的屏幕上滚动播出着苹果的 iPod 广告,下面的宾客等候室已经站满了人群,外面的人也都在打着黑伞的 Security 陪同下,准备进场。
我看这架势,今天上午恐怕是不用指望带着妞妞进场体验苹果邪教文化了,于是乎早早便离去,临走前拍下了本文开头这张 HDR 照片。
下午,刘佳发短信给我,问我在不在排队阵列,她说她正在排队,后来又发短信说已经离开,我问她排队多长时间,她说半个多小时一点,这样,我心里便有底了,下礼拜再带妞妞一起去参观一下这家华丽的苹果店。
另外,明天是妞妞 23 岁生日,我想祝妞妞生日快乐。
Gentoo 和 Windows 时钟同步
Windows 时钟和 Linux 时钟其实都是分为了系统时钟和硬件时钟的,硬件时钟存储于 BIOS 内部,而系统时钟存储于内核里,这两者的区别是系统时钟往往具有时区功能,而这两种操作系统对于时钟的处理方式却是不一样的,Windows 的系统时钟与硬件时钟同步,而 Linux 系统中的硬件时钟往往是格林尼治时间(GMT),而系统时钟才是真正的本地时间。
这一区别导致了在双系统的电脑中,Windows 的时钟往往比 Linux 慢 8 个小时,如果 Linux 直接设置为本地时间(localtime),运行 date 命令时又会出现 Timezone should be set, see zic manual page 的提示,其实这是有办法解决的。
-
第一种办法是使 Windows 使用 GMT 的硬件时钟,可以将下面内容另存为注册表文件(.reg)导入,或者直接在注册表编辑器(regedit)中修改:
Windows Registry Editor Version 5.00 [HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\TimeZoneInformation] "RealTimeIsUniversal"=dword:00000001 -
第二种办法是将 Linux 使用与硬件时钟同步的系统时钟,同时设置好时区
首先设置好本地时区
# zic -l Asia/Shanghai
其次设置 /etc/conf.d/hwclock(Gentoo 的 Baselayout 2 OpenRC 系统),修改其中的 clock 字段:
clock="local"
修改为clock="GMT" # 是的,没有看错,虽然注释称双系统时设置需要设置成 local,但实际上只有设置成 GMT 时 Linux 才能将硬件时钟作为系统时钟使用。
介绍个不错的编辑器 - e-texteditor
换到 Windows 后一直找不到感觉良好的编辑器,从 UltraEdit 到 EmEditor,把 EmEditor 用了一段时间,可是各个编辑器都有自己的特点,始终无法感到称手。
直到碰到了 e(不是 Linux 上的 enlightenment r17),总算找回了点 mac 下 textmate 的感觉。
该编辑器几乎就是 textmate 在 windows 上的克隆,操作方式和使用方法几乎完全一样,界面也是相同的简洁,同样有着 mac 操作的优雅。
在 File 菜单中点击 Open Dir as Project 后,还可以通过 Settings 对 Project 中的文件进行过滤:
对各种编码的支持也是非常强劲的:
查找和替换和 Firefox 一样位于窗口下部,而且连行为样式都完全一样,但支持正则表达式(最舒心的地方之一):

后退功能异常强劲,甚至可以分出两支来做不同版本的恢复:
TextMate 最强劲的 Bundle 功能,E 编辑器也完全照搬过来了,甚至可以和 TextMate 共享 Bundle,直接从 TextMate 网站上下载新的 bundle 即可直接放入 e 中使用。(据说 e 的作者和 textmate 的作者是老乡 -_-#)
按下 CTRL ALT T 键即可唤出 Bundles 窗口:
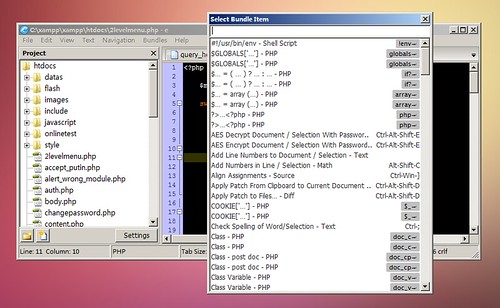
一些小技巧:
- e 也是支持语法补全的,只是要按下 ESC 键
- View 菜单下的 Web Preview 对 Web 开发者调试静态页面很有用
- 如果发现 e 不正常换行,可以在 View 菜单下的 Word Wrap 下调节
更多截图可以去:
http://flickr.com/photos/xuqingkuang/sets/72157605641477669/
下载可以去我的 Box:
http://www.box.net/shared/unhobn6gco
好好吃的可乐鸡翅
今天和宝贝儿一起吃可乐鸡翅,自己动手做!Yeah
准备材料:
鸡翅半斤(大约六块左右)
油
白砂糖
姜片
大料(八角)
蒜末
百事可乐1.25升(相对于可口可乐,百事的做出来的鸡翅更好吃,多了的可以吃鸡翅时喝掉,边吃可乐鸡翅边喝百事可乐爽哉爽哉。)
做法:
准备工作 - 在鸡翅上切上两刀,便于入味,切好姜丝,蒜末,越碎越好。
倒油,用大火烧,和平时做菜时一样多即可,因为后面还要倒可乐,所以不要多放油。
快加至热时撒一点点糖,因为可乐里已经有糖了所以只要放小小半勺即可
油热后关中火,放鸡翅,爆炒,炒至表皮有一点点黄,千万不要炒焦,发现有点粘锅立刻提锅。
炒黄后倒可乐和大料、姜丝、蒜末用中火炖,可乐淹过鸡翅即可,炖大约20分钟,等可乐快要熬干时出锅即可!
头一次做,好吃好吃~

准备材料:
鸡翅半斤(大约六块左右)
油
白砂糖
姜片
大料(八角)
蒜末
百事可乐1.25升(相对于可口可乐,百事的做出来的鸡翅更好吃,多了的可以吃鸡翅时喝掉,边吃可乐鸡翅边喝百事可乐爽哉爽哉。)
做法:
准备工作 - 在鸡翅上切上两刀,便于入味,切好姜丝,蒜末,越碎越好。
倒油,用大火烧,和平时做菜时一样多即可,因为后面还要倒可乐,所以不要多放油。
快加至热时撒一点点糖,因为可乐里已经有糖了所以只要放小小半勺即可
油热后关中火,放鸡翅,爆炒,炒至表皮有一点点黄,千万不要炒焦,发现有点粘锅立刻提锅。
炒黄后倒可乐和大料、姜丝、蒜末用中火炖,可乐淹过鸡翅即可,炖大约20分钟,等可乐快要熬干时出锅即可!
头一次做,好吃好吃~
今天你囧了吗?
这是继《Orz - 一直以为是拟声词,没想到。。。》后又一篇强文!
囧字幽默问答
问:”囧”是怎么开始流行起来的?
答:”囧”的人多了,自然有了”囧”!
问:请联系”囧”分别解释冏、同、冂的意思。
答:冏———下巴笑掉了的”囧”;
同———为保护当事人权益,照片作技术处理的”囧”;冂———打马赛克的”囧”。
囧字的衍生
“囧”因被网友认为像一个人的脸而在网络
生活中大肆流行,一些极具创意的人更是在它的象形上大做文章
于是一些”囧”的衍生字也应运而生……
崮:这是”囧”国国王。
莔:这是”囧”国皇后。
商:这是戴斗笠的”囧”。
囜:代表没有眼和口的脸。
国:这是歪嘴的脸。
苉:代表女人。
圙:这是老人家的脸。
囼:这个是没眼睛的脸。
囶:代表无话可说的表情。
囧家族不完全集合,你认识多少?
囘、囙、囜、囝、回、囟、因、囡、団、囤、囥、囦
囧、囨、囩、囱、囫、囬、囮、囯、困、囱、囲、図
囵、囶、囷、囸、囹、囻、囼、图、囿、圀、圁
圂、圂、圃、圄、圅、圆、囵、圈、圉、圊、国
圌、围、圎、圏、圎、圐、圑、园、圆、圔、圕
感谢一日一囧
感谢所有囧民
感谢囧囧有神的淫
感谢刘大夫
感谢小明
感谢湿令
感谢仓颉造出的囧字

史上最强的中式英语
史上最强的中式英语
1.we two who and who?
咱俩谁跟谁阿
2.how are you ? how old are you?
怎么是你,怎么老是你?
3.you have seed I will give you some color to see see, brothers ! together up !
你有种,我要给你点颜色瞧瞧,兄弟们,一起上!
4.as far as you go to die
有多远,死多远!!!!
5.hello everybody!if you have something to say,then say!if you have nothing to say,go home!!
有事起奏,无事退朝
6.you me you me
彼此彼此
7.You Give Me Stop!!
你给我站住!
8.know is know noknow is noknow
知之为知之,不知为不知…
9.WATCH SISTER
表妹
10.dragon born dragon,chicken born chicken,mouse’’son can make hole!!
龙生龙,凤生凤,老鼠的儿子会打洞!
11.I give you face you don’t wanna face,you lose you face ,I turn my face
给你脸你不要脸,你丢脸,我翻脸
12.one car come one car go ,two car pengpeng,people die
车祸现场描述
13.heart flower angry open
心花怒放
14.go past no mistake past
走过路过,不要错过
15.小明:I am sorry!
老外:I am sorry too!
小明:I am sorry three!
老外:What are you sorry for?
小明:I am sorry five!
16.If you want money,I have no;if you want life,I have one!
要钱没有,要命一条
17.I call Li old big. toyear 25.
我叫李老大,今年25。
18.you have two down son
你有两下子。
19.good good study,day day up!
好好学习,天天向上:
ZT戈革:《尼耳斯·玻尔集》译后记
谨此纪念于2007年12月29日下午4点10分,因直肠癌去世的科学史家、石油大学教授、《玻尔集》中译者戈革,享年86岁。
刊登于《科学文化评论》2007年第5期
《尼耳斯·玻尔集》译后记
戈 革
古代某哲人有云:“一部大书便是一项大罪。”这句话到底是何意?我至今不敢说“懂”。这里的“罪”,在英文中是“sin”,而不是“crime”,其义大致是指对“上帝”或“天道”的违犯而不是对任何“伟大领袖”(人也,非“神”)的触怒。无论如何,当年我等知识分子被从早到晚地骂为“罪该万死”,也绝不是因为我们写了一万本书!
刊登于《科学文化评论》2007年第5期
《尼耳斯·玻尔集》译后记
戈 革
古代某哲人有云:“一部大书便是一项大罪。”这句话到底是何意?我至今不敢说“懂”。这里的“罪”,在英文中是“sin”,而不是“crime”,其义大致是指对“上帝”或“天道”的违犯而不是对任何“伟大领袖”(人也,非“神”)的触怒。无论如何,当年我等知识分子被从早到晚地骂为“罪该万死”,也绝不是因为我们写了一万本书!
nbench 测试帖又加了两台机器的记录
今天对我新买的 Macbook 063 和龙芯盒子目前在做的 64 bits 版本的 everest 做了下 nbench 的性能测试。
所有测试结果放在: 这里。
| 测试平台 | 发行版 | 整数 | 浮点 | 内存 |
| Macbook 063(注5) | Mac OS X 10.5.1 (leopard) | 13.635 | 24.792 | 21.704 |
| 龙梦盒子 | Everest 0.5(64bits) | 3.183 | 4.754 | 2.728 |
从 Blogger 迁移到 Hi Baidu
原来用朋友的 ftp 上传空间已经到期了,而 blogspot 也被封了,只好再一次搬家。
测试了很多 BSP,最后还是感觉 Hi Baidu 的速度最快,界面也最为简洁,遂决定选它。
与当初预想的不同的是,当初看上 blogger 主要还是因为支持其 API 的 BSP 较多,可这一次依然碰到了很大的麻烦。
首先是迁移工具。
在 Google 搜索“博客搬家”,出现了一排的工具,搜出来的“博客联盟中也有提到”: 首先是 Blog Mover,这是个专业的博客搬家工具,支持 11 个 BSP 的导入和 9 个 BSP 的导出,但它在使用 Safari 时会报告“设置读取器失败”的错误,而使用 IE 6 时会停止在“初始化读取器”的状态下,后来才发现只有 Firefox 能够驱动它,这是我在犯了一天的错后才发现的,当然后面会继续提到它。
我尝试了 maikr博客伴侣 ,但发现其支持 Blogger 的 API,但不支持从 Blogger 的备份,遂放弃。
尝试了 “QQ 驿站”的搬家工具 但发现其只能迁移到 5ilog.com 上,而且我测试始终不能从我的 blogger 里导出,遂放弃。 blogmove.cn 不提供从 blogger 迁移,遂放弃。
从 blogmover 的帮助里看到了一个叫“博客蓝”的地址,支持博客导入,但是好像要从博客蓝导出需要支持其扩展的 XMLRPC API,而且我实在没找到有导出的地方,遂再一次放弃。
后来下午看见 Firefox 3 Beta 2 出来了,down 下一个来看看效果如何,首先想到的就是,用它来测试一下 Blog Mover,果不其然,能很好地支持 Blog Mover 的 JavaScript(看来确实还是有些网站是 Firefox Only 啊),
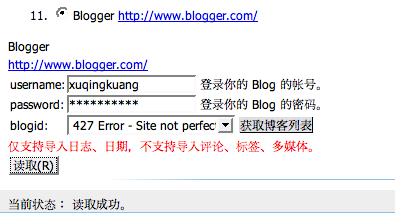
然后直接导入 Hi Baidu,可是却报错了。
这是怎么回事?
测试了一下,以登录状态直接在地址栏访问 http://hi.baidu.com/xuqingkuang/creat/blog/,会提示该博客尚未保存,但依然可以回到编写页面。
但在 Blog Mover 里写入一次以后再访问,就出现了刚才的错误,回到首页时,已经是登出状态。

可能是因为 Blog Mover 写入时没有使用 Hi Baidu 的 Cookies,导致了这个问题。
于是开始了曲线救国策略。
目前 Hi Baidu 支持新浪博客和 MSN Live Spaces 的搬家,这个工具在 http://hi.baidu.com/sys/bmove/ 也是没有出现在百度空间上,搜索得来的。
想到新浪博客在国内速度还算不错,遂写入进它吧,Blog Mover 不用关闭,直接往新浪博客里写入,没过一会儿,88 篇博客便已经写入了,然后再百度搬家,等了不到一个小时,搬完之后,咦。。。日期怎么全部丢了,都成了 12 月 21 日的了。。。。
去新浪看了下它的博客,原来它只支持修改发布时间,不支持修改发布日期的。 -__-# ...
看来可能不是 Blog Mover 的问题,那么试试 MSN Live Spaces? 好,写入,“邦”一声,“org.apache.xmlrpc.XmlRpcException: Access Denied”,这个错误,Google 一下,搜到了“这个”。 好,先给自己的 Live Spaces 加上自定义域名。 然后确认权限是开放给所有人的。
然后修改 E-mail publishing,按照帮助中的说明开启 E-mail publishing 并设置好 Secret word。
然后把刚才的自定义域名作为用户名,Secret word 作为密码填入 Blog Mover 中,写入,总算正常写入了 :) 然后再在 Hi Baidu 中再一次搬家。
总算全部导入进来了,只是评论丢了,介于 Hi Baidu 也无法选择评论日期,以及评论人,或者使用匿名评论,所以只好将以前的评论放弃了。
另外说一点:Live Spaces 在全部 Clear 以后,再一次创建时,左边的博客栏会只留下当前月份,我这里就是 December, 2007,但 Blog 本身的日期是正确的。
另外也给 Hi Baidu 提四点意见:
一是取消掉五次搬家限制,因为搬家并不容易,我这次就已经消耗掉了两次机会。
二是可能的话加入博客蓝的 XML RPC API 支持,虽然目前 Hi Baidu 已经支持了新浪和 MSN Spaces,这两个使用人群最大的 BSP,但是依然有很多其它 BSP 用户同样希望能够使用上 Hi Baidu 高效、快速的服务,如果百度自身不希望去花太大人力物力来支持其它 BSP 的话,那仅仅支持博客蓝就已经可以支持其它 44 个 BSP 的搬家,那类似与 Apple 在 iChat 中加入 Jabber 一样,无疑是个英明的决定。
三是希望能提供更好的 XML RPC 接口,与 Wordpress、Blogger 等大型 Blog 工具保持兼容,以更好支持本地应用。
四是能够更好地支持非 IE 和 Firefox 的浏览器,当然目前绝大多数功能对 Safari 支持得已经非常好,只是编辑框实在太“扁”了,而且在编辑框里必须手写 HTML,否则会把回车符丢掉,而且在编辑页面里添加新的分类也无法生效。希望能够自动识别一下浏览器并做出决定。
测试了很多 BSP,最后还是感觉 Hi Baidu 的速度最快,界面也最为简洁,遂决定选它。
与当初预想的不同的是,当初看上 blogger 主要还是因为支持其 API 的 BSP 较多,可这一次依然碰到了很大的麻烦。
首先是迁移工具。
在 Google 搜索“博客搬家”,出现了一排的工具,搜出来的“博客联盟中也有提到”: 首先是 Blog Mover,这是个专业的博客搬家工具,支持 11 个 BSP 的导入和 9 个 BSP 的导出,但它在使用 Safari 时会报告“设置读取器失败”的错误,而使用 IE 6 时会停止在“初始化读取器”的状态下,后来才发现只有 Firefox 能够驱动它,这是我在犯了一天的错后才发现的,当然后面会继续提到它。
我尝试了 maikr博客伴侣 ,但发现其支持 Blogger 的 API,但不支持从 Blogger 的备份,遂放弃。
尝试了 “QQ 驿站”的搬家工具 但发现其只能迁移到 5ilog.com 上,而且我测试始终不能从我的 blogger 里导出,遂放弃。 blogmove.cn 不提供从 blogger 迁移,遂放弃。
从 blogmover 的帮助里看到了一个叫“博客蓝”的地址,支持博客导入,但是好像要从博客蓝导出需要支持其扩展的 XMLRPC API,而且我实在没找到有导出的地方,遂再一次放弃。
后来下午看见 Firefox 3 Beta 2 出来了,down 下一个来看看效果如何,首先想到的就是,用它来测试一下 Blog Mover,果不其然,能很好地支持 Blog Mover 的 JavaScript(看来确实还是有些网站是 Firefox Only 啊),
然后直接导入 Hi Baidu,可是却报错了。
这是怎么回事?
测试了一下,以登录状态直接在地址栏访问 http://hi.baidu.com/xuqingkuang/creat/blog/,会提示该博客尚未保存,但依然可以回到编写页面。
但在 Blog Mover 里写入一次以后再访问,就出现了刚才的错误,回到首页时,已经是登出状态。
可能是因为 Blog Mover 写入时没有使用 Hi Baidu 的 Cookies,导致了这个问题。
于是开始了曲线救国策略。
目前 Hi Baidu 支持新浪博客和 MSN Live Spaces 的搬家,这个工具在 http://hi.baidu.com/sys/bmove/ 也是没有出现在百度空间上,搜索得来的。
想到新浪博客在国内速度还算不错,遂写入进它吧,Blog Mover 不用关闭,直接往新浪博客里写入,没过一会儿,88 篇博客便已经写入了,然后再百度搬家,等了不到一个小时,搬完之后,咦。。。日期怎么全部丢了,都成了 12 月 21 日的了。。。。
去新浪看了下它的博客,原来它只支持修改发布时间,不支持修改发布日期的。 -__-# ...
看来可能不是 Blog Mover 的问题,那么试试 MSN Live Spaces? 好,写入,“邦”一声,“org.apache.xmlrpc.XmlRpcException: Access Denied”,这个错误,Google 一下,搜到了“这个”。 好,先给自己的 Live Spaces 加上自定义域名。 然后确认权限是开放给所有人的。
然后修改 E-mail publishing,按照帮助中的说明开启 E-mail publishing 并设置好 Secret word。
然后把刚才的自定义域名作为用户名,Secret word 作为密码填入 Blog Mover 中,写入,总算正常写入了 :) 然后再在 Hi Baidu 中再一次搬家。
总算全部导入进来了,只是评论丢了,介于 Hi Baidu 也无法选择评论日期,以及评论人,或者使用匿名评论,所以只好将以前的评论放弃了。
另外说一点:Live Spaces 在全部 Clear 以后,再一次创建时,左边的博客栏会只留下当前月份,我这里就是 December, 2007,但 Blog 本身的日期是正确的。
另外也给 Hi Baidu 提四点意见:
一是取消掉五次搬家限制,因为搬家并不容易,我这次就已经消耗掉了两次机会。
二是可能的话加入博客蓝的 XML RPC API 支持,虽然目前 Hi Baidu 已经支持了新浪和 MSN Spaces,这两个使用人群最大的 BSP,但是依然有很多其它 BSP 用户同样希望能够使用上 Hi Baidu 高效、快速的服务,如果百度自身不希望去花太大人力物力来支持其它 BSP 的话,那仅仅支持博客蓝就已经可以支持其它 44 个 BSP 的搬家,那类似与 Apple 在 iChat 中加入 Jabber 一样,无疑是个英明的决定。
三是希望能提供更好的 XML RPC 接口,与 Wordpress、Blogger 等大型 Blog 工具保持兼容,以更好支持本地应用。
四是能够更好地支持非 IE 和 Firefox 的浏览器,当然目前绝大多数功能对 Safari 支持得已经非常好,只是编辑框实在太“扁”了,而且在编辑框里必须手写 HTML,否则会把回车符丢掉,而且在编辑页面里添加新的分类也无法生效。希望能够自动识别一下浏览器并做出决定。
去掉了引用图片的 farm1
据称把 flickr 引用图片 URL 里的开头的 farm1. 去掉就可以使图片显示出来。
这么做了一下,果然如此。
看样子 G F W 封掉的只是 fam1 和 fam2。
这么做了一下,果然如此。
看样子 G F W 封掉的只是 fam1 和 fam2。
访问 Flickr
本月 8 日,全球最大在线图片供应网站 Flickr.com 出现“访问故障”,不少国内 Flickr 用户对此表示愤慨,Flickr Pro 付费用户也无法享受到应有的服务。
根据调查,flickr 中的图片服务器 http://farm1.static.flickr.com、http://farm2.static.flickr.com 均遇到“访问故障”问题,具体现象为页面可以打开,图片无法显示。
这里介绍两种访问 Flickr 的方法,一种是安装由一位同病相怜的伊朗人 Hamed Saber 所写的 Firefox 插件 Access Flickr!。
安装后,不会出现任何菜单或者按钮,但在访问 Flickr 时会自动选择到正确的地址。
另一种是可以在 hosts 文件里加上如下两行:
68.142.232.116 farm1.static.flickr.com
69.147.90.156 farm2.static.flickr.com
Windows 版的 hosts 文件一般位于 “C:\WINDOWS\system32\drivers\etc”。
Linux 的 hosts 文件位于 “/etc”。
Mac 暂时除了安装 Access Flickr! 或者带套上网(tor)以外暂时没有其它好办法。
根据调查,flickr 中的图片服务器 http://farm1.static.flickr.com、http://farm2.static.flickr.com 均遇到“访问故障”问题,具体现象为页面可以打开,图片无法显示。
这里介绍两种访问 Flickr 的方法,一种是安装由一位同病相怜的伊朗人 Hamed Saber 所写的 Firefox 插件 Access Flickr!。
安装后,不会出现任何菜单或者按钮,但在访问 Flickr 时会自动选择到正确的地址。
另一种是可以在 hosts 文件里加上如下两行:
68.142.232.116 farm1.static.flickr.com
69.147.90.156 farm2.static.flickr.com
Windows 版的 hosts 文件一般位于 “C:\WINDOWS\system32\drivers\etc”。
Linux 的 hosts 文件位于 “/etc”。
Mac 暂时除了安装 Access Flickr! 或者带套上网(tor)以外暂时没有其它好办法。
星际争霸 2
截图:http://media.pc.ign.com/media/850/850126/imgs_1.html
实际操作:http://tvpot.daum.net/clip/ClipView.do?clipid=2989055&lu=v_pop
实际操作:http://tvpot.daum.net/clip/ClipView.do?clipid=2989055&lu=v_pop
FlashDetection.handleEmbedCode("d1f89ce8-51dd-4890-8baa-708e6a680c76", '\x3cembed src\x3d\x22http\x3a\x2f\x2fv.blog.sina.com.cn\x2fswf\x2fplayer.swf\x3fvid\x3d3363048\x26amp\x3buid\x3d1168722094\x22 type\x3d\x22application\x2fx-shockwave-flash\x22 width\x3d475 height\x3d447 pluginspage\x3d\x22http\x3a\x2f\x2fwww.macromedia.com\x2fgo\x2fgetflashplayer\x22 allowscriptaccess\x3dnever allownetworking\x3dinternal\x3e', 'http\x3a\x2f\x2fcn4.sclive.net\x2f00.0.0000.0000\x2fWeb\x2fimages\x2fnoflash.gif');
超级的男性倾向,测测你的 Blog 是男是女?
来吧,测测你的 Blog 是男是女?
http://www.yodao.com/blogender/
当我输入了我的 blog 地址,大吃一惊,。

希望不是满篇的英文把 blogender 给吓倒了。
看样子我离小娘子的级别差别还是很远,但是“文风冷静而镇定,言语间展现出强悍的思辨能力与恢宏的胸襟”确实是鬼扯。
http://www.yodao.com/blogender/
当我输入了我的 blog 地址,大吃一惊,。
希望不是满篇的英文把 blogender 给吓倒了。
看样子我离小娘子的级别差别还是很远,但是“文风冷静而镇定,言语间展现出强悍的思辨能力与恢宏的胸襟”确实是鬼扯。
搬新家,装网络
挪地方了,从旧的小房间搬了出来,搬到了另一个小房间。
今天把网络弄好了,上来留个言。
最近大家都还好吗?
我很长时间都没有正式性地上网、聊天、灌水了,整天都忙碌于工作中,累啊,回家了就看看电视。
好在现在生活比较有规律,早上不迟到了,上班时也不会犯困了。
现在除了在维护 www.linux-ren.org,还在制作藏文版系统,以及 Everest 的龙芯版本。
找空我会把其中的一些心得贴上来。
就先说那么多了,下次再上来写点。
今天把网络弄好了,上来留个言。
最近大家都还好吗?
我很长时间都没有正式性地上网、聊天、灌水了,整天都忙碌于工作中,累啊,回家了就看看电视。
好在现在生活比较有规律,早上不迟到了,上班时也不会犯困了。
现在除了在维护 www.linux-ren.org,还在制作藏文版系统,以及 Everest 的龙芯版本。
找空我会把其中的一些心得贴上来。
就先说那么多了,下次再上来写点。
What I Have Lived For
What I Have Lived For
Bertrand Russell
Three passions, simple but overwhelmingly strong, have governed my life: the longing for love, the search for knowledge, and unbearable pity for the suffering of mankind. These passions, like great winds, have blown me hither and thither, in a wayward course, over a deep ocean of anguish, reaching to the verge of despair.
I have sought love, first, because it brings ecstasy --- ecstasy so great that I would have sacrificed all the rest of life for a few hours of this joy. I have sought it, next, because it relieves loneliness --- that terrible loneliness in which one shivering consciousness looks over the rim of the world into cold unfathomable lifeless abyss. I have sought it, finally, because in the union of love I have seen, in a mystic miniature, the prefiguring vision of the heaven that saints and poets have imagined. This is what I sought, and though it might seem too good for human life, this is what --- at last --- I have found.
With equal passion I have sought knowledge. I have wished to understand the hearts of men, I have wished to know why the stars shine. And I have tried to apprehend the Pythagorean power by which number holds away above the flux. A little of this, but not much, I have achieved.
Love and knowledge, so far as they were possible, led upward toward the heavens. But always pity brought me back to earth. Echoes of cries of pain reverberated in my heart. Children in famine, victims tortured by oppressors, helpless old people a hated burden to their sons, and the whole world of loneliness, poverty, and pain make a mockery of what human life should be. I long to alleviate the evil, but I cannot, and I too suffer.
This has been my life. I have found it worth living, and I would gladly live it again if the chance were offered to me.
我为何而活
伯兰特.罗素
三种简单却极其强烈的情感主宰着我的生活:对爱的渴望、对知识的追求、对人类痛苦的难以承受的怜悯之心。这三种情感,像一阵阵飓风一样,任意地将我吹的飘来荡去,越过痛苦的海洋,抵达绝望的彼岸。
我寻找爱,首先,因为它令人心醉神迷,这种沉醉是如此美妙,以至于我愿意用余生来换取那几个小时的快乐。我寻找爱,其次是因为它会减轻孤独,置身于那种可怕的孤独中,颤抖的灵魂在世界的边缘,看到冰冷的、死寂的、无底深渊。我寻找爱,还因为在爱水乳交融时,在一个神秘的缩影中,我见到了先贤和诗人们所想象的、预览的天堂。 这就是我所追求的,尽管对于凡人来说,这好像是一种奢望。但这是我最终找到的。
我曾以同样的热情来追求知识。我希望能理解人类的心灵,希望能知道为什么星星会发光。我也曾经努力理解毕达哥拉斯学派的理论,他们认为数字主载着万物的此消彼长。我了解了一点知识,但是不多。
爱和知识,可以最大可能地,将人带入天堂。可是,怜悯总是将我带回地面。人们因痛苦而发出的哭声在我心中久久回响,那些饥荒中的孩子们,被压迫者摧残的受害者们,被子女视为可憎负担的、无助的老人们,以及那无处不在的孤单、贫穷和无助都在讽刺着人类所本应该有的生活。我渴望能够消除人世间的邪恶,可是力不从心,我自己也同样遭受着它们的折磨。
这就是我的生活。我觉得活一场是值得的。如果给我机会的话,我愿意开心地,再活一次。
伯兰特.罗素(1872-1970),英国著名哲学家、数学家和文学家。他在多个领域都取得了巨大成就。他所著的《西方的智慧》、《西方哲学史》对中国读者影响很大。
A distribution system design
How do you wonder when you have more than two computers?
I have a workstation and a laptop, the workstation built-in the newest Core 2 Duo 2.4G with great performance, and the laptop is a Apple Powerbook 1.67.
Both system running on a Gentoo Linux, I shared resources between them.
/* Waiting for continue */
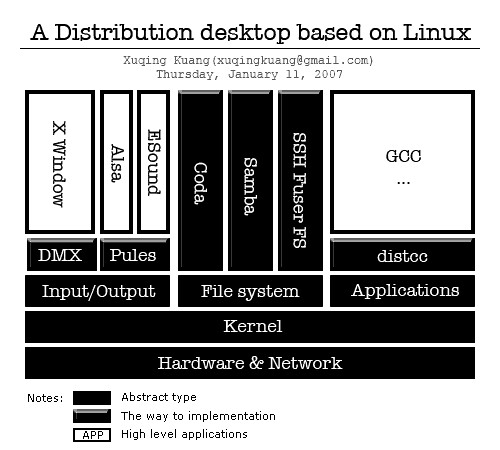
I have a workstation and a laptop, the workstation built-in the newest Core 2 Duo 2.4G with great performance, and the laptop is a Apple Powerbook 1.67.
Both system running on a Gentoo Linux, I shared resources between them.
/* Waiting for continue */
Optimization DRI for double performance
X have some options for better work, most time X just use the universality options for run on most computer.
But you can tweak them. With the best result, you will get the double performance.
My system is Gentoo 2006.1 with X.org Server 1.1.1-r3 and xf86-video-ati 6.6.3 with DRI(Direct Render Interface), also I have the beryl 0.1.4 and AIXGL for the 3D desktop test.
Hardware is Powerbook pre-High definition, G4 1.67 and ATI 9700 with 128M.
Let's see the default Display adapter configuration.
Section "Device"
Identifier "Card0"
Driver "ati"
VendorName "ATI Technologies Inc"
BoardName "RV350 [Mobility Radeon 9600 M10]"
EndSection
The frames per seconds benchmark with glxgear looks like below.
Add some options in this device section for tweak.
Option "AGPMode" "4"
Option "UseFBDev" "false"
Option "AGPFastWrite" "true"
Option "EnablePageFlip" "true"
Option "DynamicClocks" "true"
Option "RenderAccel" "true"
Let's bechmark and see it again.
Wow. double performance !
How about these options works in the full hardware acceleration berly ?

Oh, it back to half and unstable. But I think it's the free ati driver's problem.
I feel Intel's GMA series open source driver is much better and stable than it, I will also test it if I have time.
OK, What's these options and value means ?
Option "AGPMode" "4"
AGPMode define the bandwidth of the AGP bus, the 4 means 4 times than the default AGP bus bandwidth, the defualt AGP running on 66Mhz with 266MB/s bandwidth, and Xorg will auto decide in 1X in default, you can tweak this option for more bandwith, the highest value of this option is 8 but it's need you conform your hardware support it.
Option "UseFBDev" "false"
It's a IMPORTANT option.
Most display adapter support and universal driver mode called framebuffer. It create a spool in memery and map it to the screen pixel, it's a FB device. Xorg write data into this spool, and the the driver read from this spool and write the data to the screen. it's not fully optimized.
ATI driver support a DMA(Direct Memery Access) mode, Xorg can write the data into the memory of the display adapter, it means Xorg can write to screen skip the memory spool of the FB device.
Option "AGPFastWrite" "true"
Fast write option looks like FBDev, I't also a memery access mode of display adapter.
It's skip memory access and write data to display adapter directly.
Option "EnablePageFlip" "true"
Enable Page Flip will increases performance, it tweak the memory access mode.
This option will be disabled if EAX architecture is in used.
Option "DynamicClocks" "true"
DynamicClock is "Intel SpeedStep" technology for display chips. it adjust the performance of display adapter only for save energy.
Option "RenderAccel" "true"
RenderAccel looks like it name, enable it for Render Acceleration Mode.
This option is default enabled.
Other options will increases performance more, I will do more around it and blog it more.
But you can tweak them. With the best result, you will get the double performance.
My system is Gentoo 2006.1 with X.org Server 1.1.1-r3 and xf86-video-ati 6.6.3 with DRI(Direct Render Interface), also I have the beryl 0.1.4 and AIXGL for the 3D desktop test.
Hardware is Powerbook pre-High definition, G4 1.67 and ATI 9700 with 128M.
Let's see the default Display adapter configuration.
Section "Device"
Identifier "Card0"
Driver "ati"
VendorName "ATI Technologies Inc"
BoardName "RV350 [Mobility Radeon 9600 M10]"
EndSection
The frames per seconds benchmark with glxgear looks like below.
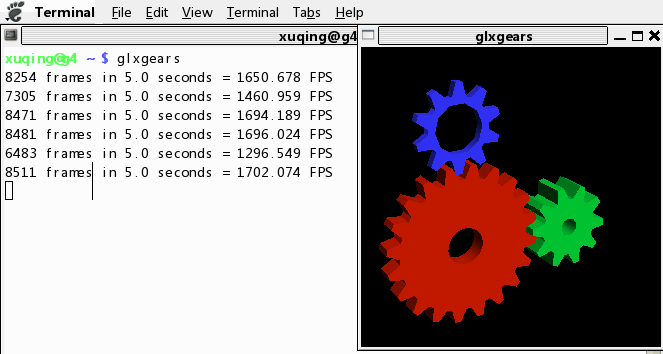
Add some options in this device section for tweak.
Option "AGPMode" "4"
Option "UseFBDev" "false"
Option "AGPFastWrite" "true"
Option "EnablePageFlip" "true"
Option "DynamicClocks" "true"
Option "RenderAccel" "true"
Let's bechmark and see it again.

Wow. double performance !
How about these options works in the full hardware acceleration berly ?
Oh, it back to half and unstable. But I think it's the free ati driver's problem.
I feel Intel's GMA series open source driver is much better and stable than it, I will also test it if I have time.
OK, What's these options and value means ?
Option "AGPMode" "4"
AGPMode define the bandwidth of the AGP bus, the 4 means 4 times than the default AGP bus bandwidth, the defualt AGP running on 66Mhz with 266MB/s bandwidth, and Xorg will auto decide in 1X in default, you can tweak this option for more bandwith, the highest value of this option is 8 but it's need you conform your hardware support it.
Option "UseFBDev" "false"
It's a IMPORTANT option.
Most display adapter support and universal driver mode called framebuffer. It create a spool in memery and map it to the screen pixel, it's a FB device. Xorg write data into this spool, and the the driver read from this spool and write the data to the screen. it's not fully optimized.
ATI driver support a DMA(Direct Memery Access) mode, Xorg can write the data into the memory of the display adapter, it means Xorg can write to screen skip the memory spool of the FB device.
Option "AGPFastWrite" "true"
Fast write option looks like FBDev, I't also a memery access mode of display adapter.
It's skip memory access and write data to display adapter directly.
Option "EnablePageFlip" "true"
Enable Page Flip will increases performance, it tweak the memory access mode.
This option will be disabled if EAX architecture is in used.
Option "DynamicClocks" "true"
DynamicClock is "Intel SpeedStep" technology for display chips. it adjust the performance of display adapter only for save energy.
Option "RenderAccel" "true"
RenderAccel looks like it name, enable it for Render Acceleration Mode.
This option is default enabled.
Other options will increases performance more, I will do more around it and blog it more.
Happy new year

In the past 2006, we done a lot of inconceivable and unforgettable things.
In the new 2007, we will do our best as before !
The first snowing of Beijing in 2006

Snow, originally uploaded by K*K.
Today, after I weaked up, I saw outside is snowing, everythings are all white in last night.
It's so beautiful.
Are there anything better than watch out snowing outside in a warm room ?
What should I can do in holiday ? I'm thinking.
Ask some friends to go to make a snow-guy?
or go to skiing ? ^_^
Happy holiday buddies !
Replace my HD of Powerbook.
I'm using a Powerbook 17" for home and working. It was bought from Oct 2005.
It built-in a Seagate 5400.2 100G hard driver.

But I feel some problem in it, the program can't write file in it sometimes, and there's no any error reported, just hang hang and hang,
I think maybe there are some bad block in it.
So I bought another Hitachi 5K120 120G HD to replace it,

I disassembly the powerbook with THIS GUIDE.
With a lot of work, the inside show to my eye.


After assembly it, I clone my operating system in old disk into the new one, and start the system normaly.
How about the old disk, It's not broken that unrepairable, I repartition it and only use 80G of it, I bought a Datastorage PD2500 and put old harddriver into it.
I will store my movies in it. -)


It built-in a Seagate 5400.2 100G hard driver.
But I feel some problem in it, the program can't write file in it sometimes, and there's no any error reported, just hang hang and hang,
I think maybe there are some bad block in it.
So I bought another Hitachi 5K120 120G HD to replace it,
I disassembly the powerbook with THIS GUIDE.
With a lot of work, the inside show to my eye.
After assembly it, I clone my operating system in old disk into the new one, and start the system normaly.
How about the old disk, It's not broken that unrepairable, I repartition it and only use 80G of it, I bought a Datastorage PD2500 and put old harddriver into it.
I will store my movies in it. -)
COCOTRON
Cocotron 是由 Christopher Lloyd 编写的一套,相当于 Mac OS X AppKit 和 Foundation 在其它平台上的实现,通过它使用 Objective C 编译器将能够同时在 Mac OS X/Windows/Linux 上运行。
想法很好,但是问题是,Mac OS X 的菜单位于屏幕顶端,其它平台的菜单一般在窗口的标题栏下。
我还没试,先不乱猜测。
Right here: http://www.cocotron.org

想法很好,但是问题是,Mac OS X 的菜单位于屏幕顶端,其它平台的菜单一般在窗口的标题栏下。
我还没试,先不乱猜测。
Right here: http://www.cocotron.org
土话:Merry Christmas and Happy new year ;-)
在遥远的 2000 多年前,一个住在天上上叫耶和华的帅男和地上的叫玛利亚的靓女嘿咻嘿咻,
于是乎,十个月后,马厩里的“圣”便诞生了。
于是乎,几百年后,我们称之为圣诞节。
祝各位嘿咻快乐。

于是乎,十个月后,马厩里的“圣”便诞生了。
于是乎,几百年后,我们称之为圣诞节。
祝各位嘿咻快乐。
gxemul 0.4.3 loongson patch
1:diff -Naur gxemul-0.4.3.orig/debian/changelog gxemul-0.4.3/debian/changelog
2:--- gxemul-0.4.3.orig/debian/changelog 1970-01-01 08:00:00.000000000 0800
3: gxemul-0.4.3/debian/changelog 2006-11-09 23:41:33.000000000 0800
4:@@ -0,0 1,134 @@
5: gxemul (0.4.3-1) unstalbe; urgency=low
6:
7: * New upstream release.
8:
9: -- Liangjin Peng <penglj@lemote.com> Thu, 09 Nov 2006 15:38:20 0000
10:
11: gxemul (0.4.2-2) unstable; urgency=low
12:
13: * debian/rules: Use -O0 on m68k to avoid a gcc ICE (closes: #381039).
14:
15: -- G ran Weinholt <weinholt@debian.org> Sat, 26 Aug 2006 20:41:20 0200
......
Download from my box: http://www.box.net/public/db9dx205gq in /Patches/gxemul/ directory.
The orignal gxemul emulator source code is from http://gavare.se/gxemul/.
Native GTK running on Mac OS X
Native GTK running on Mac OS X, originally uploaded by K*K.
Successful running GTK 2.11 2006/12/21 cvs version on Mac OS X, no X11, no more requirements!
Plan:
1. Try to rebuild GTK with nquartz(Quartz Native) target, hope that GTK widget will looks like Aqua Widgets.
2. Merge Mac OS X like top menu patch in this version of GTK .
I recommend you to build it with a script gtk-osx-build.sh, you can download it from: http://www.box.net/public/db9dx205gq.
Want to learn how to port GTK to Mac OS X, you can download Porting-Gtk-MacOSX.pdf guide by Anders Carlsson from my box Documents folder.
个人的时代(草稿)
起这个题目,要放在以人民公社为社会单位的年代,无疑是要受点惩罚的。
但不可否认,在上一次网络泡沫消逝之后,新的一轮 Web 2.0 又很“莫名其妙”地成为了风头浪尖,与上一次因为技术的高速发展所造成狂热相比,这次由 Youtube、Flickr、Instructables 等等所谓 Web 2.0 社区所带来的,是给个人提供的舞台,提供了对个人能力的充分发挥和展现的机会。
个人的能力能有多大?这对于生长在红旗下的我们来说,无疑是个 XX,就政治课本而言,其中所描述的、宣传的社会主义社会性质,是一个人人为同一个目标为努力的社会,而从实际生活而言,确实独立行动对于个人而言,也似乎是非常遥远的,我们从小便按照国家、父母所制定好的计划行动着-前者是”努力学习本领,向着社会主义进发“,后者是“努力靠上大学,混个好工作,有个好钱途”,社会上的机会是很多的,但似乎没人问过我们-以一个个人的身份,愿意将自己的能力发挥到哪里?
但就学习内容而言,缺乏团队合作的学习和考试内容,又将个人的能力完全分隔,而毫无“人人努力向一个目标”的实质,所剩下的,也仅仅是从前作为学生的我们,将自己的能力无法凝聚在一起,各自应付自己“该应付的事情”-“考试”。学校里唯一能发挥团队精神的,可能就是春游和体育了,但作为学生真正的实际利益-考试,在那里放着,这种周边的团队精神是真实的吗?。可是不幸的是,正是这种很扭曲的“个人主义”,在真正走向社会后,被社会上的社会困难逐一击破了。
个人的能里能有多大?从前作为个人无法将自己的能力完全释放,很大一个因素是生产资料,从前政治书中就有写:资本家掌握生产资料,没有生产资料的无产阶级无法生产生活资料,只有家自己作为劳动力卖给资本家。
没有 DV,没办法 Youtube;没有相机,没办法 flickr;没有胶水钳子螺丝刀,Instructables 就算了;没有电脑和网络,前面三个一起白搭。好在现在工具措手可得,虽然从前一些工具依然能够得到,可是还有一个很大的问题 - 报纸、电视、电台等传媒都被把持,做出来也没人知道。而电脑和网络的兴起,对推动个人水平的发展,才真正起到了关键作用,进而推进了社会的进步,时代的进步显而易见。
个人的能力如何发挥?
。。。。
这就是《时代周刊》2006 年年度人物:你
你的能力能有多大?这只能看你自己,舞台,已经为你准备好了。

但不可否认,在上一次网络泡沫消逝之后,新的一轮 Web 2.0 又很“莫名其妙”地成为了风头浪尖,与上一次因为技术的高速发展所造成狂热相比,这次由 Youtube、Flickr、Instructables 等等所谓 Web 2.0 社区所带来的,是给个人提供的舞台,提供了对个人能力的充分发挥和展现的机会。
个人的能力能有多大?这对于生长在红旗下的我们来说,无疑是个 XX,就政治课本而言,其中所描述的、宣传的社会主义社会性质,是一个人人为同一个目标为努力的社会,而从实际生活而言,确实独立行动对于个人而言,也似乎是非常遥远的,我们从小便按照国家、父母所制定好的计划行动着-前者是”努力学习本领,向着社会主义进发“,后者是“努力靠上大学,混个好工作,有个好钱途”,社会上的机会是很多的,但似乎没人问过我们-以一个个人的身份,愿意将自己的能力发挥到哪里?
但就学习内容而言,缺乏团队合作的学习和考试内容,又将个人的能力完全分隔,而毫无“人人努力向一个目标”的实质,所剩下的,也仅仅是从前作为学生的我们,将自己的能力无法凝聚在一起,各自应付自己“该应付的事情”-“考试”。学校里唯一能发挥团队精神的,可能就是春游和体育了,但作为学生真正的实际利益-考试,在那里放着,这种周边的团队精神是真实的吗?。可是不幸的是,正是这种很扭曲的“个人主义”,在真正走向社会后,被社会上的社会困难逐一击破了。
个人的能里能有多大?从前作为个人无法将自己的能力完全释放,很大一个因素是生产资料,从前政治书中就有写:资本家掌握生产资料,没有生产资料的无产阶级无法生产生活资料,只有家自己作为劳动力卖给资本家。
没有 DV,没办法 Youtube;没有相机,没办法 flickr;没有胶水钳子螺丝刀,Instructables 就算了;没有电脑和网络,前面三个一起白搭。好在现在工具措手可得,虽然从前一些工具依然能够得到,可是还有一个很大的问题 - 报纸、电视、电台等传媒都被把持,做出来也没人知道。而电脑和网络的兴起,对推动个人水平的发展,才真正起到了关键作用,进而推进了社会的进步,时代的进步显而易见。
个人的能力如何发挥?
。。。。
这就是《时代周刊》2006 年年度人物:你
你的能力能有多大?这只能看你自己,舞台,已经为你准备好了。
龙梦盒子 Municator 相片
通过公司的销售部门,我们拿到龙梦盒子。
机器是由厦门设计的 Municator,在市场上售价为 149 美元。
机器的配置是:
CPU: 龙芯 2E 666Mhz
内存: 256M
硬盘: 40G 笔记本硬盘
显卡:ATI Radeon 7000
芯片组:自行研发的北桥 VIA VT686 南桥
网卡:Realtek 8139
USB: 四个 USB 2.0
该机试用性能满意,应用主要以 Linux 和开源软件为主。
简单做了个 nbench 测试:
http://www.kuangxuqing.com/2006/10/nbench.html





机器是由厦门设计的 Municator,在市场上售价为 149 美元。
机器的配置是:
CPU: 龙芯 2E 666Mhz
内存: 256M
硬盘: 40G 笔记本硬盘
显卡:ATI Radeon 7000
芯片组:自行研发的北桥 VIA VT686 南桥
网卡:Realtek 8139
USB: 四个 USB 2.0
该机试用性能满意,应用主要以 Linux 和开源软件为主。
简单做了个 nbench 测试:
http://www.kuangxuqing.com/2006/10/nbench.html
音乐之声
Let's start at the very beginning
A very good place to start
When you read you begin with
A, B, C
When you sing, you begin with
Do-Re-Mi
Do-Re-Mi
The first three notes just happen to be
Do-Re-Mi
Do-re-mi-fa-so-la-ti
"Doe," a deer
A female deer
"Ray" a drop of golden sun
"Me" a name I call myself
"Far" a long long way to run
"Sew" a needle pulling thread
"La" a note to follow sew
"Tea" a drink with jam and bread
That will bring us back to doe

A very good place to start
When you read you begin with
A, B, C
When you sing, you begin with
Do-Re-Mi
Do-Re-Mi
The first three notes just happen to be
Do-Re-Mi
Do-re-mi-fa-so-la-ti
"Doe," a deer
A female deer
"Ray" a drop of golden sun
"Me" a name I call myself
"Far" a long long way to run
"Sew" a needle pulling thread
"La" a note to follow sew
"Tea" a drink with jam and bread
That will bring us back to doe
龙芯的人来联系了
你好:
我是龙芯产业联盟的管理员 ,听说你有意做龙梦电脑的everest移植项目,非常高兴。我和龙梦的市场人员有直接的联系。我可以帮你这个忙。你要几台?请和我联系
我的QQ XXXXXXXXX MSN XXXXXXX@hotmail.com 这个星期龙梦就要选定测试的人员。请尽快和我联系。
--
龙芯产业化联盟隶属于信息产业部,依托中科院计算所。以龙芯CPU技术为龙头,以中科院计算所为依托,以国内优秀企业为骨干,联合国内的各类应用技术研究发展单位、集成单位,重点是政府、教育、军事的研、产机构及广大用户,形成国产关键技术的强大推动力、强壮的产业链。有效扩大联盟成员在产业链上不同层次的市场份额及行业用户的有效规模化应用。
联盟网站www.china-cpu.org
论坛www.china-cpu.org/bbs
官方博客http://longxin2010.blog.sohu.com/
看来有事情做了。
经过申请,移植 Everest 到 MIPS 架构上的工作就交给我了。
以后的日志将以这个工作为主。
转一个:小资-愤青-朋克-歌特
小资是风筝,样式艺术,结构科学,个性多样,接近高贵,有文化根基,懂得借风而翔,且总有有一个理智的原则栓绑,收放自如,不易丧失自我
愤青是气球,色彩形状皆大同小异,都充满怒气,弹性也能导致易破的脆弱,越飞越高的最终气炸了,飞不起来的直到泄气光光,他们看似无拘无束,实则难控自己
朋克是羽毛,被原有的生命体放弃,然后沾染污浊,行迹多变,如美丽的死魂,又不完全是垃圾,有一天再也飞不动,等待变成灰粒,更也许在此之前就扑火燃尽.
歌特是凋落的花瓣,花瓣原本没凋谢前,争奇斗艳,但这只是误落尘网中,当她明白了自己的意义时,她离开了世俗,不再鲜艳,她的心灵暗淡了,不再有艳丽俗气的色彩,属于她的只有黑色,在夜空里随着阴风而舞
小资讲究行为艺术.
愤青讲究行为准则
朋克讲究行为随意.
歌特讲究行为黑暗
小资的理想中有自保的安逸,习惯动作是抚头发.
愤青的理想中有冲动的秉性,习惯动作是挽袖子.
朋克没理想.
歌特的理想中有黑色的暗潮,习惯动作是补妆
小资最复杂,但很少有人觉得他们狡猾.
愤青最表面,但很少有人觉得他们无知.
朋克最单纯,但很少有人觉得他们可爱.
歌特最高贵,但很少有人觉得他们是人
小资看完一部电影,懂得了小资变成色狼也像正人君子,他看《云上的日子》
愤青看完一部电影,剃了个莫西干发型,他看的是《出租车司机》.
朋克看完一部电影,生气地大叫“我马桶竟然不是最脏的”,他看《猜火车》
歌特看完一部电影,将杯中的红酒徐徐饮下,他看《钢琴教师》
小资看奥斯卡,是因为他看不懂柏林电影节.
愤青看奥斯卡,是因为他想连续骂3个多小时.
朋克看奥斯卡,是因为想听里面的黄色笑话.
歌特看奥斯卡,是因为他没有看过
恋爱.
小资女 小资男=三天分手
小资女 愤青男=世上又多了一个傻小子
小资女 朋克男=又一个朋克女诞生
小资女 歌特男=小资女疯了
愤青女 小资男=愤青男 小资女
愤青女 愤青男=超级愤青完美情侣组
愤青女 朋克男=互殴
愤青女 歌特男=愤青女变成喜欢工业歌特的歌特女
朋克女 小资男=朋克女 另外一个男的
朋克女 愤青男=愤青男哭了
朋克女 朋克男=爱情消失欲望实现
朋克女 歌特男=俩人都会变得后朋克(Post-Punk)
歌特女 小资男=小资男疯了
歌特女 愤青男=愤青男变成喜欢工业歌特的歌特男
歌特女 朋克男=朋克女 歌特男
歌特女 歌特男=哦,天哪……
小资很懂得养生之道.
愤青只管练一身肌肉.
朋克根本就不想长寿.
歌特已经死了
小资的早餐既营养又方便.
愤青不吃早餐.
朋克早上不起.
歌特一边优雅地吃早饭一边优雅地欣赏音乐
小资喝咖啡是因为已经上瘾.
愤青喝咖啡是因为有人给了他一包咖啡.
朋克喝咖啡是为了在自己家里倒时差.
歌特喝咖啡是因为个人的品位修养是这样
小资骑自行车时想的是,有朝一日我要开宝马.
愤青骑自行车时想的是,全世界骑自行车的无产者万岁.
朋克骑自行车时想的是,这自行车是谁的呀?
歌特不会这么多世俗想法……
小资戴着耳机,很可能什么都没听,而是在装酷.
愤青戴着耳机听的什么,你离他五米都能听到 -- 摇滚版的.
朋克自己就是个大音箱.
歌特听音乐时不希望被人打扰,所以别的歌特是怎样的,我不知道
50岁的邻居老太太经常能看到对门的小资,象看见一个"栋梁".
60岁的邻居老太太偶尔能看到对门的愤青,于是总想报警.
70岁的邻居老太太突然有一天发现对门住的朋克,以为撞到了鬼,吓疯了,被救护车连同朋克一起送进了精神病院.
后来这位老太太见到了歌特,才知道什么是鬼……
原文:http://www.elesson.com.cn/modules/ipboard/index.php?showtopic=39530
迁移到了 typo
现在已经是 typo 了,全站基于 ruby on rails。
方案是 apache scgi。
但是 scgi 依然有问题,主要出在 RoR 将 app 作为静态网页来处理,可是什么东西应该发给 scgi/Ror 当作 app 处理,什么真正的静态文件该直接交给 web server 处理,这就成了一个问题。
目前采取的方法是,将所有带有扩展名的文件(文件名中包含一个 dot)都交给 webserver 直接处理:
# matches locations with a dot following at least one more characters,
# that is, things like *,html, *.css, *.js,
# which should be delivered directly from the filesystem.
< LocationMatch \.. $ >
# don't handle those with SCGI
SCGIHandler Off
< /LocationMatch >
但是这样出现了一个问题,即:主题怎么办?
主题文件都存放在 RoR 的 themes 目录里,除非直接拷贝到 public 目录里,否则 web server 无法获取到 theme 中的 css 图片,因为它们的文件名中有一个 dot,但如果真拷贝过去,又失去了更换主题的意义。
主题可以依靠直接复制文件,订死文件路径来解决。可是自动生成的 rss,包含两个带有 dot 的文件 - atom.xml 和 feed.xml 怎么办?
目前在网上似乎没看到有真正完美的解决办法,关键问题在于 Ruby 发展了多年依然缺乏一个好的容器,和 apache 交互竟然依然使用 cgi 的方式。
已经快四点了,剩下的事情明天该继续整理。
要尝鲜总要付出点代价,像 Leopard Developer Preview 的输入法很不稳定,本文写了一次可到结尾崩溃了,才注意到 Typo 缺乏一个利用 cookies 自动保存内容的功能(Wordpress 有插件可以做到这点)。
等这事情完成,要写篇长长的教程。
如果觉得页面太过与简洁了,可以看看 mongrel 下的表现力,这需要连接 4905 端口:
http://www.kuangxuqing.com:4905/
方案是 apache scgi。
但是 scgi 依然有问题,主要出在 RoR 将 app 作为静态网页来处理,可是什么东西应该发给 scgi/Ror 当作 app 处理,什么真正的静态文件该直接交给 web server 处理,这就成了一个问题。
目前采取的方法是,将所有带有扩展名的文件(文件名中包含一个 dot)都交给 webserver 直接处理:
# matches locations with a dot following at least one more characters,
# that is, things like *,html, *.css, *.js,
# which should be delivered directly from the filesystem.
< LocationMatch \.. $ >
# don't handle those with SCGI
SCGIHandler Off
< /LocationMatch >
但是这样出现了一个问题,即:主题怎么办?
主题文件都存放在 RoR 的 themes 目录里,除非直接拷贝到 public 目录里,否则 web server 无法获取到 theme 中的 css 图片,因为它们的文件名中有一个 dot,但如果真拷贝过去,又失去了更换主题的意义。
主题可以依靠直接复制文件,订死文件路径来解决。可是自动生成的 rss,包含两个带有 dot 的文件 - atom.xml 和 feed.xml 怎么办?
目前在网上似乎没看到有真正完美的解决办法,关键问题在于 Ruby 发展了多年依然缺乏一个好的容器,和 apache 交互竟然依然使用 cgi 的方式。
已经快四点了,剩下的事情明天该继续整理。
要尝鲜总要付出点代价,像 Leopard Developer Preview 的输入法很不稳定,本文写了一次可到结尾崩溃了,才注意到 Typo 缺乏一个利用 cookies 自动保存内容的功能(Wordpress 有插件可以做到这点)。
等这事情完成,要写篇长长的教程。
如果觉得页面太过与简洁了,可以看看 mongrel 下的表现力,这需要连接 4905 端口:
http://www.kuangxuqing.com:4905/
一波未平,一波又起
话说 beta.blogger.com 被封还未解决,刚发现 google pages 的服务也被保护了。
难怪 js 和 css 们怎么都一个个无法获取,页面干净得就只剩下了 li。
解决 beta blogger 找到一个办法,在 hosts 文件里加入 :
72.14.219.190 beta.blogger.com
Linux/Mac/Unix 的 hosts 文件就在 /etc 下
Windows 的在 c:\windows\system32\drivers\etc
以后每次登陆都会利用 https 连接,以绕过伟大的 G F W。
google pages 没救了,只好把静态的文件都上传到服务器上,改好 template 上的路径,发现行间距宽了,凑合着先用吧。
但是普通用户如果不改 hosts 文件,就无法回复了(火星人同志在奥地利还是比较好办的 :-p),
昨晚折腾 typo 中,使用了 apache SCGI 的方案,因为借用好朋友的服务器,不敢有大动作。
不过发生了 500 错误,再者考虑 typo 如何导入 blogger,需要摸索一下。
本机上使用 typo 倒是非常顺利,使用了 mongrel,可以看下截图,typo 可是非常漂亮的:
想用 typo 的理由:
1. 趁机学一把 ruby on rails。
2. typo 很酷!自带的 Live Search 迷死了包括小火星在内的不少人,当然还有我 :-p
3. wordpress 已经腻味了,自身功能弱,还要去找插件,麻烦。
4. 这东西就是给 safari 玩的。
不想用 typo 的理由:
1. 自己搞了套 xmlrpc,flickr 和 drivel/echo 等程序都不支持了。
2. 打算使用 sqlite,备份起来简单,可是以后数据库迁移就麻烦了,使用 mysql 的话如果空间又崩了怎么办?
3. ruby 目前依然使用 byte code,对 unicode 支持不好。
4. 在这种不成熟的东西上,碰上麻烦了怎么办?
先自己试试,如果 ok,就写一篇《如何让自己的 blog 具有可移植性》 ;-)
难怪 js 和 css 们怎么都一个个无法获取,页面干净得就只剩下了 li。
解决 beta blogger 找到一个办法,在 hosts 文件里加入 :
72.14.219.190 beta.blogger.com
Linux/Mac/Unix 的 hosts 文件就在 /etc 下
Windows 的在 c:\windows\system32\drivers\etc
以后每次登陆都会利用 https 连接,以绕过伟大的 G F W。
google pages 没救了,只好把静态的文件都上传到服务器上,改好 template 上的路径,发现行间距宽了,凑合着先用吧。
但是普通用户如果不改 hosts 文件,就无法回复了(火星人同志在奥地利还是比较好办的 :-p),
昨晚折腾 typo 中,使用了 apache SCGI 的方案,因为借用好朋友的服务器,不敢有大动作。
不过发生了 500 错误,再者考虑 typo 如何导入 blogger,需要摸索一下。
本机上使用 typo 倒是非常顺利,使用了 mongrel,可以看下截图,typo 可是非常漂亮的:
想用 typo 的理由:
1. 趁机学一把 ruby on rails。
2. typo 很酷!自带的 Live Search 迷死了包括小火星在内的不少人,当然还有我 :-p
3. wordpress 已经腻味了,自身功能弱,还要去找插件,麻烦。
4. 这东西就是给 safari 玩的。
不想用 typo 的理由:
1. 自己搞了套 xmlrpc,flickr 和 drivel/echo 等程序都不支持了。
2. 打算使用 sqlite,备份起来简单,可是以后数据库迁移就麻烦了,使用 mysql 的话如果空间又崩了怎么办?
3. ruby 目前依然使用 byte code,对 unicode 支持不好。
4. 在这种不成熟的东西上,碰上麻烦了怎么办?
先自己试试,如果 ok,就写一篇《如何让自己的 blog 具有可移植性》 ;-)
千万不要升级到 blogger beta
blogger beta 总算能够正常使用了,昨天就看到了 blogger 管理界面上大大的邀请各位帅哥赶紧 switch 的通告。
只是因为 beta.blogger.com 被伟大的 G F W 保护了,下班前利用 tor 连上了并点击了转换。
到家时收到 email 已经转换完了。
blogger beta 的新功能暂且不提,就提提转换后的不幸。
首先是-body 后面强制加上了 blogger 的 navbar。
在以前的 blogger 里,navbar 是可以隐藏掉的,一般第三方的 template 里都有那么一行:
/************** REMOVE THIS TO UNHIDE THE BLOGGER NAVBAR ****************
**/ #b-navbar {height:0px;visibility:hidden;display:none} /**
*************************************************************************
可是现在无论你加与不加,body 属性后面都紧跟一个 navbar 的 iframe
< iframe src="http://beta.blogger.com/navbar.g?blogID=xxxxxxxx"
marginwidth="0"
marginheight="0"
id="navbar-iframe"
frameborder="0"
height="30"
scrolling="no"
width="100%">
< /iframe >
< div id="space-for-ie" >
< /div>
忍了。
更糟的是-publish 的网页里加上了几个 blogger beta 上才有的 css 和 js:
< style type="text/css" >
< br / >
@ import url("http://beta.blogger.com/css/blog_controls.css");
< br / >
@ import url("http://beta.blogger.com/dyn-css/authorization.css?blogID=xxxxxxxx");
< br / >
< /style >
< script type="text/javascript" src="http://beta.blogger.com/js/backlink.js">< /script >
< script type="text/javascript" src="http://beta.blogger.com/js/backlink_control.js">< /script >
< script type="text/javascript">
var BL_backlinkURL = "http://beta.blogger.com/dyn-js/backlink_count.js";var BL_blogId = "xxxxxxxx";
< /script >
< style type="text/css" >
@ import url(http://beta.blogger.com/css/navbar/classic.css);
div.b-mobile {display:none;}
< br />
< /style >
而 beta.blogger.com 在国内是被封掉的。现在打开网页,浏览器会上 beta.blogger.com 上请求文件,因为获取不到,只有等待超时,结果国内的朋友打开网页速度巨慢,打开以后也是没有样式的。
最要命的是-凡是 switch 到新 beta blogger 的用户都无法回到以前的 -_-#
这不是逼着我上 Typo 嘛。 -_-#
只是因为 beta.blogger.com 被伟大的 G F W 保护了,下班前利用 tor 连上了并点击了转换。
到家时收到 email 已经转换完了。
blogger beta 的新功能暂且不提,就提提转换后的不幸。
首先是-body 后面强制加上了 blogger 的 navbar。
在以前的 blogger 里,navbar 是可以隐藏掉的,一般第三方的 template 里都有那么一行:
/************** REMOVE THIS TO UNHIDE THE BLOGGER NAVBAR ****************
**/ #b-navbar {height:0px;visibility:hidden;display:none} /**
*************************************************************************
可是现在无论你加与不加,body 属性后面都紧跟一个 navbar 的 iframe
< iframe src="http://beta.blogger.com/navbar.g?blogID=xxxxxxxx"
marginwidth="0"
marginheight="0"
id="navbar-iframe"
frameborder="0"
height="30"
scrolling="no"
width="100%">
< /iframe >
< div id="space-for-ie" >
< /div>
忍了。
更糟的是-publish 的网页里加上了几个 blogger beta 上才有的 css 和 js:
< style type="text/css" >
< br / >
@ import url("http://beta.blogger.com/css/blog_controls.css");
< br / >
@ import url("http://beta.blogger.com/dyn-css/authorization.css?blogID=xxxxxxxx");
< br / >
< /style >
< script type="text/javascript" src="http://beta.blogger.com/js/backlink.js">< /script >
< script type="text/javascript" src="http://beta.blogger.com/js/backlink_control.js">< /script >
< script type="text/javascript">
var BL_backlinkURL = "http://beta.blogger.com/dyn-js/backlink_count.js";var BL_blogId = "xxxxxxxx";
< /script >
< style type="text/css" >
@ import url(http://beta.blogger.com/css/navbar/classic.css);
div.b-mobile {display:none;}
< br />
< /style >
而 beta.blogger.com 在国内是被封掉的。现在打开网页,浏览器会上 beta.blogger.com 上请求文件,因为获取不到,只有等待超时,结果国内的朋友打开网页速度巨慢,打开以后也是没有样式的。
最要命的是-凡是 switch 到新 beta blogger 的用户都无法回到以前的 -_-#
这不是逼着我上 Typo 嘛。 -_-#
Blogger beta 完成了。
体检结果:一切正常,心跳 88 次/分,稍微偏快,惊喜是身高到了 1.81,体重恢复到了 66 公斤。 :-D
周二晚上俺崩溃了,今晚把日志评选补上。
哎,自己心态不好,多锻炼就是,少怪别人,多想想自己。
失去了其实也没什么可埋怨的,得到了就多加珍惜,还是继续等待属于自己的降临吧。
火星人:今天一上来就看见 blogger 催促着要迁移到 beta blogger 了,找空要看一下。
啥时候把 blog 系统升到 Typo - Ruby on Rails 的 Blog platform ?
周二晚上俺崩溃了,今晚把日志评选补上。
哎,自己心态不好,多锻炼就是,少怪别人,多想想自己。
失去了其实也没什么可埋怨的,得到了就多加珍惜,还是继续等待属于自己的降临吧。
火星人:今天一上来就看见 blogger 催促着要迁移到 beta blogger 了,找空要看一下。
啥时候把 blog 系统升到 Typo - Ruby on Rails 的 Blog platform ?
摩登时代
看过片花,一直以为它是一部讽刺片,直到今天才知道它同样饱含了温情。
看周星驰的电影,都说是欢笑里面夹着眼泪。
而这部卓别林拍摄于 1936 年的电影,却更加接近于今天的普通人的生活。
没有周电影的跌荡起伏,没有周电影中的盖世神功。
仅仅是在普通人的小幸福、小成就、小灾小难中徘回,
但始终能从他所扮演的小人物身上看见自己的影子。
英国诗人布莱尔有一句:滴水见世界,朵花见天堂。
同样的东西不同的人看了都有不同的感觉,如果有时间,鼓励看一下。
卓别林-《摩登时代》

看周星驰的电影,都说是欢笑里面夹着眼泪。
而这部卓别林拍摄于 1936 年的电影,却更加接近于今天的普通人的生活。
没有周电影的跌荡起伏,没有周电影中的盖世神功。
仅仅是在普通人的小幸福、小成就、小灾小难中徘回,
但始终能从他所扮演的小人物身上看见自己的影子。
英国诗人布莱尔有一句:滴水见世界,朵花见天堂。
同样的东西不同的人看了都有不同的感觉,如果有时间,鼓励看一下。
卓别林-《摩登时代》
Logo 改了?
左上的俩洞是什么?
燃烧的香烟太颓废了,不符合自己的风格。
改成了 XaoS 的分型,可以无限放大,无限复杂。
最早接触这东西是在 BluePoint Linux 2.0 里面,有一个程序专门用于绘制这种图形。
http://wmi.math.u-szeged.hu/~kovzol/xaos/

燃烧的香烟太颓废了,不符合自己的风格。
改成了 XaoS 的分型,可以无限放大,无限复杂。
最早接触这东西是在 BluePoint Linux 2.0 里面,有一个程序专门用于绘制这种图形。
http://wmi.math.u-szeged.hu/~kovzol/xaos/
来自 37signals 的帅哥们
37signals 这家小公司(看过这个视频后觉得这公司更小了),在去年的 Web 2.0 风潮中因为推出了 Ruby on Rails Web Framework 而一下子名声大作。
连 Apple 都打算在下一个版本的 Mac OS X Leopard 中带上 Ruby on Rails,作为在 Mac 机上的成功范例,Apple 自然少不了要为他们拍一期 Profile。
让我们也来看一看这个诞生奇迹的小公司,以及 David Heinemeier Hansson。 :-)
视频地址:http://www.apple.com/education/whymac/compsci/video.html

连 Apple 都打算在下一个版本的 Mac OS X Leopard 中带上 Ruby on Rails,作为在 Mac 机上的成功范例,Apple 自然少不了要为他们拍一期 Profile。
让我们也来看一看这个诞生奇迹的小公司,以及 David Heinemeier Hansson。 :-)
视频地址:http://www.apple.com/education/whymac/compsci/video.html
每周二的博客推荐(四)
一周时间过得真快,又是一个周二了 :-)
今早一出门就遇上了新闻事件,三环安贞桥路段早晨竟然有一辆车着火了。

Tony 的新服务器已经架设好了,因为 blog spot 被封锁,所以打算利用 sftp 的方式发布到他的服务器上。
本周思维的乐趣好文不断,让我们来一起读读:
如何脱贫?
首先是《尤努斯:还穷人尊严和权利 》,本期思乐对小额贷款的介绍比较多,除了本文,还有一篇《个人可以改变什么》,和《向社会福利说不》
个人的力量是有限的,但又是无穷的。这里的个人,既是指最初在 1976 年拿出27美元借给村子里42个制作竹凳子的农妇的尤努斯,也指获得了这 27 美元的农妇。尤努斯将自己的 27 美元借给别人,获得利息,成立了格莱珉银行。而农夫利用这 27 美元成功地脱了贫。。。
”格莱珉贷款给乞丐,这种贷款免利息,而且不设还款期限。如果乞丐以乞讨得来的收入还贷,格莱珉不会接受。格莱珉利用一对一或者一对二的方式帮助乞丐,让他们自谋生路。有些乞丐可能只有一个眼睛,或者只有一条胳膊,他们只能待在一个地方,无法从事生产。但是即便是这样的人,格莱珉也鼓励他们在乞讨的同时,在旁边放上一些饮料或水果进行买卖。事实证明,乞丐确实也有商业头脑,他们在接受格莱珉帮助后,经常会尽量找一些黄金地段,以方便买卖小产品。尤努斯说,每个人都能创造价值,即便他四肢残缺或双目失明。“
一些问题的解决方式总是那么出人意料,但仔细想想,事实本该如此。
另外,鼓励大家都去看看《穷人的银行家》。
如何面对生老病死?
《Vigeland sculpture park》,附带上一张照片《从哪里开始变老 》。
最近读到了关于 Edgar Cayce 的一些报道,他是一个灵能者 <- 当然这是否属实,我无法证明了。他通过使自己进入一种休眠状态,能够回答一切问题。其中我所最关注的,是关于轮回转世。
尽管我一直认为人类与动物有所不同,一个问题-为什么和人类同源的黑猩猩头发不像人类一样一直不停地长,或者说头发没有人类长?
但我实际关心的不是是否会有下一世,而是这一世对待生活,对待别人应该以什么态度来面对。要通往灵界,必须要达到极高造诣,这个造诣可以使人与人之间和睦相处,可以使自己事业风调雨顺,等等等等,这种造诣的人,究竟是个什么样的人?作为拥有自由选择能力的人类来说,怎样才能达到这样的造诣。
为的不是下一世的重复再来,而是希望能做到这一世的无愧于心。
如何获得成功?
《“有目的性的实践”》,以及《如何看费奥瑞娜给惠普的贡献? 》 都可以看看。
正面的与反面的,十年的计划和费奥瑞娜正反面的意见。
《最具悲剧气质的企业家》
用回复中的一句话概括:你和那个傻瓜吵,你这么聪明,(我们)不骂你骂谁。
抱着另一个回复的”白云苍狗无常,沉浮自有天命“的态度来看待自己的成功和失败。
很长时间都没有关于 Linux 的消息了,最近 Linux 的负面消息实在太多,什么 Hans Reiser - reiserfs 文件系统的作者的妻子失踪,可能是遭到丈夫的谋杀啊,Firefox 2.0 出 Bug 了啊,Linus Torvarlds 发布 2.6.18 时说话像海盗头啊。
社会在进步,不合时宜的东西自然会淘汰。
今早一出门就遇上了新闻事件,三环安贞桥路段早晨竟然有一辆车着火了。
Tony 的新服务器已经架设好了,因为 blog spot 被封锁,所以打算利用 sftp 的方式发布到他的服务器上。
本周思维的乐趣好文不断,让我们来一起读读:
如何脱贫?
首先是《尤努斯:还穷人尊严和权利 》,本期思乐对小额贷款的介绍比较多,除了本文,还有一篇《个人可以改变什么》,和《向社会福利说不》
个人的力量是有限的,但又是无穷的。这里的个人,既是指最初在 1976 年拿出27美元借给村子里42个制作竹凳子的农妇的尤努斯,也指获得了这 27 美元的农妇。尤努斯将自己的 27 美元借给别人,获得利息,成立了格莱珉银行。而农夫利用这 27 美元成功地脱了贫。。。
”格莱珉贷款给乞丐,这种贷款免利息,而且不设还款期限。如果乞丐以乞讨得来的收入还贷,格莱珉不会接受。格莱珉利用一对一或者一对二的方式帮助乞丐,让他们自谋生路。有些乞丐可能只有一个眼睛,或者只有一条胳膊,他们只能待在一个地方,无法从事生产。但是即便是这样的人,格莱珉也鼓励他们在乞讨的同时,在旁边放上一些饮料或水果进行买卖。事实证明,乞丐确实也有商业头脑,他们在接受格莱珉帮助后,经常会尽量找一些黄金地段,以方便买卖小产品。尤努斯说,每个人都能创造价值,即便他四肢残缺或双目失明。“
一些问题的解决方式总是那么出人意料,但仔细想想,事实本该如此。
另外,鼓励大家都去看看《穷人的银行家》。
如何面对生老病死?
《Vigeland sculpture park》,附带上一张照片《从哪里开始变老 》。
最近读到了关于 Edgar Cayce 的一些报道,他是一个灵能者 <- 当然这是否属实,我无法证明了。他通过使自己进入一种休眠状态,能够回答一切问题。其中我所最关注的,是关于轮回转世。
尽管我一直认为人类与动物有所不同,一个问题-为什么和人类同源的黑猩猩头发不像人类一样一直不停地长,或者说头发没有人类长?
但我实际关心的不是是否会有下一世,而是这一世对待生活,对待别人应该以什么态度来面对。要通往灵界,必须要达到极高造诣,这个造诣可以使人与人之间和睦相处,可以使自己事业风调雨顺,等等等等,这种造诣的人,究竟是个什么样的人?作为拥有自由选择能力的人类来说,怎样才能达到这样的造诣。
为的不是下一世的重复再来,而是希望能做到这一世的无愧于心。
如何获得成功?
《“有目的性的实践”》,以及《如何看费奥瑞娜给惠普的贡献? 》 都可以看看。
正面的与反面的,十年的计划和费奥瑞娜正反面的意见。
《最具悲剧气质的企业家》
用回复中的一句话概括:你和那个傻瓜吵,你这么聪明,(我们)不骂你骂谁。
抱着另一个回复的”白云苍狗无常,沉浮自有天命“的态度来看待自己的成功和失败。
很长时间都没有关于 Linux 的消息了,最近 Linux 的负面消息实在太多,什么 Hans Reiser - reiserfs 文件系统的作者的妻子失踪,可能是遭到丈夫的谋杀啊,Firefox 2.0 出 Bug 了啊,Linus Torvarlds 发布 2.6.18 时说话像海盗头啊。
社会在进步,不合时宜的东西自然会淘汰。
每周二的博客推荐(三)
又到了星期二,我对星期二有特别的感觉,因为小时候家里的有线电视一到星期二就进入维护状态,整天没有电视看,好在今天网络普及,只要 G F W 不发威,想看什么东西还是可以非常随时的。
下面开始正式内容:
洪晃找乐的BLOG
《资产阶级生活方式》,生活是什么样的?每个人有不同的感受。按照文章观点,虽然我的生活水平还处于无产阶级阶段,但是生活还是比较”大资“的。事实上我觉得新一代的人都挺”资“的,但也不排除像公司以前一同事是吉他高手,现在同样为生活而奔波一样,还是个生活态度问题。
思维的乐趣
《哲学女友》,人在 15-18 岁之间是最单纯最能够专注于技术的年龄,再大一点反而对人生之类的思考的更多了,胡正记得也是到了这个年龄开始学起了哲学。"人生两种stream,一个是老庄,讲顺应自然,无为而治,一个是儒家。"我想我属于在事业上偏儒家,很主动地希望能够改变结果,在家庭上偏老庄的吧,希望生活上能平稳而安逸。
FT 中文网-金融时报中文版
《中国父母对子女的教育是愚蠢的》,没博客了,拿文章充数。这篇需要注册才能看到。我倒觉得不仅仅是教育方式是愚蠢的,绝大多数做事方式都是愚蠢的,完全根据愚蠢的先验,而没有任何变通和思考。
一条回复是非常客观的,容我转一下:
其实,问题的根源并不在父母,而在社会。中国是一个封建思想很深厚的社会,人治的意识很浓厚,要治人就不喜欢别人超越自己,奴化教育是很厉害的,孩子的父母大多也受这种教育,所以不喜欢自己的孩子被超越。但是社会总在不断的发展,虽然他的步子还不够快……
暂时写到这里。
下面开始正式内容:
洪晃找乐的BLOG
《资产阶级生活方式》,生活是什么样的?每个人有不同的感受。按照文章观点,虽然我的生活水平还处于无产阶级阶段,但是生活还是比较”大资“的。事实上我觉得新一代的人都挺”资“的,但也不排除像公司以前一同事是吉他高手,现在同样为生活而奔波一样,还是个生活态度问题。
思维的乐趣
《哲学女友》,人在 15-18 岁之间是最单纯最能够专注于技术的年龄,再大一点反而对人生之类的思考的更多了,胡正记得也是到了这个年龄开始学起了哲学。"人生两种stream,一个是老庄,讲顺应自然,无为而治,一个是儒家。"我想我属于在事业上偏儒家,很主动地希望能够改变结果,在家庭上偏老庄的吧,希望生活上能平稳而安逸。
FT 中文网-金融时报中文版
《中国父母对子女的教育是愚蠢的》,没博客了,拿文章充数。这篇需要注册才能看到。我倒觉得不仅仅是教育方式是愚蠢的,绝大多数做事方式都是愚蠢的,完全根据愚蠢的先验,而没有任何变通和思考。
一条回复是非常客观的,容我转一下:
其实,问题的根源并不在父母,而在社会。中国是一个封建思想很深厚的社会,人治的意识很浓厚,要治人就不喜欢别人超越自己,奴化教育是很厉害的,孩子的父母大多也受这种教育,所以不喜欢自己的孩子被超越。但是社会总在不断的发展,虽然他的步子还不够快……
暂时写到这里。
半夜做音乐
自从开始学习音乐以后,听歌时的感觉都不一样了,会仔细去听歌里每一个乐器的音高,想像着它在键盘上的位置。
很佩服最早敲响第一个乐器的人,他把原本很单调的噪音混合才一起,成为了人类的一种享受。
现在使用的软件是 GarageBand 和 Intuem ,都是非常入门的软件,但功能都很完善,GarageBand 使用的是真实的 Soundtrack 来做,而 Intuem 使用了 Midi 波表,前者更加真实,而后者可以直接打开 midi 文件并转化为五线谱。
挺喜欢感性和理性的兼有的,处女座的自己的,理性的分析周围和自己并做出计划来完成目标,我从目标的成功获得了自信-事情总是朝着自己预想的方向前进着;而用感性的心态去对待身边的每个人,去感觉生活中的美,把学习音乐的过程,变成跟着感觉走的过程。
有在哪里看到:感性的人改变别人来适应自己,而理性的人改变自己来适应别人,可是这个世界就是被一群感性的人改变的。我没改变世界,但也成功地改变了周围的人,并扭转了自己的命运。
后者的理性我觉得改成现实的人更好,感性不是任性,而是更多的同情和理解,更多地用心去感受,感性的人有理想,并愿意为理想而努力;理性也不是现实而成的麻木不仁,而是更多地客观的分析、做事、做人。
挺害怕自己变成一个鲁迅笔下的麻木不仁的人的,周围这种人其实已经很多了,每天为了生活而忙碌,不知所谓的忙碌,不知道明天的忙碌,感受不到月亮和星星的点光,感受不到所呼吸的空气的变化,很怕成为那样的人。
依然没有从神经衰弱中走出来,失眠、多梦,心悸和体温的不正常依然在折磨着自己的身体。近期的计划总是因为这些身体的不适而中断,但练习音乐却始终坚持了下来,每每弹奏起音符,身上的不适总是能立刻消失,音乐能医治人的心灵。
遇人不淑带来的后果是要自己承担的,起码我还有选择救恕自己的机会。 :-)
或许我再多顾及自己一点,也能少受不少伤吧。
最近晚上常陪 Limit 长谈,把遗漏的 blog 补上。
大哲学家
我有一位同事,前一段时间他解决了我的两个重大问题。
自由是什么?-我们现在就挺自由的!
超赞啊!这个问题本是我想用来回答什么是自由软件的。我不想出国的原因,就是因为在国内所有的软件都是自由软件啊!所有的音乐、书籍都是自由的啊,当然这个自由是假自由,是长不了的自由,同样是 free,freedom 的意义基本没有,免费的意义倒是非常可见。
现在确实除了经济上的苛捐杂税颇多了一点,开销和收入比忒差了一点,人还是很自由的,有足够的经济基础,想玩什么就玩什么,想去哪里就去哪里,十年前还关注你的户口本,前两年上北京来还要办个暂住证,现在谁管那些,除了小孩上学,户口本也基本没什么用处了。
从生活上而言,还要怎样自由?
活着为什么?-活到老!
再赞啊!谁能把这个问题回答得如此精妙?!
一帮幻想狂包括我在内都想这辈子干场大的,才觉得不妄此生,孰不知世界上最大的困难,就是让自己从出生一直活到自然死亡啊!
好死不如赖活着,活着可不就是为了让自己活得有滋有味的。
自由是什么?-我们现在就挺自由的!
超赞啊!这个问题本是我想用来回答什么是自由软件的。我不想出国的原因,就是因为在国内所有的软件都是自由软件啊!所有的音乐、书籍都是自由的啊,当然这个自由是假自由,是长不了的自由,同样是 free,freedom 的意义基本没有,免费的意义倒是非常可见。
现在确实除了经济上的苛捐杂税颇多了一点,开销和收入比忒差了一点,人还是很自由的,有足够的经济基础,想玩什么就玩什么,想去哪里就去哪里,十年前还关注你的户口本,前两年上北京来还要办个暂住证,现在谁管那些,除了小孩上学,户口本也基本没什么用处了。
从生活上而言,还要怎样自由?
活着为什么?-活到老!
再赞啊!谁能把这个问题回答得如此精妙?!
一帮幻想狂包括我在内都想这辈子干场大的,才觉得不妄此生,孰不知世界上最大的困难,就是让自己从出生一直活到自然死亡啊!
好死不如赖活着,活着可不就是为了让自己活得有滋有味的。
补上两天的 blog
limit 来北京找工作了,昨天开始暂住在我家。
我之前便帮他向公司投递了简历,今天参加了面试,结果未知,我下午去北邮 show 了把 XGL,明天再去刘那里探听一下风声。
limit 目前感觉是有点陷入困境的感觉,状态不是很好,今天他来投奔我,想起了当年我从家一个人跑到南京去投奔 Axin,应聘 Linux 讲师,然后又坐长途汽车到了常州,受到了吴文官的照顾。
与今天的 limit 不同的是,当时的我涩涩的,不知道未来会怎么样,有那么点迷茫,但依然信心满满,相信自己能掌握自己的命运。
人有朋友会是非常好的感觉,limit 是长期以来一直在支持我的人中的一个,今天我也在给他打气,希望他能够相信自己。
就写那么多吧,如果有能写的,会继续写下去。
我之前便帮他向公司投递了简历,今天参加了面试,结果未知,我下午去北邮 show 了把 XGL,明天再去刘那里探听一下风声。
limit 目前感觉是有点陷入困境的感觉,状态不是很好,今天他来投奔我,想起了当年我从家一个人跑到南京去投奔 Axin,应聘 Linux 讲师,然后又坐长途汽车到了常州,受到了吴文官的照顾。
与今天的 limit 不同的是,当时的我涩涩的,不知道未来会怎么样,有那么点迷茫,但依然信心满满,相信自己能掌握自己的命运。
人有朋友会是非常好的感觉,limit 是长期以来一直在支持我的人中的一个,今天我也在给他打气,希望他能够相信自己。
就写那么多吧,如果有能写的,会继续写下去。
试奏圆舞曲一首
新 MIDI 键盘绝对好用,努力靠它学习弹奏中。
下面是练习用圆舞曲一首,因无法 blogger 无法上传 mp3,遂只好用 GarageBand 生成五线谱上传。
弹得不好,懂谱子的自己看吧。 -_-#

下面是练习用圆舞曲一首,因无法 blogger 无法上传 mp3,遂只好用 GarageBand 生成五线谱上传。
弹得不好,懂谱子的自己看吧。 -_-#

发烧无止尽


一边烧摄影一边烧音乐。
用耳朵去倾听每一个音符的跳动真的不是一般好的感觉,吉他弦因为因和五线谱上的七个音不同,再加上弦时间一长容易松导致跑音,我始终把握不住,但钢琴在这点上优势就很大了。
利用 Garageband 配合电脑键盘,基本把握了七个音符,但是感觉到了不够用,所以购入了这个键盘。
非常满意,后触的感觉很好,因为键位一下子延长了,我可以同时高低音配合了,而不用鼠标在虚拟键盘上游走。
持续锻炼中,还要看看说明书,把这个键盘的功能全部榨干。
“你有一双发现美的眼睛”
模模说:你有一双发现美的眼睛。
我想说:我还有一颗孤独的心和一个不甘寂寞的脑袋,而我妈奇迹般的把它们放进了一个身体里,铸就了今天的我。
利用 tc 控制出口流量。
tc 是 iproute2 中带的命令,用于控制 Linux 的网络传输流量限制。
这感觉是比 iptables 还麻烦的东西,因为公司拿了台机器在内网做下载,为了不影响普通员工上网,所以才有了这么一想法控制一把在网络中的下载。
整个公司都没人懂这玩意儿,只好自己摸索着了。 -_-#
tc 里利用 Linux 中的 QoS(Quality of service)对包进行调度,所以需要确保在内核中将 QoS 下的 Class Based Queueing (CBQ)、Token Bucket Flow、Traffic Shapers 设置为 y 或者 M。
tc 最少得有 3 条句才能达到控制流量的目的:创建队列 -> 创建子分类 -> 创建过滤器,而且还要和ip命令结果起来控制流入的接口才可以达到限制的。
理解不深,试验没有做完,以后再补充 -_-#
这感觉是比 iptables 还麻烦的东西,因为公司拿了台机器在内网做下载,为了不影响普通员工上网,所以才有了这么一想法控制一把在网络中的下载。
整个公司都没人懂这玩意儿,只好自己摸索着了。 -_-#
tc 里利用 Linux 中的 QoS(Quality of service)对包进行调度,所以需要确保在内核中将 QoS 下的 Class Based Queueing (CBQ)、Token Bucket Flow、Traffic Shapers 设置为 y 或者 M。
tc 最少得有 3 条句才能达到控制流量的目的:创建队列 -> 创建子分类 -> 创建过滤器,而且还要和ip命令结果起来控制流入的接口才可以达到限制的。
理解不深,试验没有做完,以后再补充 -_-#
Kernel 2.6.17 和 2.6.18 在 SATA 硬盘上的性能对比
在最新的 Linux kernel 2.6.18 changlog 中,我们可以看到大量关于 SATA 的修正和增强,那么新内核在 SATA 硬盘的传输率方面是否真的有所提高呢?这个只有测试一下才能知道。
测试平台是 DELL M1210 的小笔记本,内存 1G,硬盘是 Toshiba 2.5", 40GB, SATA, 16MB, 5400转, 9.5mm,型号为 MK4032GS 的笔记本硬盘。 -_-#
结果是:
Everest 0.2 update 1 的 2.6.17.13-36smp 的内核:
# hdparm -Tt /dev/sda
/dev/sda:
Timing cached reads: 4712 MB in 2.00 seconds = 2359.41 MB/sec
Timing buffered disk reads: 96 MB in 3.05 seconds = 31.43 MB/sec
Everest 0.2 自己编译的 2.6.18smp 内核
# hdparm -Tt /dev/sda
/dev/sda:
Timing cached reads: 4788 MB in 2.00 seconds = 2395.98 MB/sec
Timing buffered disk reads: 96 MB in 3.03 seconds = 31.68 MB/sec
这是在接上 AC 电源,重复运行三次 hdparm,让硬盘能够全速转起来得到的结果,可以看到 2.6.18 内核确实对 SATA 性能有一定提高,但是效果不明显,硬盘物理速度依然是瓶颈。
找空拿个台式机来做测试,可能拿 iozone 跑一把。
另一件有趣的事情,双核的机器在运行多线程任务,满负载的时候,两个核的占用率相加接近 100%,如果用 yes 大法跑单线程的满负载,可以看见 CPU1 为 100%,同时运行两个 yes 尚未测试。
找空做进一步测试。
Cpu0 : 76.1% us, 2.7% sy, 0.0% ni, 16.6% id, 0.0% wa, 4.7% hi, 0.0% si
Cpu1 : 13.0% us, 1.7% sy, 0.0% ni, 79.7% id, 5.0% wa, 0.0% hi, 0.7% si
Cpu0 : 47.8% us, 2.0% sy, 0.0% ni, 49.2% id, 1.0% wa, 0.0% hi, 0.0% si
Cpu1 : 48.0% us, 2.0% sy, 0.0% ni, 46.3% id, 3.7% wa, 0.0% hi, 0.0% si
补充测试,同时运行两个 yes,基本到了 200% 了 :-)
Cpu0 : 82.0% us, 18.0% sy, 0.0% ni, 0.0% id, 0.0% wa, 0.0% hi, 0.0% si
Cpu1 : 88.2% us, 9.8% sy, 0.0% ni, 2.0% id, 0.0% wa, 0.0% hi, 0.0% si
测试平台是 DELL M1210 的小笔记本,内存 1G,硬盘是 Toshiba 2.5", 40GB, SATA, 16MB, 5400转, 9.5mm,型号为 MK4032GS 的笔记本硬盘。 -_-#
结果是:
Everest 0.2 update 1 的 2.6.17.13-36smp 的内核:
# hdparm -Tt /dev/sda
/dev/sda:
Timing cached reads: 4712 MB in 2.00 seconds = 2359.41 MB/sec
Timing buffered disk reads: 96 MB in 3.05 seconds = 31.43 MB/sec
Everest 0.2 自己编译的 2.6.18smp 内核
# hdparm -Tt /dev/sda
/dev/sda:
Timing cached reads: 4788 MB in 2.00 seconds = 2395.98 MB/sec
Timing buffered disk reads: 96 MB in 3.03 seconds = 31.68 MB/sec
这是在接上 AC 电源,重复运行三次 hdparm,让硬盘能够全速转起来得到的结果,可以看到 2.6.18 内核确实对 SATA 性能有一定提高,但是效果不明显,硬盘物理速度依然是瓶颈。
找空拿个台式机来做测试,可能拿 iozone 跑一把。
另一件有趣的事情,双核的机器在运行多线程任务,满负载的时候,两个核的占用率相加接近 100%,如果用 yes 大法跑单线程的满负载,可以看见 CPU1 为 100%,同时运行两个 yes 尚未测试。
找空做进一步测试。
Cpu0 : 76.1% us, 2.7% sy, 0.0% ni, 16.6% id, 0.0% wa, 4.7% hi, 0.0% si
Cpu1 : 13.0% us, 1.7% sy, 0.0% ni, 79.7% id, 5.0% wa, 0.0% hi, 0.7% si
Cpu0 : 47.8% us, 2.0% sy, 0.0% ni, 49.2% id, 1.0% wa, 0.0% hi, 0.0% si
Cpu1 : 48.0% us, 2.0% sy, 0.0% ni, 46.3% id, 3.7% wa, 0.0% hi, 0.0% si
补充测试,同时运行两个 yes,基本到了 200% 了 :-)
Cpu0 : 82.0% us, 18.0% sy, 0.0% ni, 0.0% id, 0.0% wa, 0.0% hi, 0.0% si
Cpu1 : 88.2% us, 9.8% sy, 0.0% ni, 2.0% id, 0.0% wa, 0.0% hi, 0.0% si
近期 blog 推介
每天阅读 blog、新闻、文章无数,自然提神醒脑、赏心悦目。心想看了不能白看啊,以后每周二汇总一下所看到的,好的 blog,大家一起分享。
一!
jserv's blog - 台湾 Linux 高人黄敬群的博客,高人似乎近期也有不少犯错误的时候,近期的,已经转载过的 《寫程式的呆瓜》 和 《GPL 授權的晦暗一面》,都非常值得一看。
《寫程式的呆瓜》 - 以 X Window 中,程序员在编写代码过程中常犯的缺少"()"为例,将可能发生错误的原因归结成了“无知”、“压力”、“厌烦”和“人类脆弱的根性”上,只要是人都会因为这些原因发生错误,所以我们有了 Bugzilla! ;-)
《GPL 授權的晦暗一面》- 以他的 qonsole 项目不小心触犯了 GPL 中的条款-忘记放入 Copying license 进去,导致他在 linux.com 上扬了把名。我也曾经在 flickr 上放过 leopard 的截图,虽然没有泄露任何程序,但依然受到了很多人的谴责。都引以为戒一把吧。
二!
思维的乐趣 -本周
一!
jserv's blog - 台湾 Linux 高人黄敬群的博客,高人似乎近期也有不少犯错误的时候,近期的,已经转载过的 《寫程式的呆瓜》 和 《GPL 授權的晦暗一面》,都非常值得一看。
《寫程式的呆瓜》 - 以 X Window 中,程序员在编写代码过程中常犯的缺少"()"为例,将可能发生错误的原因归结成了“无知”、“压力”、“厌烦”和“人类脆弱的根性”上,只要是人都会因为这些原因发生错误,所以我们有了 Bugzilla! ;-)
《GPL 授權的晦暗一面》- 以他的 qonsole 项目不小心触犯了 GPL 中的条款-忘记放入 Copying license 进去,导致他在 linux.com 上扬了把名。我也曾经在 flickr 上放过 leopard 的截图,虽然没有泄露任何程序,但依然受到了很多人的谴责。都引以为戒一把吧。
二!
思维的乐趣 -本周
不同平台的 nbench 性能测试
nbench 是个很有意思的基准性能测试工具。
能够对单颗 CPU Core 的性能进行内存、整型运算和浮点运算性能。
基准分是 AMD K6/233*, 512 KB L2-cache, gcc 2.7.2.3, libc-5.4.38
以后我如果有新机器会随意测试一下性能,并记录在这里。
当然,nbench 仅仅支持单核也是它的缺点,但该程序更多的是测试 Linux 系统本身在进行一些计算时的效率。
其主页和下载在:http://www.tux.org/~mayer/linux/bmark.html
邹鹏程也有一份相同的测试报告在:http://pczou.blogchina.com/1529012.html
能够对单颗 CPU Core 的性能进行内存、整型运算和浮点运算性能。
基准分是 AMD K6/233*, 512 KB L2-cache, gcc 2.7.2.3, libc-5.4.38
以后我如果有新机器会随意测试一下性能,并记录在这里。
当然,nbench 仅仅支持单核也是它的缺点,但该程序更多的是测试 Linux 系统本身在进行一些计算时的效率。
其主页和下载在:http://www.tux.org/~mayer/linux/bmark.html
邹鹏程也有一份相同的测试报告在:http://pczou.blogchina.com/1529012.html
| 测试平台 | 发行版 | 整数 | 浮点 | 内存 |
| Macbook 063(注5) | Mac OS X 10.5.1 (leopard) | 13.635 | 24.792 | 21.704 |
| PowerBook 17"(注1) | Gentoo 2006.0(gcc4.1.1) | 14.516 | 10.259 | 9.502 |
| PowerBook 17"(注1) | Mac OS X 10.4.9 | 11.931 | 12.749 | 13.649 |
| Intel 2.4G 开发平台(注释2) | Everest 0.1 | 16.060 | 30.186 | 18.684 |
| Intel 2.4G 开发平台(注释2) | Gentoo | 18.387 | 16.692 | 21.326 |
| Intel Core Duo*2(4Cores total) 3.2G | RFDC 5.0 | 13.480 | 13.488 | 15.706 |
| DELL Latitiude D820@1GHz(注释3) | RFDT 5.0(2.6.17.1-7smp) | 8.507 | 16.480 | 10.019 |
| DELL Latitiude D820@1.6GHz(注释3) | RFDT 5.0(2.6.17.1-7smp) | 8.469 | 16.362 | 9.986 |
| DELL Precision 690 Xeon 3.2G | RFDT 5.0(2.6.17.1-7) | 9.098 | 17.261 | 15.180 |
| Red Flag Alpha 下载服务器(注释4) | Red Flag Linux 2.0 for Alpha | 2.322 | 2.847 | 3.247 |
| 龙梦盒子 | Debian etch | 3.351 | 2.727 | 2.469 |
| 龙梦盒子 | Everest 0.5(64bits) | 3.183 | 4.754 | 2.728 |
| Macbook Pro(T8300) | Mac OS X 10.6.0 Beta1 | 20.190 | 37.898 | 22.963 |
| HP XW4600(E7200) | Fedora 11 | 17.013 | 36.669 | 16.797 |
| RHEL in Xen(AMD 8356) | RHEL 5.3 Running in Xen | 11.694 | 14.412 | 9.201 |
注:绿底为同测试最高分,红底为同测试最低分。
剩下要做的事情
日志的日期总算排好了,以后 blogger flickr 就成了绝配。
多经历一点事情是好的,起码养成了写日志的习惯。
回顾网站的变迁,从最早在 .mac,然后到了 xcx.pl 又到了 dreamhost 到现在的 blogger。
希望 blogspot 不要被封,省得又要搬家。
名字也反映了我心理的变化。
“框框的小黑屋”是觉得自己是孤独的,历经之后觉得,嗯,还行 ;-)
“一面”写在上面是“一面之缘,灵机一动”,其实真实的意思我没说,前者本来就不通,缘分是不能用灵机一动来形容的,其实是我特别害怕双重性格的人,他们自身的思想可以和自己冲突,他们所说的话可以和行为完全相反,他们的逻辑让人莫名其妙,那时我感觉到自己的身边已经出现了这样的人。
“427 Error - Site not perfect” 是模仿了 HTTP 协议上的一个错误写法(最常见的是 200 OK 和 404 Not found),我拿了 427 这个没有用过的错误号,写上 Site not perfect,因为我知道自己是不完美的,尽管我一直都在理清自己的逻辑,但是思想的缺点就在于它本身是自相矛盾的。
一个人真正的思想是不能写在博客上的,博客是用来写给别人看的,是用来共享的,无论是技术,还是因为某些事情爆发的情绪,它们都是自己不想记住的,技术在不断变化,记住没有用,情绪也在不停的变动,不能因为情绪的变动而影响自己做人、做事的原则。
所以每次写完博客,我都会马上忘记。
真正的思想是需要溶于心中并化之为行动的,最终成为性格,所以还是让博客更加偏向于技术性的记录好了。
上面所说的,是我所吐露的少数真的思想中的一个。
剩下的事情:
1. 把遗漏的几个 blog 补上。(完成)
2. 处理好图片。
3. 重新修改旧 blog 以适应新 css 的版面。
4. 利用 feed burner/feedsky 一类的 feed 烧录商重新烧制 rss,以免因为搬家造成旧 rss 的失效。(完成)
5. 长期以来我比较低调,只有几个最好的朋友才知道我的 blog,以后需要小小的宣传一下。 :-)
6. 看看可否把旧的评论迁移过来,朋友的评论对我非常重要。(完成)
7. 想一个更加文驺驺而更加能够表达自身思想的博客名,“Site not perfect” 已经完成了它的使命。- 10月10日补充:QQ 把俺这名字链到了它的 blog 上,那就算了不改了,这名字也基本能反映我修身、修心的愿望,还是不错的。
8. 把字体调大一号,以适应 Windows 的显示,目前因为 css 和图片在其它服务器上,需要花一点时间重新上传并整理。
在此感谢长期支持我的好友们。
多经历一点事情是好的,起码养成了写日志的习惯。
回顾网站的变迁,从最早在 .mac,然后到了 xcx.pl 又到了 dreamhost 到现在的 blogger。
希望 blogspot 不要被封,省得又要搬家。
名字也反映了我心理的变化。
“框框的小黑屋”是觉得自己是孤独的,历经之后觉得,嗯,还行 ;-)
“一面”写在上面是“一面之缘,灵机一动”,其实真实的意思我没说,前者本来就不通,缘分是不能用灵机一动来形容的,其实是我特别害怕双重性格的人,他们自身的思想可以和自己冲突,他们所说的话可以和行为完全相反,他们的逻辑让人莫名其妙,那时我感觉到自己的身边已经出现了这样的人。
“427 Error - Site not perfect” 是模仿了 HTTP 协议上的一个错误写法(最常见的是 200 OK 和 404 Not found),我拿了 427 这个没有用过的错误号,写上 Site not perfect,因为我知道自己是不完美的,尽管我一直都在理清自己的逻辑,但是思想的缺点就在于它本身是自相矛盾的。
一个人真正的思想是不能写在博客上的,博客是用来写给别人看的,是用来共享的,无论是技术,还是因为某些事情爆发的情绪,它们都是自己不想记住的,技术在不断变化,记住没有用,情绪也在不停的变动,不能因为情绪的变动而影响自己做人、做事的原则。
所以每次写完博客,我都会马上忘记。
真正的思想是需要溶于心中并化之为行动的,最终成为性格,所以还是让博客更加偏向于技术性的记录好了。
上面所说的,是我所吐露的少数真的思想中的一个。
剩下的事情:
1. 把遗漏的几个 blog 补上。(完成)
2. 处理好图片。
3. 重新修改旧 blog 以适应新 css 的版面。
4. 利用 feed burner/feedsky 一类的 feed 烧录商重新烧制 rss,以免因为搬家造成旧 rss 的失效。(完成)
5. 长期以来我比较低调,只有几个最好的朋友才知道我的 blog,以后需要小小的宣传一下。 :-)
6. 看看可否把旧的评论迁移过来,朋友的评论对我非常重要。(完成)
7. 想一个更加文驺驺而更加能够表达自身思想的博客名,“Site not perfect” 已经完成了它的使命。- 10月10日补充:QQ 把俺这名字链到了它的 blog 上,那就算了不改了,这名字也基本能反映我修身、修心的愿望,还是不错的。
8. 把字体调大一号,以适应 Windows 的显示,目前因为 css 和图片在其它服务器上,需要花一点时间重新上传并整理。
在此感谢长期支持我的好友们。
寫程式的呆瓜
大量的 blog 要修改发布日期,郁闷 -_-#
以后收心,都写点技术方面的。
转一篇 jserv 的 blog,也算引以为戒。
單字 "goofs" 的意思就是「呆瓜」、「傻子」,多數的人應該都希望這個用詞不要套用在自身,而在我閱讀 Embedded.com 上一篇由 Ben Chelf 發表的文章 [Avoiding the most common software development goofs] 後,卻不由自主地反省起來。
之前的 blog [software validation 小記] 提過現在隨便一個知名的軟體專案,程式碼都已經跨越百萬行的門檻,面對這些大怪物,要如何證明並在有限條件內檢驗,就是當今最重要的課題之一,並且引用具有二十多年歷史的 X Window System 是如何遇到安全性的缺陷,[Coverity Inc.] 對此提出的因應方式,而剛剛那篇文章的作者就是 [Coverity Inc.] 的技術長,長期著墨於軟體品質的驗證與分析。說了這麼多,到底什麼行為稱得上是 "goofs",而這樣的愚昧又釀造什麼悲劇呢?[Avoiding the most common software development goofs] 給了一個明確的例子,試看以下程式碼片段:
出處為 Xorg xserver 的 hw/xfree86/common/xf86Init.c 原始程式,最近的版本已經做了安全性修正,所以跟以上列表不同。看起來沒什麼錯誤,順便複習一下 POSIX API,以下是 man page 內容:
X server 會佔據相關的系統資源並確保 UID = 0 以作最大程度的操作,以上兩個 API 即是判斷執行時期的權限。不過,這不是重點,[Coverity Inc.] 指出這是導致安全性缺陷的發生點,為什麼?注意到 geteuid 後面缺了 "()",這導致我們是以 0 去跟 geteuid 的 function pointer 去比較,而非其傳回值,恰好這個缺陷在某些情況下,會引發非預期的表現,在之前的 blog [software validation 小記] 已經引用說明,這裡不再贅述。所以,解決方式就是在 geteuid 多加個 "()",這樣的錯誤果然「呆瓜」,不是嗎?對比 X11 的眾多 Release 程式碼,可以發現這個缺陷存在多年。
Ben Chelf 整理了幾個開發者犯錯的因素:
字彙簡單,也容易理解,不過錯誤就這樣釀成。今天是 UNIX Desktop,或許只是導致伺服器出現安全性漏洞,修補一下即可,但如果明天是波音飛航系統、居家保全設施、醫療系統、... 又會如何?或許,[技術本身與道德無關;它沒有是非對錯],但無可否認的是,這些缺失往往造成道德問題,卻多肇因於這些 "goofs" 的行徑,Ben Chelf 的文章相當精彩,也讓我對自己不能精準的掌握類似問題的焦點並提出具體的解決方式,感到不安與歉意。
唉,雖然參與過好幾個軟體專案,不過至今還只是個會寫程式的呆瓜罷了。
以后收心,都写点技术方面的。
转一篇 jserv 的 blog,也算引以为戒。
寫程式的呆瓜
單字 "goofs" 的意思就是「呆瓜」、「傻子」,多數的人應該都希望這個用詞不要套用在自身,而在我閱讀 Embedded.com 上一篇由 Ben Chelf 發表的文章 [Avoiding the most common software development goofs] 後,卻不由自主地反省起來。
之前的 blog [software validation 小記] 提過現在隨便一個知名的軟體專案,程式碼都已經跨越百萬行的門檻,面對這些大怪物,要如何證明並在有限條件內檢驗,就是當今最重要的課題之一,並且引用具有二十多年歷史的 X Window System 是如何遇到安全性的缺陷,[Coverity Inc.] 對此提出的因應方式,而剛剛那篇文章的作者就是 [Coverity Inc.] 的技術長,長期著墨於軟體品質的驗證與分析。說了這麼多,到底什麼行為稱得上是 "goofs",而這樣的愚昧又釀造什麼悲劇呢?[Avoiding the most common software development goofs] 給了一個明確的例子,試看以下程式碼片段:
if (getuid() == 0 || geteuid != 0)
{
...
出處為 Xorg xserver 的 hw/xfree86/common/xf86Init.c 原始程式,最近的版本已經做了安全性修正,所以跟以上列表不同。看起來沒什麼錯誤,順便複習一下 POSIX API,以下是 man page 內容:
DESCRIPTION
getuid() returns the real user ID of the current process.
geteuid() returns the effective user ID of the current process.
X server 會佔據相關的系統資源並確保 UID = 0 以作最大程度的操作,以上兩個 API 即是判斷執行時期的權限。不過,這不是重點,[Coverity Inc.] 指出這是導致安全性缺陷的發生點,為什麼?注意到 geteuid 後面缺了 "()",這導致我們是以 0 去跟 geteuid 的 function pointer 去比較,而非其傳回值,恰好這個缺陷在某些情況下,會引發非預期的表現,在之前的 blog [software validation 小記] 已經引用說明,這裡不再贅述。所以,解決方式就是在 geteuid 多加個 "()",這樣的錯誤果然「呆瓜」,不是嗎?對比 X11 的眾多 Release 程式碼,可以發現這個缺陷存在多年。
Ben Chelf 整理了幾個開發者犯錯的因素:
- Ignorance.
- Stress.
- Boredom.
- Human Frailties.
字彙簡單,也容易理解,不過錯誤就這樣釀成。今天是 UNIX Desktop,或許只是導致伺服器出現安全性漏洞,修補一下即可,但如果明天是波音飛航系統、居家保全設施、醫療系統、... 又會如何?或許,[技術本身與道德無關;它沒有是非對錯],但無可否認的是,這些缺失往往造成道德問題,卻多肇因於這些 "goofs" 的行徑,Ben Chelf 的文章相當精彩,也讓我對自己不能精準的掌握類似問題的焦點並提出具體的解決方式,感到不安與歉意。
唉,雖然參與過好幾個軟體專案,不過至今還只是個會寫程式的呆瓜罷了。
靠,ISP 居然倒了。
前一个 ISP 居然在 30 号那天倒掉了,好不容易花了两天把旧 blog 倒到免费的 blogger 上来,还好现在 blogspot 解禁了,不过指不定哪天又要被封。
这次还好,刚好在上个月 26 日备份了一次,要不然肯定要哭死。
以后 blog 要留两份,blogger 这里一份,my donews 一份。
顺道清理了一下,只是日期丢了,所有的 blog 都要重新排一遍日期。
可怜的 Tony,请我吃了顿麦当劳换来的共享主机,没用到两天就给咔嚓了。
还在和以前的 ISP 交涉中,把我数据丢了的罪过,可不小。
这次还好,刚好在上个月 26 日备份了一次,要不然肯定要哭死。
以后 blog 要留两份,blogger 这里一份,my donews 一份。
顺道清理了一下,只是日期丢了,所有的 blog 都要重新排一遍日期。
可怜的 Tony,请我吃了顿麦当劳换来的共享主机,没用到两天就给咔嚓了。
还在和以前的 ISP 交涉中,把我数据丢了的罪过,可不小。
☆陶喆-二十二☆
我 17 岁买的第一张 CD 就是冲这首歌去的,当初听着这首歌的时候,就总在想,自己 22 的时候是什么样子?
转眼从那时到现在已经过了快四年,距离 22 也只剩下两年,幸福依然遥远,但我永不放弃。
☆陶喆黑色柳丁☆
春天是他最爱的季节
当微风随意 吹乱他的头发
他并不在意身边世界的吵杂
只想著自己生命中的变化
还有十五分钟才午休
从早到晚没有想像中那么好过
安定的日子不一定就是幸福
忘不掉他在心里做过的梦
他今年农历三月六号刚满二十二
刚甩开课本要离开家看看这世界
却发现许多烦恼要面对
oh yeah
他常会向往能回到那年他一十二
只需要好好上学生活单纯没忧愁
他就像一朵蓓蕾满怀希望
秋天是忽然间就来临
青春虽然有本钱可以洒脱
一场恋爱二十二个月后结束
才知道有些感情不值得赌
九月天气还是有点热
他想公车再不来就走一走路
他开始明白等待未必有结果
一个人也能走上梦的旅途
他今年农历三月六号刚满二十二
想甩掉课本要离开家看看这世界
却发现许多烦恼要面对
oh yeah
他常会想望能回到那年他一十二
只需要好好上学生活单纯没忧愁
他一直满怀希望
人生偶尔会走上一条陌路
像是没有指标的地图
别让他们说你该知足
只有你知道什么是你的幸福
他常会想望能回到那年他一十二
只需要好好上学生活单纯没忧愁
他笑著想过未来
oh 他应该得到幸福
如此的简单的梦
有没有实现

转眼从那时到现在已经过了快四年,距离 22 也只剩下两年,幸福依然遥远,但我永不放弃。
☆陶喆黑色柳丁☆
春天是他最爱的季节
当微风随意 吹乱他的头发
他并不在意身边世界的吵杂
只想著自己生命中的变化
还有十五分钟才午休
从早到晚没有想像中那么好过
安定的日子不一定就是幸福
忘不掉他在心里做过的梦
他今年农历三月六号刚满二十二
刚甩开课本要离开家看看这世界
却发现许多烦恼要面对
oh yeah
他常会向往能回到那年他一十二
只需要好好上学生活单纯没忧愁
他就像一朵蓓蕾满怀希望
秋天是忽然间就来临
青春虽然有本钱可以洒脱
一场恋爱二十二个月后结束
才知道有些感情不值得赌
九月天气还是有点热
他想公车再不来就走一走路
他开始明白等待未必有结果
一个人也能走上梦的旅途
他今年农历三月六号刚满二十二
想甩掉课本要离开家看看这世界
却发现许多烦恼要面对
oh yeah
他常会想望能回到那年他一十二
只需要好好上学生活单纯没忧愁
他一直满怀希望
人生偶尔会走上一条陌路
像是没有指标的地图
别让他们说你该知足
只有你知道什么是你的幸福
他常会想望能回到那年他一十二
只需要好好上学生活单纯没忧愁
他笑著想过未来
oh 他应该得到幸福
如此的简单的梦
有没有实现
Technorati Tags: music
读书计划
无计划的一天怎么过?-逛书店!
昨天就约好了了菜花和狗狗,一起去逛第三极-启示实际是跑到了中关村图书大厦,约好了上次吃好伦歌的门口见面。
于是乎在书店里呆了两个小时

拿了以下几本:

《Ajax 高级程序设计》
想在 Web 2.0 编程方面有点发展-为什么?保鲜 ;-)
本想拿下《Ajax 修炼之道》的基础篇的,可是发现那本 BT 的书竟然以类似 Google Map 那样的 BT 东西做范例,占用了大量页数,结尾捎带了一点 Ruby on rails 的东西 -_-#
又看了其它几本的,有国人写的,有老外写的,整体感觉不是很好。
这本书明显就好了很多,三位作者分别是:Nicholas C. Zakas、Jeremy McPeak、joe Fawcett,由徐锋、吴兰陟翻译,人民邮电出版社出版。
一开始讲了 Ajax/Web 2.0 的基础以及演进过程-HTTP 协议、隐藏帧技术、XMLHttpRequest(这里没有翻译好,竟然被单独翻译成了“XMLHttp 请求”了 -_-#);XML、各种浏览器中的 XPath 和 XSLT;用 40 页描述了 RSS/Atom Feed;各种 Web Service 与 Ajax 的交互;然后拿 GMail 中部分功能做了范例,并自己一步一步实现了这些功能;并讲解了部分 Ajax 框架,包括 JPSpan、DWR、Ajax.NET。
还没看,但浏览一遍的感觉还是不错的。
《无师自通 学日语》
这也是翻阅了很多书以后淘下来的,买这本主要是希望能借它把五十音图给记下来。
洪介贞著,外文出版社出版的这本书,在发音、拼写、以及这些极为基础方面下功夫很大,其它的书对于五十音图把图给列出来就了事,这本书把片假名和平假名单独拿出来,并且说明了片假名是从汉字的偏旁部首而来,而平假名是从汉字的草体而来。
比如:
ア:念作 a,其实对应的中文字源是“阿”,是阿的横折那个部首。
抱歉我对我的电脑的日文输入法还是不太会用,不多做范例了。 :-p
《席殊 实用硬笔字 60 小时训练》
你要是看过席殊同志写的字就知道要多难看就有多难看了,但我为什么还要买这本江西美术出版社出版的这本书呢?
因为它的拆字。
这本书不是字帖用于临摹,而是一本解析汉字的书,把汉字拆成各种笔画和笔顺,然后一步一步让人养成一种正确的习惯。
很明显,临摹不适合我,我还是更愿意按照自己的风格来写字。
《儿童练耳入门》和《吉他自学三月通》
这两本书相辅相成,《卡尔卡西》的最大缺点-是它用五线谱,而它在乐理章节又非常薄弱。
人民音乐出版社出版的《儿童练耳入门》就是我补充乐理知识的办法,抱歉,虽然是写给儿童的啊,但这本书的作者可是非常牛的作曲家-李重光先生。
这本书的好处是从学习方法上入手,养成对声音的一种条件反射。这本书的缺点是用钢琴做演示的。
刘传和朱迎的《吉他自学三月通》,也是一本在基础上非常花功夫的书,从姿势,到把位,到基本的乐理。
同时这本书使用了吉他专用的六线谱,对于快速上手也有好处。
那么书都买了,该订一个读书计划,要不然就成了最后不了了之的搁置品了。
《无师自通 学日语》是暂时搁置的,因为实在没空看。
《Ajax 高级程序设计》因为不是工作需要,所以可以在工作闲暇时看看。
早晨 6 点钟起床,6 点半梳洗完,可以有一个小时时间:
6:30 - 7:30: 《席殊 实用硬笔字 60 小时训练》+练字
晚上 7:30 到家,吃饭半个小时,8:00-10:00 有两个小时看书。
8:00 - 10:00: 《吉他自学三月通》 练吉他先找到音的感觉,然后再看 《儿童练耳入门》 把五线谱补回来,再去看 《卡尔卡西》。
生活是多姿多彩的,但是依然要让它变得充足而丰富。
昨天就约好了了菜花和狗狗,一起去逛第三极-启示实际是跑到了中关村图书大厦,约好了上次吃好伦歌的门口见面。
于是乎在书店里呆了两个小时
拿了以下几本:
《Ajax 高级程序设计》
想在 Web 2.0 编程方面有点发展-为什么?保鲜 ;-)
本想拿下《Ajax 修炼之道》的基础篇的,可是发现那本 BT 的书竟然以类似 Google Map 那样的 BT 东西做范例,占用了大量页数,结尾捎带了一点 Ruby on rails 的东西 -_-#
又看了其它几本的,有国人写的,有老外写的,整体感觉不是很好。
这本书明显就好了很多,三位作者分别是:Nicholas C. Zakas、Jeremy McPeak、joe Fawcett,由徐锋、吴兰陟翻译,人民邮电出版社出版。
一开始讲了 Ajax/Web 2.0 的基础以及演进过程-HTTP 协议、隐藏帧技术、XMLHttpRequest(这里没有翻译好,竟然被单独翻译成了“XMLHttp 请求”了 -_-#);XML、各种浏览器中的 XPath 和 XSLT;用 40 页描述了 RSS/Atom Feed;各种 Web Service 与 Ajax 的交互;然后拿 GMail 中部分功能做了范例,并自己一步一步实现了这些功能;并讲解了部分 Ajax 框架,包括 JPSpan、DWR、Ajax.NET。
还没看,但浏览一遍的感觉还是不错的。
《无师自通 学日语》
这也是翻阅了很多书以后淘下来的,买这本主要是希望能借它把五十音图给记下来。
洪介贞著,外文出版社出版的这本书,在发音、拼写、以及这些极为基础方面下功夫很大,其它的书对于五十音图把图给列出来就了事,这本书把片假名和平假名单独拿出来,并且说明了片假名是从汉字的偏旁部首而来,而平假名是从汉字的草体而来。
比如:
ア:念作 a,其实对应的中文字源是“阿”,是阿的横折那个部首。
抱歉我对我的电脑的日文输入法还是不太会用,不多做范例了。 :-p
《席殊 实用硬笔字 60 小时训练》
你要是看过席殊同志写的字就知道要多难看就有多难看了,但我为什么还要买这本江西美术出版社出版的这本书呢?
因为它的拆字。
这本书不是字帖用于临摹,而是一本解析汉字的书,把汉字拆成各种笔画和笔顺,然后一步一步让人养成一种正确的习惯。
很明显,临摹不适合我,我还是更愿意按照自己的风格来写字。
《儿童练耳入门》和《吉他自学三月通》
这两本书相辅相成,《卡尔卡西》的最大缺点-是它用五线谱,而它在乐理章节又非常薄弱。
人民音乐出版社出版的《儿童练耳入门》就是我补充乐理知识的办法,抱歉,虽然是写给儿童的啊,但这本书的作者可是非常牛的作曲家-李重光先生。
这本书的好处是从学习方法上入手,养成对声音的一种条件反射。这本书的缺点是用钢琴做演示的。
刘传和朱迎的《吉他自学三月通》,也是一本在基础上非常花功夫的书,从姿势,到把位,到基本的乐理。
同时这本书使用了吉他专用的六线谱,对于快速上手也有好处。
那么书都买了,该订一个读书计划,要不然就成了最后不了了之的搁置品了。
《无师自通 学日语》是暂时搁置的,因为实在没空看。
《Ajax 高级程序设计》因为不是工作需要,所以可以在工作闲暇时看看。
早晨 6 点钟起床,6 点半梳洗完,可以有一个小时时间:
6:30 - 7:30: 《席殊 实用硬笔字 60 小时训练》+练字
晚上 7:30 到家,吃饭半个小时,8:00-10:00 有两个小时看书。
8:00 - 10:00: 《吉他自学三月通》 练吉他先找到音的感觉,然后再看 《儿童练耳入门》 把五线谱补回来,再去看 《卡尔卡西》。
生活是多姿多彩的,但是依然要让它变得充足而丰富。
相爱过的人离别后是否可以继续做朋友
以前没有考虑过这个问题,因为一散了就打死不相往来了,我也不想和她们往来,确实话不投机。
那么,两个相爱过的、也互相伤害过的人离别后是否可以继续做朋友呢?
我的所有朋友都建议我彻底分了,人散了以后都会有各自的感情,不要在牵扯到一起互相影响。
为什么不想彻底断交,这牵扯到两个问题:
1、两个人是否都互相欣赏,不想失去对方?
2、有必要不成恋人,就连朋友也不做了吗?-我不是人云亦云的人,先想想可能性和可行性。
我觉得这取决于心态,两个人如果能都把心态放正了,认清自己的位置,以全新的态度面对自己的新的感情,以正确的态度面对对方,应该也是问题不大的。就怕余情未了,看着旧恋人和别人亲热,自己在旁边吃醋。
四个问题,关系到是否可能继续做朋友:
1、两人是否可以对对方处以正确的态度
这里的关键因素在于两个人的注意力在哪里,是依然在对方身上,还是已经摆放到了正确的位置上。
2、两人是否因为有过感情而有所防备和隔阂?
离别之前肯定会有不少冷言冷语造成的伤害,无论来自哪一方面,它们是否会造成隔阂?
是否会因为互相防备而疏远?
3、继续做朋友的目的是什么?
朋友分利益朋友和感情朋友两种,如果没有利益关系如何做朋友?如果已经没有感情了如何做朋友?
4、周围人的心态?
周围人的心态是如何的,两人新的对象会如何看待旧情人之间的这种关系?认识的家人呢?
那么,两个相爱过的、也互相伤害过的人离别后是否可以继续做朋友呢?
我的所有朋友都建议我彻底分了,人散了以后都会有各自的感情,不要在牵扯到一起互相影响。
为什么不想彻底断交,这牵扯到两个问题:
1、两个人是否都互相欣赏,不想失去对方?
2、有必要不成恋人,就连朋友也不做了吗?-我不是人云亦云的人,先想想可能性和可行性。
我觉得这取决于心态,两个人如果能都把心态放正了,认清自己的位置,以全新的态度面对自己的新的感情,以正确的态度面对对方,应该也是问题不大的。就怕余情未了,看着旧恋人和别人亲热,自己在旁边吃醋。
四个问题,关系到是否可能继续做朋友:
1、两人是否可以对对方处以正确的态度
这里的关键因素在于两个人的注意力在哪里,是依然在对方身上,还是已经摆放到了正确的位置上。
2、两人是否因为有过感情而有所防备和隔阂?
离别之前肯定会有不少冷言冷语造成的伤害,无论来自哪一方面,它们是否会造成隔阂?
是否会因为互相防备而疏远?
3、继续做朋友的目的是什么?
朋友分利益朋友和感情朋友两种,如果没有利益关系如何做朋友?如果已经没有感情了如何做朋友?
4、周围人的心态?
周围人的心态是如何的,两人新的对象会如何看待旧情人之间的这种关系?认识的家人呢?
更年期的老妈
limit 过生日时送了皮带,非常漂亮,只可惜他腰比我粗,所以不是特别合适,穿了两天,裤子就这么搭叭着两天。
早晨,嘱咐老妈:
老妈,今天帮我去给皮带打三个孔吧,这皮带实在是太松了。补鞋的地方就可以。
老妈满口答应:
好的,儿子!
下午回家,询问老妈:
老妈,皮带打孔了吗?
老妈答应:
打了,就在你床上呢。
吃晚饭时,老妈侃起:
儿子,你知道什么地方能给皮带打孔吗?
我心中狐疑-难道去了什么特殊的地方,或有特殊的人帮忙?
沉默一阵
老妈回道:
只有补鞋的地方可以,其他地方我去看了,都不行
顿时差点喷饭-我早晨不是这么和你说的么? -_-#
立马赞道:老妈你真是聪明~绝顶~!
赶紧低头,吃饭。
早晨,嘱咐老妈:
老妈,今天帮我去给皮带打三个孔吧,这皮带实在是太松了。补鞋的地方就可以。
老妈满口答应:
好的,儿子!
下午回家,询问老妈:
老妈,皮带打孔了吗?
老妈答应:
打了,就在你床上呢。
吃晚饭时,老妈侃起:
儿子,你知道什么地方能给皮带打孔吗?
我心中狐疑-难道去了什么特殊的地方,或有特殊的人帮忙?
沉默一阵
老妈回道:
只有补鞋的地方可以,其他地方我去看了,都不行
顿时差点喷饭-我早晨不是这么和你说的么? -_-#
立马赞道:老妈你真是聪明~绝顶~!
赶紧低头,吃饭。
☆陶喆-今天你要嫁給我☆
今天肠胃又开始罢工,去红麻辣吃鲜虾水蛋的时候听到。
结果下午一回来第一件事情-就是把Jay 的《Still Fantsy》和陶喆这首《太美丽》的CD 订下。
☆陶喆太美丽☆
春暖的花开带走冬天的感伤
微风吹来浪漫的气息
每一首情歌忽然充满意义
我就在此刻突然见到你
春暖的花香带走冬天的饥寒
微风吹来意外的爱情
鸟儿的高歌拉近我们距离
我就在此刻突然爱上你
听我说
手牵手跟我一起走
创造幸福的生活
昨天你来不及
明天就会可惜
今天嫁给我好吗
Jolin in the house
DT(david tao) in the house
Our love in the house
夏日的热情打动春天的懒散
阳光照耀美满的家庭
每一首情歌都会勾起回忆
想当年我是怎么认识你
冬天的忧伤结束秋天的孤单
微风吹来苦辣的思念
鸟儿的高歌唱着不要别离
此刻我多么想要拥抱你
听我说
手牵手跟我一起走
过着安定的生活
昨天你来不及
明天就会可惜
今天你要嫁给我
听我说
手牵手我们一起走
把你一生交给我
昨天不要回头
明天要到白首
今天你要嫁给我
听着礼堂的钟声
我们在上帝和亲友面前见证
这对男女生就要结为夫妻
不要忘了这一切是多么的神圣
你愿意生死苦乐永远和她在一起
爱惜她尊重她
安慰她保护着她
两人同时建立起美满的家庭
你愿意这样做吗
Yes i do!
听我说
手牵手一路到尽头
把你一生交给我
昨天已是过去
明天更多回忆
今天你要嫁给我
结果下午一回来第一件事情-就是把Jay 的《Still Fantsy》和陶喆这首《太美丽》的CD 订下。
☆陶喆太美丽☆
春暖的花开带走冬天的感伤
微风吹来浪漫的气息
每一首情歌忽然充满意义
我就在此刻突然见到你
春暖的花香带走冬天的饥寒
微风吹来意外的爱情
鸟儿的高歌拉近我们距离
我就在此刻突然爱上你
听我说
手牵手跟我一起走
创造幸福的生活
昨天你来不及
明天就会可惜
今天嫁给我好吗
Jolin in the house
DT(david tao) in the house
Our love in the house
夏日的热情打动春天的懒散
阳光照耀美满的家庭
每一首情歌都会勾起回忆
想当年我是怎么认识你
冬天的忧伤结束秋天的孤单
微风吹来苦辣的思念
鸟儿的高歌唱着不要别离
此刻我多么想要拥抱你
听我说
手牵手跟我一起走
过着安定的生活
昨天你来不及
明天就会可惜
今天你要嫁给我
听我说
手牵手我们一起走
把你一生交给我
昨天不要回头
明天要到白首
今天你要嫁给我
听着礼堂的钟声
我们在上帝和亲友面前见证
这对男女生就要结为夫妻
不要忘了这一切是多么的神圣
你愿意生死苦乐永远和她在一起
爱惜她尊重她
安慰她保护着她
两人同时建立起美满的家庭
你愿意这样做吗
Yes i do!
听我说
手牵手一路到尽头
把你一生交给我
昨天已是过去
明天更多回忆
今天你要嫁给我
忙碌的16日和朋友的力量
这是一个忙碌的9月16日。
上午先跑回公司,准备好演示文稿,在下午 AKA 举办的内核开发者大会上,做了一个简短的、五分钟的社区介绍。

晚上,邀请了我最好的十五个朋友(算上了朋友太太),实际到达的只有八位,除了 pczou 夫妇可能因为公事,剩下的三个旧同事都没来,可能是真是君子之交淡如水吧。





大喝一声:我奔三啦!
礼品清单:
我的朋友能到来,就是我最大的礼品,小礼品还是要细数一下的 :-)
caihua 和猪手:一起送了一个巨大的海豚宝宝,嗯,我晚上可以抱着它睡了。
limit 和老婆:精致的 manmont 皮带一条。
我的海媛姐姐:好吃的水果蛋糕一个,成了我今天的晚饭了。
我们的淑女菁玮:不愧是淑女,送了古朴典雅的香熏灯一个,正在我桌面上摆着,点燃着 :-)
狗狗:及时雨的手机胶套一个,我的水晶壳已经破到不行;去痘的护肤品一瓶,我更乐意相信睡眠的力量;开心糖果一包,保持开心的良药。
这是一个辞旧迎新的 17 日。
上午睡到十点多爬起来,已经有快半年没这样睡过了。然后把昨天的照片都传到了 flickr 上。
下午去西单的中友商场地下一层动感地带营业厅换取了 OTA 2.0 SIM 卡一张,存储容量一下子增加到了 250 个联系人和 70 条短信,但把我以前的通讯记录和部分短信丢失了。
路过平安里时,把头一闷,闭着眼睛过去的,睡不着。
晚上回到家,一上 flickr,已经有朋友给回复了。让沮丧的我得到了恢复。
尤其是不认识是 hsuanwei 竟然开了瓶香槟 :-)
多谢他了。

有些好人也会干坏事的,一些难以割舍的,说不清道不明的关系,还是让我来担下所有的罪责吧。
听着齐豫的〈橄榄树〉,希望明天会更好。
上午先跑回公司,准备好演示文稿,在下午 AKA 举办的内核开发者大会上,做了一个简短的、五分钟的社区介绍。
晚上,邀请了我最好的十五个朋友(算上了朋友太太),实际到达的只有八位,除了 pczou 夫妇可能因为公事,剩下的三个旧同事都没来,可能是真是君子之交淡如水吧。
大喝一声:我奔三啦!
礼品清单:
我的朋友能到来,就是我最大的礼品,小礼品还是要细数一下的 :-)
caihua 和猪手:一起送了一个巨大的海豚宝宝,嗯,我晚上可以抱着它睡了。
limit 和老婆:精致的 manmont 皮带一条。
我的海媛姐姐:好吃的水果蛋糕一个,成了我今天的晚饭了。
我们的淑女菁玮:不愧是淑女,送了古朴典雅的香熏灯一个,正在我桌面上摆着,点燃着 :-)
狗狗:及时雨的手机胶套一个,我的水晶壳已经破到不行;去痘的护肤品一瓶,我更乐意相信睡眠的力量;开心糖果一包,保持开心的良药。
这是一个辞旧迎新的 17 日。
上午睡到十点多爬起来,已经有快半年没这样睡过了。然后把昨天的照片都传到了 flickr 上。
下午去西单的中友商场地下一层动感地带营业厅换取了 OTA 2.0 SIM 卡一张,存储容量一下子增加到了 250 个联系人和 70 条短信,但把我以前的通讯记录和部分短信丢失了。
路过平安里时,把头一闷,闭着眼睛过去的,睡不着。
晚上回到家,一上 flickr,已经有朋友给回复了。让沮丧的我得到了恢复。
尤其是不认识是 hsuanwei 竟然开了瓶香槟 :-)
多谢他了。
有些好人也会干坏事的,一些难以割舍的,说不清道不明的关系,还是让我来担下所有的罪责吧。
听着齐豫的〈橄榄树〉,希望明天会更好。
Technorati Tags: aka, birthday, linux, tsinghua, puppy, university, xuqingkuang
渐渐地爱上了齐豫的歌
清澈、干净、略带忧伤的调子,具有平抚了受伤的心灵的功效。
以后会慢慢贴出些她的歌吧。
Donde Voy为西班牙语 (英译为:where i go …… ),复古的格调,优美的吉他中音。
下面是歌词:
Donde Voy
all alone i have started my journey
to the darkness of darkness i go
with a reason,i stopped for a moment
in this world full of pleasure so frail
town after town on i travel
pass through faces i know and know not
like a bird in flight,sometimes i topple
time and time again,just farewells
donde voy,donde voy
day by day,my story unfolds
solo estoy,solo estoy
all alone as the day i was born
till your eyes rest in mine,i shall wander
no more darkness i know and know not
for your sweetness i traded my freedom
not knowing a farewell awaits
you know,hearts can be repeatedly broken
making room for the harrows to come
along with my sorrows i buried
my tears,my smiles,your name
donde voy,donde voy
songs of lovetales i sing of no more
solo estoy,solo estoy
once again with my shadows i roam
donde voy,donde voy
all alone as the day i was born
solo estoy,solo estoy
still alone with my shadows i roam
何去何从
独自一人开始我的旅程
一路向着黑暗里的黑暗走去
我必然有所为而来
在这满是短暂欢乐的人世 稍做停留
我一城一城地走
穿过一张又一张知名或不知名的脸
如同飞鸟 偶有失速
一次又一次, 只有离别
我要去的地方 要去的地方
属于我的角本 一天天的展开
我很孤独 很孤独
正如我孤独一个地来到这个世界
在你的视线驻足我眼底之前 我流浪着
以为自己不会再有 有过与不曾有过的孤独
你的甜美让我放弃了自由
未察 另有一个离别等着我
你知道么 心可以一再破碎
让出空间 容纳更多的苦难
如今 连同我的忧伤 我葬下--
我的眼泪 我的微笑 你的名字
我要去的地方 要去的地方
情歌不再被唱颂
再一次带着自己的身影黯然上路
我要去的地方 要去的地方
我将孤独地只身一人来到这世界
伴我上路的 依旧只有我的身影
以后会慢慢贴出些她的歌吧。
Donde Voy为西班牙语 (英译为:where i go …… ),复古的格调,优美的吉他中音。
下面是歌词:
Donde Voy
all alone i have started my journey
to the darkness of darkness i go
with a reason,i stopped for a moment
in this world full of pleasure so frail
town after town on i travel
pass through faces i know and know not
like a bird in flight,sometimes i topple
time and time again,just farewells
donde voy,donde voy
day by day,my story unfolds
solo estoy,solo estoy
all alone as the day i was born
till your eyes rest in mine,i shall wander
no more darkness i know and know not
for your sweetness i traded my freedom
not knowing a farewell awaits
you know,hearts can be repeatedly broken
making room for the harrows to come
along with my sorrows i buried
my tears,my smiles,your name
donde voy,donde voy
songs of lovetales i sing of no more
solo estoy,solo estoy
once again with my shadows i roam
donde voy,donde voy
all alone as the day i was born
solo estoy,solo estoy
still alone with my shadows i roam
何去何从
独自一人开始我的旅程
一路向着黑暗里的黑暗走去
我必然有所为而来
在这满是短暂欢乐的人世 稍做停留
我一城一城地走
穿过一张又一张知名或不知名的脸
如同飞鸟 偶有失速
一次又一次, 只有离别
我要去的地方 要去的地方
属于我的角本 一天天的展开
我很孤独 很孤独
正如我孤独一个地来到这个世界
在你的视线驻足我眼底之前 我流浪着
以为自己不会再有 有过与不曾有过的孤独
你的甜美让我放弃了自由
未察 另有一个离别等着我
你知道么 心可以一再破碎
让出空间 容纳更多的苦难
如今 连同我的忧伤 我葬下--
我的眼泪 我的微笑 你的名字
我要去的地方 要去的地方
情歌不再被唱颂
再一次带着自己的身影黯然上路
我要去的地方 要去的地方
我将孤独地只身一人来到这世界
伴我上路的 依旧只有我的身影
Technorati Tags: music
自己动手,丰衣足食
“自己动手,丰衣足食”
是毛泽东同志在 1939 年 2 月延安生产动员大会上针对根据地日益严重的经济困难局面提出的口号。
在老妈回去料理外公丧事之时,如何料理我娇气无比的胃出现的经济困难:
是每天把我们家的大橱-我的大姨-彭芹同志招呼过来?
还是去下馆子品味世间各种生产线下来的食品?
这就成为了一个很重要的问题。
在经过了无数洋货麦当劳的摧残之后,最终还是选择了响应毛主席的号召,靠自己的双手,把自己的胃搞定。
又经过了翻箱倒柜的折腾,终于将两个西红柿和两个鸡蛋融为了一道菜,红红黄黄,美不胜收。
最大感受,手笨了,切功差劲了很多,没了 14 岁时独立生活时一把小刀将水果切成均匀数份的灵活。
需要继续锻炼了。
争取把彭芹-我的大姨的拿手菜统统学到手!
不多说,开吃!



是毛泽东同志在 1939 年 2 月延安生产动员大会上针对根据地日益严重的经济困难局面提出的口号。
在老妈回去料理外公丧事之时,如何料理我娇气无比的胃出现的经济困难:
是每天把我们家的大橱-我的大姨-彭芹同志招呼过来?
还是去下馆子品味世间各种生产线下来的食品?
这就成为了一个很重要的问题。
在经过了无数洋货麦当劳的摧残之后,最终还是选择了响应毛主席的号召,靠自己的双手,把自己的胃搞定。
又经过了翻箱倒柜的折腾,终于将两个西红柿和两个鸡蛋融为了一道菜,红红黄黄,美不胜收。
最大感受,手笨了,切功差劲了很多,没了 14 岁时独立生活时一把小刀将水果切成均匀数份的灵活。
需要继续锻炼了。
争取把彭芹-我的大姨的拿手菜统统学到手!
不多说,开吃!



Technorati Tags: cook
Leopard 小试(一)
Leopard - Mac OS X 10.5 安装好了 :-)
OK,它有了什么东西在上一篇 Blog 中就已经说明了。
那么让我们来首先分析一下概况,尽管上一篇中基本都说明了。
1. Native 64 bits suppport - 是的,Mac OS X 拥有原生 PPC 64 位支持,这曾经在 Panther 中作为一大特性大吹大擂过一番,这次不同的是,挟 Universal Binrary 之势,Apple 把这 Mach-0 的旧酒,用 Leopard 新装了一遍,那么,它是什么?
$ file /usr/lib/libSystem.B.dylib
/usr/lib/libSystem.B.dylib: Mach-O universal binary with 4 architectures
/usr/lib/libSystem.B.dylib (for architecture ppc): Mach-O dynamically linked shared library ppc
/usr/lib/libSystem.B.dylib (for architecture ppc64): Mach-O 64-bit dynamically linked shared library ppc64
/usr/lib/libSystem.B.dylib (for architecture i386): Mach-O dynamically linked shared library i386
/usr/lib/libSystem.B.dylib (for architecture x86_64): Mach-O 64-bit dynamically linked shared library x86_64
OK, 一目了然,使用了 Mach-0 可执行文件格式的 Darwin,能够将多种平台的二进制代码编译进一个文件中,gcc 使用了这个特性,所以有了一个 APPLE ONLY 的 -arch 参数(详见 man gcc)。
不过 Leopard 有一定好处是,Carbon 程序也能 64 bits 了。
2. Time machine - 需要下一篇细说
3. Complete package - 垄断 。。。 垄断 - 不过必须承认 Apple 官方的软件质量更高。
4. Spaces - 和 XGL 的“把桌面贴到正方体上不同”,Spaces 所做的似乎和早就就有的自由软件 Desktop manager 一样,依然是一个平面,正如名字一样,有的窗口在 No.1 Space,有的在 No.2 Space,你无法指望拖出一半的窗口出当前 Space,然后切换到另外一边相邻的Space,并看到原来拖出去的那部分。
它与 XGL 谁优谁裂,不想评论,不同人有不同喜好,Spaces 在躲避老板上还是有好处的。
Spaces 由于是 Apple 官方推出,比起 Desktop manager 上还是有优势的 - 首先是移动窗口有了 Quartz 加速,播放中的视频在很短的特效中依然继续播放,而 Desktop manager 只是一个静态的截图。但 Desktop manager 的好处是-它是自由软件,它特效更多。
5. Spotlight - Google Desktop 和 Beagle 竞相模仿的对象,失败的 WinFS 的成功反例,但新家的跨机搜索虽然有用,但对我什么吸引力,我只有一台电脑。
6. Core Animation - OS X 的出色框架再添一员,整合 Core Animation 之后的的 Mac OS X 内置大量特效,使得 ISV 开发更酷的软件提供了基础。它或许也是未来 Mac OS X 完全 3D 化的前兆。
7. Voice Over - 感觉像被完全重写了,提供了更多自定义性的设置,当然这不是我所关心的,新加了一名叫 Alex 的男音,利用标点控制语速和“感情”上的能力依然不行,但是明显这次录音比以前好很多,清晰很多。
OK,它有了什么东西在上一篇 Blog 中就已经说明了。
那么让我们来首先分析一下概况,尽管上一篇中基本都说明了。
1. Native 64 bits suppport - 是的,Mac OS X 拥有原生 PPC 64 位支持,这曾经在 Panther 中作为一大特性大吹大擂过一番,这次不同的是,挟 Universal Binrary 之势,Apple 把这 Mach-0 的旧酒,用 Leopard 新装了一遍,那么,它是什么?
$ file /usr/lib/libSystem.B.dylib
/usr/lib/libSystem.B.dylib: Mach-O universal binary with 4 architectures
/usr/lib/libSystem.B.dylib (for architecture ppc): Mach-O dynamically linked shared library ppc
/usr/lib/libSystem.B.dylib (for architecture ppc64): Mach-O 64-bit dynamically linked shared library ppc64
/usr/lib/libSystem.B.dylib (for architecture i386): Mach-O dynamically linked shared library i386
/usr/lib/libSystem.B.dylib (for architecture x86_64): Mach-O 64-bit dynamically linked shared library x86_64
OK, 一目了然,使用了 Mach-0 可执行文件格式的 Darwin,能够将多种平台的二进制代码编译进一个文件中,gcc 使用了这个特性,所以有了一个 APPLE ONLY 的 -arch 参数(详见 man gcc)。
不过 Leopard 有一定好处是,Carbon 程序也能 64 bits 了。
2. Time machine - 需要下一篇细说
3. Complete package - 垄断 。。。 垄断 - 不过必须承认 Apple 官方的软件质量更高。
4. Spaces - 和 XGL 的“把桌面贴到正方体上不同”,Spaces 所做的似乎和早就就有的自由软件 Desktop manager 一样,依然是一个平面,正如名字一样,有的窗口在 No.1 Space,有的在 No.2 Space,你无法指望拖出一半的窗口出当前 Space,然后切换到另外一边相邻的Space,并看到原来拖出去的那部分。
它与 XGL 谁优谁裂,不想评论,不同人有不同喜好,Spaces 在躲避老板上还是有好处的。
Spaces 由于是 Apple 官方推出,比起 Desktop manager 上还是有优势的 - 首先是移动窗口有了 Quartz 加速,播放中的视频在很短的特效中依然继续播放,而 Desktop manager 只是一个静态的截图。但 Desktop manager 的好处是-它是自由软件,它特效更多。
5. Spotlight - Google Desktop 和 Beagle 竞相模仿的对象,失败的 WinFS 的成功反例,但新家的跨机搜索虽然有用,但对我什么吸引力,我只有一台电脑。
6. Core Animation - OS X 的出色框架再添一员,整合 Core Animation 之后的的 Mac OS X 内置大量特效,使得 ISV 开发更酷的软件提供了基础。它或许也是未来 Mac OS X 完全 3D 化的前兆。
7. Voice Over - 感觉像被完全重写了,提供了更多自定义性的设置,当然这不是我所关心的,新加了一名叫 Alex 的男音,利用标点控制语速和“感情”上的能力依然不行,但是明显这次录音比以前好很多,清晰很多。
Leopard
http://www.apple.com/macosx/leopard/
1 64位原生支持,但同时亦有32位兼容
2 时光机(Time Machine),这个特性对那些没有备份习惯的用户所准备的,时光机就是一个自动备份系统,可以为您备份文档、图片、音乐、你电脑里任何可以备份的东西。而它最具特色的地方就是它备份的方式,这也是它得到这个名字的原因,它可以必免覆盖原文档。而通过日期来快速的恢复你的文档。另外它还支持第三方程序!
3 软件包,包括Boot Camp、Front Row、PhotoBooth,它们都将是Leopard的一部分
4 虚拟桌面(Space),用户可以创建多个桌面,来按排它们的工作,而不同桌面上的文档可以通过拖拉方式进行转移。
5 Spotlight,这也是tiger的特性之一,但在Leopard里它将变得更强大。现在Spotlight可以搜索其他电脑和服务器上的文件了。
6 核心动画效果(Core Animation)
7 语音识别(VoiceOver),语音更自然,听上去像真人在朗读,支持中文和日文了。
8 Mail再度改进,模版(支持Html编辑)、待办事项、邮件记事功能
9 Dashboard,各种第三方的Widgets数量已经超过2500了,我们为开发者提供了名为Dashcode的开发软件,开发一个Widget极其简单。
10 iChat,支持多帐户登录、隐身、动态图标、视频录象和分页标签对话,iChat Theater功能可以向对方播放视频流、Keynote等等。还有很多视觉特效。
Leopard将会在明年春发布。

1 64位原生支持,但同时亦有32位兼容
2 时光机(Time Machine),这个特性对那些没有备份习惯的用户所准备的,时光机就是一个自动备份系统,可以为您备份文档、图片、音乐、你电脑里任何可以备份的东西。而它最具特色的地方就是它备份的方式,这也是它得到这个名字的原因,它可以必免覆盖原文档。而通过日期来快速的恢复你的文档。另外它还支持第三方程序!
3 软件包,包括Boot Camp、Front Row、PhotoBooth,它们都将是Leopard的一部分
4 虚拟桌面(Space),用户可以创建多个桌面,来按排它们的工作,而不同桌面上的文档可以通过拖拉方式进行转移。
5 Spotlight,这也是tiger的特性之一,但在Leopard里它将变得更强大。现在Spotlight可以搜索其他电脑和服务器上的文件了。
6 核心动画效果(Core Animation)
7 语音识别(VoiceOver),语音更自然,听上去像真人在朗读,支持中文和日文了。
8 Mail再度改进,模版(支持Html编辑)、待办事项、邮件记事功能
9 Dashboard,各种第三方的Widgets数量已经超过2500了,我们为开发者提供了名为Dashcode的开发软件,开发一个Widget极其简单。
10 iChat,支持多帐户登录、隐身、动态图标、视频录象和分页标签对话,iChat Theater功能可以向对方播放视频流、Keynote等等。还有很多视觉特效。
Leopard将会在明年春发布。
Orz - 一直以为是拟声词,没想到。。。 -_-#
Orz,又称作失意体前屈,是一种源自于日本的网路象形文字(或心情图示),并且在2004年时在日本、台湾、大陆与香港俨然已经成为一种新兴的网路文化。
失意体前屈,原本指的是网路上流行的表情符号:_| |○。看起来像是一个人跪倒在地上,低着头,一副“天啊,你为何这样对我”的动作,虽然简单却很传神。
在初期的时候,并没有人对这个符号起个名字,“失意体前屈”也是后来才出现的,据说是某个餐厅的座垫上绣着这五个字,至于再之前又是谁想到的,就不可考了。
后来,又有人发现,用简单的三个英文字也可以表现这个动作,于是Orz就开始流行了。后来,更有Orz的日志软体、日志网站!
这种文字可以写作Orz、oro、Or2、On_、Otz、OTL、sto、Jto、○| |_等,但其中以“Orz”最为常用;并有混合型,表示无可奈何的“囧rz”。原始用意带有“悔恨”、“悲愤”、“无力回天”等的含意,最明显的用法就是在于被甩(失恋)的时候。
Orz随着使用的广泛,其涵意逐渐增加,除了一开始的KUSO与无可奈何或失意之外,开始引申为正面的对人“拜服”“钦佩”的意思。另外也有较反面的“拜托!”“被你打败了!”“真受不了你!”这类意思的用法。台湾摇滚乐团五月天于2005年8月发表的歌曲《恋爱ing》就有“超感谢你,让我重生,整个Orz”一句。
在2006年1月22日,台湾的“中华民国学测”的国文科试题中,其中有一题是将被误用的语言(被报章杂志或是网际网路等影响)改成正常白话文,其题目范例就有“3Q得Orz→感谢得五体投地”一段,引起相当大的争议。
更多的Orz
全形:
_| |○ ← 右向
○| |_ ← 左向
○|_| ← 逆天
半形:
STO ← 右向
OTZ ← 左向
OLS ← 左向逆天
ZJO ← 右向逆天
半形小写:
sto ← 右向
orz ← 左向
ots ← 左向逆天
z_/o ← 右向逆天
迷你形:
no ← 右向
on ← 左向
ou ← 左向逆天
uo ← 右向逆天
团体进行的情况(又叫作“团败”)
集中式:
. __ __
\|\_\ ∠ /|/
|○|. .|○|
_| |○ _ _ ○| |_
/ /|) (|\ \
. | | | |
/ / \ \
扩散式:
_ _
... (|\ \.. / /|)
| | | |
\ \ / /
○| |_ __才坐才斤_ _| |○
∠ /|/ \|\_\
.. |○| ... |○|
orz ←这是小孩
OTZ ←这是大人
OTL ←这是完全失落
or2 ←这是屁股特别翘的
or2=3 ←这是放了个屁的
Or2 ←这是头大身体小的翘屁股
Or? ←这也是头大身体小的翘屁股
orZ ←这是下半身肥大
OTz ←这是举重选手吧
○rz ←这是大头
●rz ←这是黑人头先生
Xrz ←这是刚被爆头完
6rz ←这是魔人普乌
On ←这是婴儿
crz ←这是机车骑士
囧rz ←这是念“炯”
崮rz ←这是囧国国王
莔rz ←这是囧国皇后
商rz ←这是戴斗笠的囧
st冏 ←楼上的他老婆吗
sto ←换一边跪
org ←女娲/美人鱼
曾rz ←假面超人
益r2 ←闭起眼睛,很痛苦且咬牙切齿的脸;另一说法为无敌铁金刚
★rz ←武藤游戏
口rz ← 豆腐先生
__Drz ← 爆脑浆
prz ← 长发垂地的orz
@rz ← 呆滞垂地的orz
srQ ← 换一边并舔地的orz
OGC ← 男性diy
oec ← 男性diy (左手)
O8>C ← 女性diy
O8GC ← 人妖diy
OGC←(很黄)
圙rz ← 这是老人家的面
囿rz ← 这是追追做出orz
胎rz ← 这个是没眼睛的
囜rz ← 没有眼和口的
国rz ← 这是歪咀的
国rz ← 这是无话可说的
苉rz ← 这是女的
曶rz ← 这是被人捉奸在床的表情
Ora ←衍伸用法,不过脚是跪着状态。
or7 ←尖屁股
囧兴←乌龟
国T2
圞T2
圞T2
圛T2
……………………
on ←(一开始还是小婴儿)
orz ←(身体明显的变长(长高了))
Orz ←(开始要上先修班、家教班、才艺班头越来越大)
Or2 ←(常常没写没带作业又总是让成绩单一片鲜红,动不动小屁屁就挨了一顿打,开始有浮肿的趋势。)
JTO Or2 ←( 就这样混阿混的,在偶然的那一天遇到了他的另一半)
“夫妻交拜”
Ot2 ←(可惜没多久就拿了好人卡,祸不单行的去做
全身检查时发现有了骨刺。)
囧t2 ←(真是命苦阿....)
圁rz 老了之后就变这副德行
OTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTZ
蜈蚣......
Oππππππππππππππ~O---------------------------------------------
蛇...

失意体前屈,原本指的是网路上流行的表情符号:_| |○。看起来像是一个人跪倒在地上,低着头,一副“天啊,你为何这样对我”的动作,虽然简单却很传神。
在初期的时候,并没有人对这个符号起个名字,“失意体前屈”也是后来才出现的,据说是某个餐厅的座垫上绣着这五个字,至于再之前又是谁想到的,就不可考了。
后来,又有人发现,用简单的三个英文字也可以表现这个动作,于是Orz就开始流行了。后来,更有Orz的日志软体、日志网站!
这种文字可以写作Orz、oro、Or2、On_、Otz、OTL、sto、Jto、○| |_等,但其中以“Orz”最为常用;并有混合型,表示无可奈何的“囧rz”。原始用意带有“悔恨”、“悲愤”、“无力回天”等的含意,最明显的用法就是在于被甩(失恋)的时候。
Orz随着使用的广泛,其涵意逐渐增加,除了一开始的KUSO与无可奈何或失意之外,开始引申为正面的对人“拜服”“钦佩”的意思。另外也有较反面的“拜托!”“被你打败了!”“真受不了你!”这类意思的用法。台湾摇滚乐团五月天于2005年8月发表的歌曲《恋爱ing》就有“超感谢你,让我重生,整个Orz”一句。
在2006年1月22日,台湾的“中华民国学测”的国文科试题中,其中有一题是将被误用的语言(被报章杂志或是网际网路等影响)改成正常白话文,其题目范例就有“3Q得Orz→感谢得五体投地”一段,引起相当大的争议。
更多的Orz
全形:
_| |○ ← 右向
○| |_ ← 左向
○|_| ← 逆天
半形:
STO ← 右向
OTZ ← 左向
OLS ← 左向逆天
ZJO ← 右向逆天
半形小写:
sto ← 右向
orz ← 左向
ots ← 左向逆天
z_/o ← 右向逆天
迷你形:
no ← 右向
on ← 左向
ou ← 左向逆天
uo ← 右向逆天
团体进行的情况(又叫作“团败”)
集中式:
. __ __
\|\_\ ∠ /|/
|○|. .|○|
_| |○ _ _ ○| |_
/ /|) (|\ \
. | | | |
/ / \ \
扩散式:
_ _
... (|\ \.. / /|)
| | | |
\ \ / /
○| |_ __才坐才斤_ _| |○
∠ /|/ \|\_\
.. |○| ... |○|
orz ←这是小孩
OTZ ←这是大人
OTL ←这是完全失落
or2 ←这是屁股特别翘的
or2=3 ←这是放了个屁的
Or2 ←这是头大身体小的翘屁股
Or? ←这也是头大身体小的翘屁股
orZ ←这是下半身肥大
OTz ←这是举重选手吧
○rz ←这是大头
●rz ←这是黑人头先生
Xrz ←这是刚被爆头完
6rz ←这是魔人普乌
On ←这是婴儿
crz ←这是机车骑士
囧rz ←这是念“炯”
崮rz ←这是囧国国王
莔rz ←这是囧国皇后
商rz ←这是戴斗笠的囧
st冏 ←楼上的他老婆吗
sto ←换一边跪
org ←女娲/美人鱼
曾rz ←假面超人
益r2 ←闭起眼睛,很痛苦且咬牙切齿的脸;另一说法为无敌铁金刚
★rz ←武藤游戏
口rz ← 豆腐先生
__Drz ← 爆脑浆
prz ← 长发垂地的orz
@rz ← 呆滞垂地的orz
srQ ← 换一边并舔地的orz
OGC ← 男性diy
oec ← 男性diy (左手)
O8>C ← 女性diy
O8GC ← 人妖diy
OGC←(很黄)
圙rz ← 这是老人家的面
囿rz ← 这是追追做出orz
胎rz ← 这个是没眼睛的
囜rz ← 没有眼和口的
国rz ← 这是歪咀的
国rz ← 这是无话可说的
苉rz ← 这是女的
曶rz ← 这是被人捉奸在床的表情
Ora ←衍伸用法,不过脚是跪着状态。
or7 ←尖屁股
囧兴←乌龟
国T2
圞T2
圞T2
圛T2
……………………
on ←(一开始还是小婴儿)
orz ←(身体明显的变长(长高了))
Orz ←(开始要上先修班、家教班、才艺班头越来越大)
Or2 ←(常常没写没带作业又总是让成绩单一片鲜红,动不动小屁屁就挨了一顿打,开始有浮肿的趋势。)
JTO Or2 ←( 就这样混阿混的,在偶然的那一天遇到了他的另一半)
“夫妻交拜”
Ot2 ←(可惜没多久就拿了好人卡,祸不单行的去做
全身检查时发现有了骨刺。)
囧t2 ←(真是命苦阿....)
圁rz 老了之后就变这副德行
OTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTZ
蜈蚣......
Oππππππππππππππ~O---------------------------------------------
蛇...
Technorati Tags: fun
乐高积木 + 程控技术 = ?
这玩意儿钩起了我对机器人的回忆。






官方主页:http://mindstorms.lego.com/
详情请看:http://www.elesson.com.cn/modules/ipboard/index.php?showtopic=33939
更多照片:http://kurtxia.jetphoto.cn/web/default/
淘宝上有前一代 RCX 的版本,不过价格非常昂贵:
http://auction1.taobao.com/auction/0/item_detail-0db2-3671193cccf2a01ace146b4895357455.jhtml?p=1-1
http://auction1.taobao.com/auction/0/item_detail-0db2-42f7b80f3fb061c360bfa6637ab4c705.jhtml?p=1-10
有空可以找一个旧的 iPod,拿里面的 ARM 处理器看看能干点什么。






官方主页:http://mindstorms.lego.com/
详情请看:http://www.elesson.com.cn/modules/ipboard/index.php?showtopic=33939
更多照片:http://kurtxia.jetphoto.cn/web/default/
淘宝上有前一代 RCX 的版本,不过价格非常昂贵:
http://auction1.taobao.com/auction/0/item_detail-0db2-3671193cccf2a01ace146b4895357455.jhtml?p=1-1
http://auction1.taobao.com/auction/0/item_detail-0db2-42f7b80f3fb061c360bfa6637ab4c705.jhtml?p=1-10
有空可以找一个旧的 iPod,拿里面的 ARM 处理器看看能干点什么。
龙的世界 - Discovery
一部片子〈龙的世界〉,由探索频道(Discovery Channel)出品。
是部不错的片子,前 50% 是有很好的推理构成,很典型的 Discovery 风格,后半部分可以当电影来看。
对于同样对于龙有过想法的人可以看看。

下载 种子
是部不错的片子,前 50% 是有很好的推理构成,很典型的 Discovery 风格,后半部分可以当电影来看。
对于同样对于龙有过想法的人可以看看。
下载 种子
printf self
Below C code will print the source code itself.
#include
char buf[100][1000]; int cur=-1;
void P1(char *p) {sprintf(buf[ cur],p);} //record p to buf
void P2(char *p) { printf(p); putchar(10);} //print p and change line
void P3() {int i;for(i=0;i");
P1("char buf[100][1000]; int cur=-1;");
P1("void P1(char *p) {sprintf(buf[ cur],p);}");
P1("void P2(char *p) { printf(p); putchar(10);}");
P1("void P3() {int i;for(i=0;i");
P2("char buf[100][1000]; int cur=-1;");
P2("void P1(char *p) {sprintf(buf[ cur],p);}");
P2("void P2(char *p) { printf(p); putchar(10);}");
P2("void P3() {int i;for(i=0;i
#include
char buf[100][1000]; int cur=-1;
void P1(char *p) {sprintf(buf[ cur],p);} //record p to buf
void P2(char *p) { printf(p); putchar(10);} //print p and change line
void P3() {int i;for(i=0;i");
P1("char buf[100][1000]; int cur=-1;");
P1("void P1(char *p) {sprintf(buf[ cur],p);}");
P1("void P2(char *p) { printf(p); putchar(10);}");
P1("void P3() {int i;for(i=0;i");
P2("char buf[100][1000]; int cur=-1;");
P2("void P1(char *p) {sprintf(buf[ cur],p);}");
P2("void P2(char *p) { printf(p); putchar(10);}");
P2("void P3() {int i;for(i=0;i
Technorati Tags: freesoftware, language, linux, tips
Big big smile

作者廖冰:

Brian Behlendorf 造访 CSIP
抱歉这是份起草时间太长的 blog,这篇本该8月23日就发出的 blog 一直拖到今天。

Brian Behlendorf 于8月23日下午 2:30 造访了位于羊坊店路5号博望园10号信息产业部软件与集成电路促进中心(CSIP)。
我有幸参加并将会议记录了下来。
Brian Behlendorf 回答了很多关于自由软件、关于社区、关于 Apache 的问题,都非常有意思,比如作为一名社区的管理者如何管理社区,以及如何选择一个合适的 Licences 来平衡社区的力量 - Licences 给予用户的越多,社区将做得越大。
Brian Behlendorf 还回答了为什么自由软件以及社区在亚洲地区没有欧美发达。
大致是:
一、首先是语言障碍,
二、文化-西方文化更偏向于为追求真理而争斗
三、学生的自由时间很多
四、史前时代的计算机更加接近机器的本质,能够接触到更加底层的东西。
相关链接:
http://oss.org.cn/modules/news/article.php?storyid=657
http://forum.oss.org.cn/viewtopic.php?t=3491

会议录音位于:
ftp://www.linux-ren.org/pub/kk/resources/csipevent/Tue-Aug-22-2006-BrianBehlendorf-CSIP.amr
Brian Behlendorf 于8月23日下午 2:30 造访了位于羊坊店路5号博望园10号信息产业部软件与集成电路促进中心(CSIP)。
我有幸参加并将会议记录了下来。
Brian Behlendorf 回答了很多关于自由软件、关于社区、关于 Apache 的问题,都非常有意思,比如作为一名社区的管理者如何管理社区,以及如何选择一个合适的 Licences 来平衡社区的力量 - Licences 给予用户的越多,社区将做得越大。
Brian Behlendorf 还回答了为什么自由软件以及社区在亚洲地区没有欧美发达。
大致是:
一、首先是语言障碍,
二、文化-西方文化更偏向于为追求真理而争斗
三、学生的自由时间很多
四、史前时代的计算机更加接近机器的本质,能够接触到更加底层的东西。
相关链接:
http://oss.org.cn/modules/news/article.php?storyid=657
http://forum.oss.org.cn/viewtopic.php?t=3491

会议录音位于:
ftp://www.linux-ren.org/pub/kk/resources/csipevent/Tue-Aug-22-2006-BrianBehlendorf-CSIP.amr
Technorati Tags: conference, freesoftware, linux, people
Bryan O'Bryan 转投 Linux 阵营。
Bryan O'Bryan 是一名资深的苹果平台软件开发者和著名苹果主题论坛ResExcellence.com的管理者,公开投向Linux。他是继Cory Doctorow,Mark Pilgrim ,Thom Holwerda之后又一个离开苹果Mac OSX。
有篇他的公告译文:http://www.pkblogs.com/zhcn/2006/07/translationbryan-obryan-why-i-ditched.html
我也是一个从 Mac 投奔到 Linux 人,我有一台 PowerBook 17",上面运行着 PPC 版本的 Gentoo,在经过了长期使用之后,觉得自由软件更适合自己。
Bryan 之所以投奔到 Linux 社区,是因为 Mac 社区内人的高傲与刻薄,最近 Linux 公社上似乎又有相关争论,与之相对应的,Linux 社区氛围明显好了很多。
国内社区又与国外有所不同,更多人认为自己是一名用户,而不是一名受益者,此区别在于受益对象,用户付费给软件作者,作者受益,而自由软件作者无私的将自己的作品贡献出来,依然会受到诸多指责。自命不凡的人指责苹果软件不好我能理解,他们为此付费了,但在 PC 上跑着盗版 Windows 和 Linux 的用户认为自己不同凡响就有点难以理解了。
Linux 社区的概念是:有需求?自己动手。
一点牢骚,建议大家在逛国内 Linux 论坛的同时,也一并逛逛国外的论坛,邮件列表,对培养性情还是有一定好处的。
不过说真的,Mac 社区内自命不凡的人和 Linux 社区内把自己当用户的人,总体数量应该是差不多的。
不管哪个社区,真正有水平的人都不会陷入那样的怪圈。
有篇他的公告译文:http://www.pkblogs.com/zhcn/2006/07/translationbryan-obryan-why-i-ditched.html
我也是一个从 Mac 投奔到 Linux 人,我有一台 PowerBook 17",上面运行着 PPC 版本的 Gentoo,在经过了长期使用之后,觉得自由软件更适合自己。
Bryan 之所以投奔到 Linux 社区,是因为 Mac 社区内人的高傲与刻薄,最近 Linux 公社上似乎又有相关争论,与之相对应的,Linux 社区氛围明显好了很多。
国内社区又与国外有所不同,更多人认为自己是一名用户,而不是一名受益者,此区别在于受益对象,用户付费给软件作者,作者受益,而自由软件作者无私的将自己的作品贡献出来,依然会受到诸多指责。自命不凡的人指责苹果软件不好我能理解,他们为此付费了,但在 PC 上跑着盗版 Windows 和 Linux 的用户认为自己不同凡响就有点难以理解了。
Linux 社区的概念是:有需求?自己动手。
一点牢骚,建议大家在逛国内 Linux 论坛的同时,也一并逛逛国外的论坛,邮件列表,对培养性情还是有一定好处的。
不过说真的,Mac 社区内自命不凡的人和 Linux 社区内把自己当用户的人,总体数量应该是差不多的。
不管哪个社区,真正有水平的人都不会陷入那样的怪圈。
I translated freshy wordpress theme to Simplified Chinese
Freshy is a great wordpress with a alterability header and linkbar, pretty web browser compatible, cool interface, and the most important the theme works with the Yammyamm multi-language switcher plugin.
I am using them on my site, and they are works perfect.
The are great products made by Julien De Luca.
I had translated the theme to Simplified Chinese and share it here.
Just upack it into Freshy theme folder and add codename zh_CN, short name cn into yammyamm language list.
Download here: freshy_zh_CN.zip
I am using them on my site, and they are works perfect.
The are great products made by Julien De Luca.
I had translated the theme to Simplified Chinese and share it here.
Just upack it into Freshy theme folder and add codename zh_CN, short name cn into yammyamm language list.
Download here: freshy_zh_CN.zip
Technorati Tags: freshy, translation, web, website, wordpress
寻寻觅觅我的爱
xcx.pl 这个来自波兰的免费空间,可能是看见了 blog.mydonews.com 批头挂彩,终于按捺不住和万人迷 Google AdSense 联姻,成为了 Google 众多小白脸中的一个。
虽说现在 xcx.pl 上的站点一个一个"头顶五星红旗”,“脚踏莲花宝座”,一个一个用户苦不堪言,免费的就是这样,突然有所变动都不会提前通知你。
我当时用的 wordpress 主题有点另类,它是没有 HTML 头的,一上来就是 head 里的内容,xcx.pl 在 head 里加 iframe,所以我的网站居然头顶上的广告显示不出来。可能是这个原因,我无法再提交 blog,所有写下来的东西都无法保存。
Google 驱赶着我找新的房东。。。
从某男博客中看到了 Dreamhost,打折很猛,就像下面的:

做生意做到这份上就不说什么了,虽然只是一年的费用,但一到明年拍屁股走人,天知道有多少服务商学习 dreamhost 的劲头抢客户呢。
dreamhost 的好处:
容量大:空间 2G,MySQL 数据库无限数量和容量
流量大:1T 无敌
功能全:PHP, MySQL 就不提了,居然连 Jabber 和 QuickTime Stream Server 都有,无敌!
后台好:后台很多都是用已经用惯了的自由软件管理程序,比如 phpmyadmin,用起来舒服~
价格好:这可是最大最大的优势,一年才不到十美元,换过来才不到 80 人民币!还送一个顶极玉米!这不像 xcx.pl,付费的有用户许可可不由得他们乱来。
到目前为止觉得服务挺好,速度挺快。
用它要做好一年后拍屁股走人的准备,头一年一折优惠,一年以后每月都要支付头一年一整年的钱。
至于如何申请,看谷歌即可,不多说,说的人太多。
虽说现在 xcx.pl 上的站点一个一个"头顶五星红旗”,“脚踏莲花宝座”,一个一个用户苦不堪言,免费的就是这样,突然有所变动都不会提前通知你。
我当时用的 wordpress 主题有点另类,它是没有 HTML 头的,一上来就是 head 里的内容,xcx.pl 在 head 里加 iframe,所以我的网站居然头顶上的广告显示不出来。可能是这个原因,我无法再提交 blog,所有写下来的东西都无法保存。
Google 驱赶着我找新的房东。。。
从某男博客中看到了 Dreamhost,打折很猛,就像下面的:
做生意做到这份上就不说什么了,虽然只是一年的费用,但一到明年拍屁股走人,天知道有多少服务商学习 dreamhost 的劲头抢客户呢。
dreamhost 的好处:
容量大:空间 2G,MySQL 数据库无限数量和容量
流量大:1T 无敌
功能全:PHP, MySQL 就不提了,居然连 Jabber 和 QuickTime Stream Server 都有,无敌!
后台好:后台很多都是用已经用惯了的自由软件管理程序,比如 phpmyadmin,用起来舒服~
价格好:这可是最大最大的优势,一年才不到十美元,换过来才不到 80 人民币!还送一个顶极玉米!这不像 xcx.pl,付费的有用户许可可不由得他们乱来。
到目前为止觉得服务挺好,速度挺快。
用它要做好一年后拍屁股走人的准备,头一年一折优惠,一年以后每月都要支付头一年一整年的钱。
至于如何申请,看谷歌即可,不多说,说的人太多。
Mac OS X 和 WMV9
jserv 在十八日介绍了 Kostya Shishkov 在 FFmpeg-devel 提出的 [RFC - VC-1 I-frames decoder]。
由于以前的 win32codec 在 Mac OS X 下无法使用,所以我对此表现了很大的兴趣。
经过试验确定确实可以使用,但效率目前仍然十分低下,在我的 PB17" 上只能达到 2 frames/sec.
补丁可以从 http://jserv.sayya.org/mplayer/ffmpeg-vc1.patch.gz 下载
jserver 的 blog 在: http://blog.linux.org.tw/~jserv/archives/001726.html
实际运行效果如:
mplayer -vc help 输出如以下:
由于以前的 win32codec 在 Mac OS X 下无法使用,所以我对此表现了很大的兴趣。
经过试验确定确实可以使用,但效率目前仍然十分低下,在我的 PB17" 上只能达到 2 frames/sec.
补丁可以从 http://jserv.sayya.org/mplayer/ffmpeg-vc1.patch.gz 下载
jserver 的 blog 在: http://blog.linux.org.tw/~jserv/archives/001726.html
实际运行效果如:
$ mplayer -vc ffwmv3 '/tmp/test (DVD 640x480 WMV9)[CRC 9FD2].avi'
MPlayer dev-SVN-r18764-4.0.1 (C) 2000-2006 MPlayer Team
AltiVec found
CPU: PowerPC
Playing /tmp/test (DVD 640x480 WMV9)[CRC 9FD2].avi.
AVI file format detected.
VIDEO: [WMV3] 640x480 24bpp 119.880 fps 1269.1 kbps (154.9 kbyte/s)
Clip info:
Software: VirtualDubMod 1.5.10.1 (build 2366/release)
SUB: Could not determine file format
Cannot load subtitles: /tmp/test (DVD 640x480 WMV9)[CRC 9FD2].txt
==========================================================================
Forced video codec: ffwmv3
Opening video decoder: [ffmpeg] FFmpeg's libavcodec codec family
[wmv3 @ 0x4f2770]This decoder is not supposed to produce picture. Dont report this as a bug!
[wmv3 @ 0x4f2770]Header: 4FF10A01
[wmv3 @ 0x4f2770]Profile 1:
frmrtq_postproc=7, bitrtq_postproc=31
LoopFilter=0, MultiRes=0, FastUVMV=0, Extended MV=0
Rangered=0, VSTransform=1, Overlap=1, SyncMarker=0
DQuant=0, Quantizer mode=0, Max B frames=0
[wmv3 @ 0x4f2770]Extra data: 16 bits left, value: 401F
Selected video codec: [ffwmv3] vfm: ffmpeg (FFmpeg M$ WMV3/WMV9)
==========================================================================
==========================================================================
Opening audio decoder: [mp3lib] MPEG layer-2, layer-3
AUDIO: 48000 Hz, 2 ch, s16be, 192.0 kbit/12.50% (ratio: 24000->192000)
Selected audio codec: [mp3] afm: mp3lib (mp3lib MPEG layer-2, layer-3)
==========================================================================
AO: [macosx] 48000Hz 2ch s16be (2 bytes per sample)
Starting playback...
[wmv3 @ 0x4f2770]I Frame: QP=3 ( 0/2)
[wmv3 @ 0x4f2770]Consumed 12055/12056 bits
VDec: vo config request - 640 x 480 (preferred colorspace: Planar YV12)
Could not find matching colorspace - retrying with -vf scale...
Opening video filter: [scale]
VDec: using Planar YV12 as output csp (no 0)
Movie-Aspect is undefined - no prescaling applied.
SwScaler: using unscaled Planar YV12 -> Packed YUY2 special converter
VO: [macosx] 640x480 => 640x480 Packed YUY2
[wmv3 @ 0x4f2770]I Frame: QP=3 ( 0/2)000 72/ 72 27% 3% 7.5% 32 0
[wmv3 @ 0x4f2770]Consumed 14381/14384 bits
[wmv3 @ 0x4f2770]P Frame: QP=3 ( 0/2)000 76/ 76 27% 4% 7.2% 35 0
Error while decoding frame!
[wmv3 @ 0x4f2770]P Frame: QP=3 ( 0/2)001 80/ 80 26% 4% 6.8% 39 0
Error while decoding frame!
[wmv3 @ 0x4f2770]I Frame: QP=3 ( 0/2)001 84/ 84 24% 3% 6.5% 41 0
[wmv3 @ 0x4f2770]Consumed 36226/36232 bits
[wmv3 @ 0x4f2770]I Frame: QP=3 ( 0/2)000 88/ 88 24% 4% 6.2% 42 0
[wmv3 @ 0x4f2770]Consumed 43567/43568 bits
[wmv3 @ 0x4f2770]P Frame: QP=3 ( 0/2)000 92/ 92 25% 4% 6.0% 43 0
Error while decoding frame!
[wmv3 @ 0x4f2770]I Frame: QP=3 ( 0/2)000 96/ 96 24% 4% 5.8% 43 0
[wmv3 @ 0x4f2770]Consumed 58828/58832 bits
[wmv3 @ 0x4f2770]P Frame: QP=3 ( 0/2)000 100/100 24% 5% 5.6% 43 0
Error while decoding frame!
[wmv3 @ 0x4f2770]I Frame: QP=3 ( 0/2)000 104/104 23% 5% 5.4% 43 0
[wmv3 @ 0x4f2770]Consumed 76199/76200 bits
[wmv3 @ 0x4f2770]P Frame: QP=3 ( 0/2)001 108/108 24% 5% 5.3% 43 0
Error while decoding frame!
[wmv3 @ 0x4f2770]P Frame: QP=3 ( 0/2)001 112/112 23% 5% 5.1% 43 0
Error while decoding frame!
[wmv3 @ 0x4f2770]P Frame: QP=3 ( 0/2)002 116/116 22% 5% 5.0% 43 0
Error while decoding frame!
[wmv3 @ 0x4f2770]P Frame: QP=3 ( 0/2)002 120/120 21% 4% 4.9% 43 0
Error while decoding frame!
[wmv3 @ 0x4f2770]P Frame: QP=3 ( 0/2)002 124/124 21% 4% 4.9% 43 0
Error while decoding frame!
===== 以下输出省略 =====
mplayer -vc help 输出如以下:
$ mplayer -vc help | grep ffwmv
ffwmv1 ffmpeg working FFmpeg M$ WMV1/WMV7 [wmv1]
ffwmv2 ffmpeg problems FFmpeg M$ WMV2/WMV8 [wmv2]
ffwmv3 ffmpeg crashing FFmpeg M$ WMV3/WMV9 [wmv3]
免费的1G网络硬盘
从 digg 上看到了免费的网络硬盘 - www.box.net
非常好用,非常简单,没有广告,免费空间仅有 1G 容量限制。
利用 WebDAV支持直接 mount(就是 iDisk 使用的传输协议,在 Windows 可以使用映射驱动器)。
Windows 的使用方法参考:http://diglog.com/view/2728
首先去 https://www.box.net/signup 注册一个账号。
注册内容非常简单,仅需要填写电子邮件和密码即可。

注册完成之后会回到登录区,输入刚才填入的用户名和密码即可,然后便进入了管理主页面,可以在这里新建目录,上传文件等等操作。

界面非常简单,使用了 Ajax 技术,所有操作都是即时的,每个图标右上角都有一个小向下三角,点击后会弹出菜单进行操作。
非常好的一点是可以为文件添加更加详细的 Info,还能使用 Tags,还能设置 Public 共享和 Private 共享。
唯一需要注意的是删除文件,需要在 Edit 对话框中进行。
同时在 Safari 中是不能依靠拖拽上传文件的。
前面提到 Box.net 使用了 WebDAV 技术,这样便可以向访问本地驱动器一样访问 Box.net。
在 Mac 中可以直接使用 Go(转到)菜单中的 Connect to server(连接到服务器)。

在弹出的对话框中输入如下:

然后输入你注册的用户名和密码

回车后就可以看见 box.net 上的文件了~

之后我们便可以像操作本机上的文件一样操作 Box.net。
除了系统自带的 Connect to server,我们还可以使用大名鼎鼎的文件传输工具 Transmit,它同样支持 WebDAV。
而在 Linux 之上,我们也可以利用 Konqueror 3 以上版本或者 GNOME 的 Connect to server,gnome-vfs 会为我们做好一切。
或者使用 DavFS,直接将 box.net 作为一个文件系统加载:http://dav.sourceforge.net/
作为一个网络硬盘最大的好处是它可以作为你的 Data storage,这样你可以申请一个免费的网络空间,然后把大东西都放在 box.net 上,然后再在网页里调用它。就像下面这样 ;-)
点击文件图标后文件会直接下载,无论什么格式都不会显示在浏览器中,也无法复制链接。
那就点击好了,然后在 Firefox/Safari 的下载管理器中复制链接,IE 用户就要比较郁闷咯 >_<
非常好用,非常简单,没有广告,免费空间仅有 1G 容量限制。
利用 WebDAV支持直接 mount(就是 iDisk 使用的传输协议,在 Windows 可以使用映射驱动器)。
Windows 的使用方法参考:http://diglog.com/view/2728
首先去 https://www.box.net/signup 注册一个账号。
注册内容非常简单,仅需要填写电子邮件和密码即可。

注册完成之后会回到登录区,输入刚才填入的用户名和密码即可,然后便进入了管理主页面,可以在这里新建目录,上传文件等等操作。

界面非常简单,使用了 Ajax 技术,所有操作都是即时的,每个图标右上角都有一个小向下三角,点击后会弹出菜单进行操作。
非常好的一点是可以为文件添加更加详细的 Info,还能使用 Tags,还能设置 Public 共享和 Private 共享。
唯一需要注意的是删除文件,需要在 Edit 对话框中进行。
同时在 Safari 中是不能依靠拖拽上传文件的。
前面提到 Box.net 使用了 WebDAV 技术,这样便可以向访问本地驱动器一样访问 Box.net。
在 Mac 中可以直接使用 Go(转到)菜单中的 Connect to server(连接到服务器)。
在弹出的对话框中输入如下:

然后输入你注册的用户名和密码

回车后就可以看见 box.net 上的文件了~

之后我们便可以像操作本机上的文件一样操作 Box.net。
除了系统自带的 Connect to server,我们还可以使用大名鼎鼎的文件传输工具 Transmit,它同样支持 WebDAV。
而在 Linux 之上,我们也可以利用 Konqueror 3 以上版本或者 GNOME 的 Connect to server,gnome-vfs 会为我们做好一切。
或者使用 DavFS,直接将 box.net 作为一个文件系统加载:http://dav.sourceforge.net/
作为一个网络硬盘最大的好处是它可以作为你的 Data storage,这样你可以申请一个免费的网络空间,然后把大东西都放在 box.net 上,然后再在网页里调用它。就像下面这样 ;-)
点击文件图标后文件会直接下载,无论什么格式都不会显示在浏览器中,也无法复制链接。
那就点击好了,然后在 Firefox/Safari 的下载管理器中复制链接,IE 用户就要比较郁闷咯 >_<
最近在混 Xoops
在 Xoops 上看到 DJ 写的一段话,非常有感触。
----------
源要开,开了之后还要积极参与,形成良性循环。如果只是把别人做好的开源项目或产品拿来包装一下再发布,甚至做成自己的商业产品盈利,这至多只能算是利用开源项目,拿来主义。
---------
原文在:http://xoops.org.cn/modules/wordpress/?p=277
----------
源要开,开了之后还要积极参与,形成良性循环。如果只是把别人做好的开源项目或产品拿来包装一下再发布,甚至做成自己的商业产品盈利,这至多只能算是利用开源项目,拿来主义。
---------
原文在:http://xoops.org.cn/modules/wordpress/?p=277
vim 7.0 release one week ago
Actually I had build it the day after release in my mac.
This version have three new features important for me:
Here's my vim resource profile, modified based others, just unpack it and place it to $HOME.
http://www.kuangxuqing.com/wp-content/uploads/vimrc.gz
Tab support
To create a new tab just input:
: tabe
or press CTRL-N with my vim resource profile.
it will be looks like this:

If you want to switch tabs, just input:
: tabn
or tabp
You also can press CTRL-/ for next tab.
Close tab just enter:
: close
or CTRL-D.
If you want to close all the tabs, or quit vim directly, just enter:
:qa (enter for Quit All)
Online English syntax check
In previous version, you also can check your spell with aspell or other programs, or other vim plugins.
But the intergration spell check is first built-in in this version.
To enable spell check. just enter:
: setlocal spell spelllang=en
You will see like below, the wrong words will be highlight by red color.

If also can select other languages if your vim release words database, you can check it in /usr/share/vim/vim70/spell/ directory.
Automatic completion for development
With this feature, vim goes to be a project center from a normal editor.
In the vim announce, professed to it support C, HTML, Ruby, Python, PHP and the others ready.
I had just only tested C.

To use syntax completion, just press CTRL-X, vim will print:
-- ^X mode (^]^D^E^F^I^K^L^N^O^Ps^U^V^Y)
In this mode, these key means:
^]: Tag completion
^D: Definition completion
^F: File name completion
^I: Path pattern completion
^K: Dictionary pattern completion
^L: Whole line completion
^N: Keyword Local completion
^O: Omni completion
^V: Command-line completion
Other information about new vim, please check vim web site:
www.vim.org
This version have three new features important for me:
- Tab support
- Online English syntax check
- Automatic completion for development
Here's my vim resource profile, modified based others, just unpack it and place it to $HOME.
http://www.kuangxuqing.com/wp-content/uploads/vimrc.gz
Tab support
To create a new tab just input:
: tabe
or press CTRL-N with my vim resource profile.
it will be looks like this:

If you want to switch tabs, just input:
: tabn
or tabp
You also can press CTRL-/ for next tab.
Close tab just enter:
: close
or CTRL-D.
If you want to close all the tabs, or quit vim directly, just enter:
:qa (enter for Quit All)
Online English syntax check
In previous version, you also can check your spell with aspell or other programs, or other vim plugins.
But the intergration spell check is first built-in in this version.
To enable spell check. just enter:
: setlocal spell spelllang=en
You will see like below, the wrong words will be highlight by red color.

If also can select other languages if your vim release words database, you can check it in /usr/share/vim/vim70/spell/ directory.
Automatic completion for development
With this feature, vim goes to be a project center from a normal editor.
In the vim announce, professed to it support C, HTML, Ruby, Python, PHP and the others ready.
I had just only tested C.

To use syntax completion, just press CTRL-X, vim will print:
-- ^X mode (^]^D^E^F^I^K^L^N^O^Ps^U^V^Y)
In this mode, these key means:
^]: Tag completion
^D: Definition completion
^F: File name completion
^I: Path pattern completion
^K: Dictionary pattern completion
^L: Whole line completion
^N: Keyword Local completion
^O: Omni completion
^V: Command-line completion
Other information about new vim, please check vim web site:
www.vim.org
M$ Vista 用了新字体
简体的叫做微软雅体,繁体的叫做微软正体,让我们来看看它和 Mac OS X 下的默认字体华文黑体来对比一下。
 |
 |
| 标粗 | 粗体 |
共享软件也要厚道
身为一名程序员长期使用盗版软件的不安终于在前两周爆发了,大砍掉了机器上的 D 版软件,然后花了一天把 sf.net 和 versiontracker 逛了一遍。
把所有漏洞统统补上,哼,谁说 mac 上软件少,自由软件和免费软件都能满足所有需要。
上次那个谁做了一个 Windows 下的免费软件替代表,晚点我也做份 mac 上的。
好在 Apple 一向是买硬件送软件的,让我有得以安慰的操作系统可以用,否则只好在 PowerBook 上跑 Linux 了。
但还剩下两个余孽我无法脱离:
Aperture 和 Photoshop ...
为了我的照片,只好继续不安下去。。。
看看能否有天发达了买套正版回来用一辈子。
扯远了,只是想说共享软件 - ecto,我一直拿它写 blog,因为 blog 都由它存储,以前 D 版用很长时间了,为了良心 Renew 成了 Trial,长时间没写 blog 没注意。
今天一打开正常,写完了 blog 提交,让我输入注册码。 -_-#
只好再 Renew 一次,结果重新设置 wordpress 向导,把用 ecto 刚写的 blog 丢了。
只好回到 web 页面上手工重新写一次,郁闷得不行。
只是想说共享软件作者也要凭良心做事,想赚钱没有错,但是人家放心用你的软件存储对自己而言重要的数据,就算过期后也该给个让用户把自己的数据转移走啊,不用搞地那么决绝吧。
怀着这种心情,给作者写了封信。
把所有漏洞统统补上,哼,谁说 mac 上软件少,自由软件和免费软件都能满足所有需要。
上次那个谁做了一个 Windows 下的免费软件替代表,晚点我也做份 mac 上的。
好在 Apple 一向是买硬件送软件的,让我有得以安慰的操作系统可以用,否则只好在 PowerBook 上跑 Linux 了。
但还剩下两个余孽我无法脱离:
Aperture 和 Photoshop ...
为了我的照片,只好继续不安下去。。。
看看能否有天发达了买套正版回来用一辈子。
扯远了,只是想说共享软件 - ecto,我一直拿它写 blog,因为 blog 都由它存储,以前 D 版用很长时间了,为了良心 Renew 成了 Trial,长时间没写 blog 没注意。
今天一打开正常,写完了 blog 提交,让我输入注册码。 -_-#
只好再 Renew 一次,结果重新设置 wordpress 向导,把用 ecto 刚写的 blog 丢了。
只好回到 web 页面上手工重新写一次,郁闷得不行。
只是想说共享软件作者也要凭良心做事,想赚钱没有错,但是人家放心用你的软件存储对自己而言重要的数据,就算过期后也该给个让用户把自己的数据转移走啊,不用搞地那么决绝吧。
怀着这种心情,给作者写了封信。
UTF-8 的 Xoops
Xoops 是一套用于快速架站的 CMS 系统,以大量质量优秀,而且功能完善的模块著称。
除了官方的 CBB 论坛模块,还整合了 Wordpress 作为 blog, MediaWiki 作为 Wiki,台湾甚至有人做了 Xoops 的课程管理模块。
Xoops 刚刚获得了 sf.net 的开源社区第一届大奖赛中在所有的CMS系统中荣获开发类亚军,该组冠军为著名的Gaim项目。
有很多使用 Xoops 的社区在活跃着,包括大陆 Mac 界的麦客一班和勃麦堂使用的都是 Xoops,Linux 界的社区的发行版 - CentOS 主页使用的也是 Xoops。
以 mambo 等其它 CMS 不同的是,Xoops 不是简单的 hook 似仅仅是账号的整合,而是从界面到内部模块之间都进行了整合,除了账户是通用的,模块之间的内容也可以互相调用。
因为工作关系,目前正在做 Xoops 相关的工作,将 Xoops GB2312 整体转换成了 UTF-8,在这里放出:
http://homepage.mac.com/xuqingkuang/FileSharing1.html (五月之前暂时别访问了,这个月竟然超出了 10G 的流量,详见抱怨帖
本版包含了一下模块:
因为 Xoops 对 PHP 和 MySQL 版本要求较高,建议使用 XAMPP 快速服务器包 1.4.10 使用,其它版本皆有各式各样的问题。
http://www.apachefriends.org/en/xampp.html
除了官方的 CBB 论坛模块,还整合了 Wordpress 作为 blog, MediaWiki 作为 Wiki,台湾甚至有人做了 Xoops 的课程管理模块。
Xoops 刚刚获得了 sf.net 的开源社区第一届大奖赛中在所有的CMS系统中荣获开发类亚军,该组冠军为著名的Gaim项目。
有很多使用 Xoops 的社区在活跃着,包括大陆 Mac 界的麦客一班和勃麦堂使用的都是 Xoops,Linux 界的社区的发行版 - CentOS 主页使用的也是 Xoops。
以 mambo 等其它 CMS 不同的是,Xoops 不是简单的 hook 似仅仅是账号的整合,而是从界面到内部模块之间都进行了整合,除了账户是通用的,模块之间的内容也可以互相调用。
因为工作关系,目前正在做 Xoops 相关的工作,将 Xoops GB2312 整体转换成了 UTF-8,在这里放出:
http://homepage.mac.com/xuqingkuang/FileSharing1.html (五月之前暂时别访问了,这个月竟然超出了 10G 的流量,详见抱怨帖
本版包含了一下模块:
- Article 文章管理模块 0.9
- libldap LDAP 模块 0.5
- liens 联系我们 1.0
- mediawiki 维基百科 1.63
- MyAlbum-P 相册 2.86
- Myiframe i框架 1.4
- CBB 论坛(NewBB) 3.0.1
- News 新闻 1.42
- PrivateMessage 私信 0.1
- Profile 账户管理 0.1
- Protector 攻击防护 2.56
- SiteMap 网站地图 0.7
- system Xoop 系统 2.13
- MyTinyd0 用于嵌入 HTML 2.22
- WF-Downloads 下载 2.05
- WhatsNew 最新内容 2.02
- Wordpress 博客 1.63
- XoopsPoll 投票 1.0
因为 Xoops 对 PHP 和 MySQL 版本要求较高,建议使用 XAMPP 快速服务器包 1.4.10 使用,其它版本皆有各式各样的问题。
http://www.apachefriends.org/en/xampp.html
为什么要写 blog
随着身边琐碎日趋变多,记性也变得越来越差,都说好记性不如烂笔头,可笔头对我这种整天到处乱蹿的人而言,拿一本小册子记下自己在干什么实在是一件很困难的事,由于字写得难看,经常自己都看不下去,每次拿起本子都当成练字,一点点字都要写上半天,撕了又撕。
经常有些小想法,有很多想说的话,真握起笔,或者坐在电脑前,就经常忘记要写点什么。
就说昨天还说想聊聊 blog,现在一写起来,思绪就是一片混乱。您就凑合着看吧。
关于 blog 以前也和头头聊过很多,从前的日记都是隐私的,他们无法理解现在为什么都喜欢把自己的隐私公布在网上。
对我而言,记下 blog,算是给自己的约定,明天要说什么,给自己定一个主题,公开开来,请大家监督。如果用一个小册子定下计划,自己给自己看,八成和小时候一样不了了之。
现在的年轻人都很爱秀,某种程度上我也是如此,多是希望能证明自己的能力,而共享自己的东西,也是另一方面。
我喜欢 Share,我以自己的 Share 来希望别人也都能喜欢 Share,知识的共享可以让人获得更多,心情的分享也是如此,Blog 除了分享知识,心情也是可以依靠它分享的。
而作为隐私的日记共享,我觉得这更大程度上是因为社会的变迁。从前人与人之间的友谊还是很单纯而挚真的,都说如今的人都带着面具生活,可不是一个累字可以形容。都说沉默是金,可是沉默也经常是误会之源,很多事情在没有澄清的时候可不就是误会吗。
我性子直,常无意中得罪人,或者一入神就忽视别人的存在。有时当面撤不下脸,或者时过境迁,别人不在意了,我心里还过意不去,就找 blog 写一写,如果有被看到,觉得我还算个实诚的人,也好继续交往,没有看到,我自己心里也能好受一点。
上面的论述阐述了 Blog 还有的一大好处,我嘴拙,经常当面驳不过,blog 可以让我也事后好好驳一驳,比如“为什么要写 blog”。
这一停就是半年,这半年我干了什么?浑浑地过的,为什么?没计划。
收拾收拾笔头,也为下半年想干点什么,定个基调。
.mac 是什么 - www.mac.com 苹果推出的类似 M$ MSN 的服务,优点在和 mac 系统的高度整合,几乎所有的一切都能备份的 .mac 上,只可惜它使用的是 WebDAV,.mac 似乎没有被优化过,国内上传速度往往以 xk 计算,而且我们伟大的 G.F.W. 对于长时间链接似乎不太友好,时常性的 Lost connection。
总之,在次,向各位麦友提示,在国内,不要向又慢又容易掉线的 .mac 投钱,大量更便宜更优质的空间等着你。
说起网页空间不得不提到我现在用的,来自波兰的 www.xcx.pl,它有三种免费套餐,我现在使用的是 100M 主页空间 MySQL PHP + 自己的顶级域名,每月除了限流量 3G 没有其它限制和附加条件,基于 CPanel 的后台管理工具也非常优秀。整体上运行速度非常不错。我的 Storage 依然是 .mac,照片在 flickr,所以这个站点本身流量应该相对很小。
像我一样的穷人可以考虑,经过一番艰苦的 Poland -> English 翻译,把这个空间申请下来。
我喜欢 Wordpress,用起来确实舒服,最重要的是别人总算可以给我直接回复了。
明天说说 CMS,我比较喜欢 Xoops,模块繁多,功能强大。这两天一直在折腾它。
经常有些小想法,有很多想说的话,真握起笔,或者坐在电脑前,就经常忘记要写点什么。
就说昨天还说想聊聊 blog,现在一写起来,思绪就是一片混乱。您就凑合着看吧。
关于 blog 以前也和头头聊过很多,从前的日记都是隐私的,他们无法理解现在为什么都喜欢把自己的隐私公布在网上。
对我而言,记下 blog,算是给自己的约定,明天要说什么,给自己定一个主题,公开开来,请大家监督。如果用一个小册子定下计划,自己给自己看,八成和小时候一样不了了之。
现在的年轻人都很爱秀,某种程度上我也是如此,多是希望能证明自己的能力,而共享自己的东西,也是另一方面。
我喜欢 Share,我以自己的 Share 来希望别人也都能喜欢 Share,知识的共享可以让人获得更多,心情的分享也是如此,Blog 除了分享知识,心情也是可以依靠它分享的。
而作为隐私的日记共享,我觉得这更大程度上是因为社会的变迁。从前人与人之间的友谊还是很单纯而挚真的,都说如今的人都带着面具生活,可不是一个累字可以形容。都说沉默是金,可是沉默也经常是误会之源,很多事情在没有澄清的时候可不就是误会吗。
我性子直,常无意中得罪人,或者一入神就忽视别人的存在。有时当面撤不下脸,或者时过境迁,别人不在意了,我心里还过意不去,就找 blog 写一写,如果有被看到,觉得我还算个实诚的人,也好继续交往,没有看到,我自己心里也能好受一点。
上面的论述阐述了 Blog 还有的一大好处,我嘴拙,经常当面驳不过,blog 可以让我也事后好好驳一驳,比如“为什么要写 blog”。
这一停就是半年,这半年我干了什么?浑浑地过的,为什么?没计划。
收拾收拾笔头,也为下半年想干点什么,定个基调。
.mac 是什么 - www.mac.com 苹果推出的类似 M$ MSN 的服务,优点在和 mac 系统的高度整合,几乎所有的一切都能备份的 .mac 上,只可惜它使用的是 WebDAV,.mac 似乎没有被优化过,国内上传速度往往以 xk 计算,而且我们伟大的 G.F.W. 对于长时间链接似乎不太友好,时常性的 Lost connection。
总之,在次,向各位麦友提示,在国内,不要向又慢又容易掉线的 .mac 投钱,大量更便宜更优质的空间等着你。
说起网页空间不得不提到我现在用的,来自波兰的 www.xcx.pl,它有三种免费套餐,我现在使用的是 100M 主页空间 MySQL PHP + 自己的顶级域名,每月除了限流量 3G 没有其它限制和附加条件,基于 CPanel 的后台管理工具也非常优秀。整体上运行速度非常不错。我的 Storage 依然是 .mac,照片在 flickr,所以这个站点本身流量应该相对很小。
像我一样的穷人可以考虑,经过一番艰苦的 Poland -> English 翻译,把这个空间申请下来。
我喜欢 Wordpress,用起来确实舒服,最重要的是别人总算可以给我直接回复了。
明天说说 CMS,我比较喜欢 Xoops,模块繁多,功能强大。这两天一直在折腾它。
真的要开始了吗? :-)

耽搁了半年有余真的要重新开始吗?
就好像 Matrix Reload :-p
那是当然。
不过现在已经午夜两点了,好不容易找到好的主机,把 wordpress 搭了起来,总算不用写信回复我了。 :-)
有很多想说的明天再说吧,少不了我唠叨 .mac 的缺点。
上次的红帘还喜欢吗?这次我画不出开场的了,只好从Flickr 上借 amber_b MM 一个了。
{kind=link}
不得不承认比我画的好很多。
顺道提下搜索到的另一个画得很好的窗帘油画,来源于Sally Born。
时间太晚睡觉去。
有一个礼拜没有更新了。
主要因为改变了 rapidweaver 的导出方式,我把 idisk 设置为离线可用,于是只好花一个礼拜来把所有数据重新导出到 idisk 上。
本周的主要内容是 Ajax,周一,在周会上向同事们介绍了 Ajax 的概念。
Ajax 是 Asynchronous JavaScript and XML 主要用于在一个页面中,利用 JavaScript 实现页面的动态效果(包括数据的替换),用 XMLHTTPRequest 实现和服务器进行数据的交换。
Ajax 应用非常广泛,下面是使用了 Ajax 的一些网站:
mail.google.com
www.flickr.com
www.zimbra.com
www.writely.com
等等,详细请看我的讲义。
主要因为改变了 rapidweaver 的导出方式,我把 idisk 设置为离线可用,于是只好花一个礼拜来把所有数据重新导出到 idisk 上。
本周的主要内容是 Ajax,周一,在周会上向同事们介绍了 Ajax 的概念。
Ajax 是 Asynchronous JavaScript and XML 主要用于在一个页面中,利用 JavaScript 实现页面的动态效果(包括数据的替换),用 XMLHTTPRequest 实现和服务器进行数据的交换。
Ajax 应用非常广泛,下面是使用了 Ajax 的一些网站:
mail.google.com
www.flickr.com
www.zimbra.com
www.writely.com
等等,详细请看我的讲义。
本周的主要内容是 Ajax,周一,在周会上向同事们介绍了 Ajax 的概念。
Ajax 是 Asynchronous JavaScript and XML 主要用于在一个页面中,利用 JavaScript 实现页面的动态效果(包括数据的替换),用 XMLHTTPRequest 实现和服务器进行数据的交换。
Ajax 应用非常广泛,下面是使用了 Ajax 的一些网站:
mail.google.com
www.flickr.com
www.zimbra.com
www.writely.com
等等,详细请看我的讲义。
主要因为改变了 rapidweaver 的导出方式,我把 idisk 设置为离线可用,于是只好花一个礼拜来把所有数据重新导出到 idisk 上。
本周的主要内容是 Ajax,周一,在周会上向同事们介绍了 Ajax 的概念。
Ajax 是 Asynchronous JavaScript and XML 主要用于在一个页面中,利用 JavaScript 实现页面的动态效果(包括数据的替换),用 XMLHTTPRequest 实现和服务器进行数据的交换。
Ajax 应用非常广泛,下面是使用了 Ajax 的一些网站:
mail.google.com
www.flickr.com
www.zimbra.com
www.writely.com
等等,详细请看我的讲义。
我的网站发布,苹果Pro系列更新
不得不承认 iPodrock 效率确实不错。
昨天下午三点汇的款,四点半就给我发好了货,今天中午就收到了。
我非常非常高兴地在我的小黒屋宣布:小黒屋开放了!这里仅仅是我个人的秀场,不想搞成任何组织,
这里仅用于发表一点自己的感想和心得,当然也会把一些自己喜欢的东西共享出来。欢迎对我的想法提出质疑,因为 .mac 主页服务不提供动态网页和数据库功能,
有什么问题还请直接给我发 Email:xuqingkuang@gmail.com
我会努力一一作答的,将他们记录在日志里。
如果这个网站让大家感兴趣的话,就做一个 Podcast 来分享它!
今天,苹果也更新了自己的 Pro 系列产品。
包括新的双核双U 的 PowerMac G5,带有高清屏的 PowerBook 15"/17"。
最引人注目的还是新的,为专业摄影师设计的照片处理软件:Aperture
详情还需参考 Apple Aperture 官方网站:http://www.apple.com/aperture/
昨天下午三点汇的款,四点半就给我发好了货,今天中午就收到了。
我非常非常高兴地在我的小黒屋宣布:小黒屋开放了!这里仅仅是我个人的秀场,不想搞成任何组织,
这里仅用于发表一点自己的感想和心得,当然也会把一些自己喜欢的东西共享出来。欢迎对我的想法提出质疑,因为 .mac 主页服务不提供动态网页和数据库功能,
有什么问题还请直接给我发 Email:xuqingkuang@gmail.com
我会努力一一作答的,将他们记录在日志里。
如果这个网站让大家感兴趣的话,就做一个 Podcast 来分享它!
今天,苹果也更新了自己的 Pro 系列产品。
包括新的双核双U 的 PowerMac G5,带有高清屏的 PowerBook 15"/17"。
最引人注目的还是新的,为专业摄影师设计的照片处理软件:Aperture
详情还需参考 Apple Aperture 官方网站:http://www.apple.com/aperture/
LVS 会议记录。
LVS 会议记录。
总体上来说整场会议仅仅是概括,没有什么深入的东西。
8:00 Mike 的开场
8:10 冯岩就 Mac 与 Linux 发表演讲
8:17 章文嵩正式开始演讲 - Building Scalable Network Services using Linux Virtual Server
网络服务之需求:
扩展性
24x7
管理性
省钱
LVS 项目之目标:
为网络高可用性提供一个基本框架。
LVS总体框架
E-Comerce
General Network Services
Cluster Management
KTCPVS
IPVS
LVS Framework
IP Virtual Server:
Linux 内核级实现
三种负载分担手段:
NAT
IP Tunneling
Direct Routing
Comparison:
VS/NAT VS/TUN VS/DR
Server any Tunneling Non-arp device
Server net private LAN/WAN LAN
Server no. low(10~20) HIgh((100) High(100)
Server gw load balancer Own router Own router
KTCPVS:
Layer-7 switching in user-space
- high overhead of context switching and copying
- limited scalability
Cluster Monitoring Software
Red Hat Cluster Server / Piranha
- LVS Piranha
UltraMonkey
- LVS lvs-gui heartbeat ldirectored
Keepalived
Netparse
etc
高可用性
服务器完蛋检测:
- ping, server detection, etc
Load Balancer 完蛋检测:
- 数据同步/迁移
- Heartbeat
总体上来说整场会议仅仅是概括,没有什么深入的东西。
8:00 Mike 的开场
8:10 冯岩就 Mac 与 Linux 发表演讲
8:17 章文嵩正式开始演讲 - Building Scalable Network Services using Linux Virtual Server
网络服务之需求:
扩展性
24x7
管理性
省钱
LVS 项目之目标:
为网络高可用性提供一个基本框架。
LVS总体框架
E-Comerce
General Network Services
Cluster Management
KTCPVS
IPVS
LVS Framework
IP Virtual Server:
Linux 内核级实现
三种负载分担手段:
NAT
IP Tunneling
Direct Routing
Comparison:
VS/NAT VS/TUN VS/DR
Server any Tunneling Non-arp device
Server net private LAN/WAN LAN
Server no. low(10~20) HIgh((100) High(100)
Server gw load balancer Own router Own router
KTCPVS:
Layer-7 switching in user-space
- high overhead of context switching and copying
- limited scalability
Cluster Monitoring Software
Red Hat Cluster Server / Piranha
- LVS Piranha
UltraMonkey
- LVS lvs-gui heartbeat ldirectored
Keepalived
Netparse
etc
高可用性
服务器完蛋检测:
- ping, server detection, etc
Load Balancer 完蛋检测:
- 数据同步/迁移
- Heartbeat
PowerBook 17" 的 nbench 和 linpack 测试结果。
我的机器配制是:
Machine Name: PowerBook G4 17"
Machine Model: PowerBook5,7
CPU Type: PowerPC G4 (1.2)
Number Of CPUs: 1
CPU Speed: 1.67 GHz
L2 Cache (per CPU): 512 KB
Memory: 1GB
Bus Speed: 167 MHz
linpack 测试结果:
我的机器是:448679 Kflops
邹鹏程的测试纪录:
我的ASUS V6800V (PentiumM 2.0G) 的linpack结果为:340Mflops
我的desktop (Celeron 1.7G) 的结果为:200Mflops
builder (4 Xeon 3.4G) 的结果为:680Mflops
目前世界第一的Blue Genes的结果为:70720Gflops (Rmax)
曙光4000A的结果为:8061Gflops (Rmax)
nbench 测试结果:
我的机器是:
MEMORY INDEX : 12.511
INTEGER INDEX : 10.897
FLOATING-POINT INDEX: 12.605
邹鹏程的测试结果可以参考:这里
Machine Name: PowerBook G4 17"
Machine Model: PowerBook5,7
CPU Type: PowerPC G4 (1.2)
Number Of CPUs: 1
CPU Speed: 1.67 GHz
L2 Cache (per CPU): 512 KB
Memory: 1GB
Bus Speed: 167 MHz
linpack 测试结果:
我的机器是:448679 Kflops
邹鹏程的测试纪录:
我的ASUS V6800V (PentiumM 2.0G) 的linpack结果为:340Mflops
我的desktop (Celeron 1.7G) 的结果为:200Mflops
builder (4 Xeon 3.4G) 的结果为:680Mflops
目前世界第一的Blue Genes的结果为:70720Gflops (Rmax)
曙光4000A的结果为:8061Gflops (Rmax)
nbench 测试结果:
我的机器是:
MEMORY INDEX : 12.511
INTEGER INDEX : 10.897
FLOATING-POINT INDEX: 12.605
邹鹏程的测试结果可以参考:这里
三件事情
把邹鹏程的三个想法都记下来,都是不错的想法。
顺道记录一下我的工作进度。
顺道记录一下我的工作进度。
- 为未来的管理工具添加一个类似 Zimbra 的 Web 界面
Zimbra 拥有一个出色的界面,用户可以通过拖放操作为 Email 添加 tag,对 Email 进行分类。
今天用了半天时间将 Zimbra 安装到了 Asianux 2 上。
界面的编写无疑要花费大量时间,更何况是 JavaScript。但我已经准备好迎接这个挑战。 - 将 HA 和 Xen 进行整合
Xen 拥有在一个硬件平台上运行多个操作系统的能力,将 Xen 和 HA 进行整合无疑对节约成本有很大帮助
我在 Xen 的使用过程中,虚拟机始终停止在 Blocked 状态下,由于虚拟机运行于另一个环境下,包括 dmesg 在内的输出我无法获取。 - 建立 Red Flag 开放社区
OpenSuSE 和 Fedora 都有自己的社区,但它们仅仅是将自己的开发流程(仅仅是 Bugzilla 和 cvs)开放出来,而人在其中的位置微乎其微。
邹希望建立一个真正的社区,人们都可以在期间自由交流,发表意见,每个人都有为 Asianux 打包的能力,别人也有为这个包评分的能力。
希望通过这样来提高 Asianux 的品质。而这样无疑,比起 OpenSuSE 和 Fedora 基于产品理念的社区,这种以人为本的社区更胜一酬。
相关网址:豆瓣
火车上
现在是早晨 8 点,下午肯定会再写一篇 10/6 后续的。。。
卧铺车的8号车厢里只有我和小姑(老爸在五号车厢,虽然我很不忍心)。
和花花发短信:
我:花仔,快来取小白。
花花:小白~小白~小白~
我:快点回北京…
花花:昨晚作梦梦见小白已经修好了
我:靠…-_-#
花花:哈哈 大飞机~
花花:我在回北京的路上
我:我下午三点半到北京。
花花:我晚上九点二十 你现在是不是同时拿着小白和大飞呀?
我:是啊,左手飞机,右手小白,一个打游戏,一个看电影。
花花:你居然没被压死?嘿嘿
我:托你的福,没被BB压死,反而套来车上众MM佻逗的眼神。享受中…
花花:切 你那是自作多情 嘿嘿
我:忌妒吧,不是罪,嘿嘿。
花花:你小心人家色诱你就惨了
我:嘿嘿…
。。。。
卧铺车的8号车厢里只有我和小姑(老爸在五号车厢,虽然我很不忍心)。
和花花发短信:
我:花仔,快来取小白。
花花:小白~小白~小白~
我:快点回北京…
花花:昨晚作梦梦见小白已经修好了
我:靠…-_-#
花花:哈哈 大飞机~
花花:我在回北京的路上
我:我下午三点半到北京。
花花:我晚上九点二十 你现在是不是同时拿着小白和大飞呀?
我:是啊,左手飞机,右手小白,一个打游戏,一个看电影。
花花:你居然没被压死?嘿嘿
我:托你的福,没被BB压死,反而套来车上众MM佻逗的眼神。享受中…
花花:切 你那是自作多情 嘿嘿
我:忌妒吧,不是罪,嘿嘿。
花花:你小心人家色诱你就惨了
我:嘿嘿…
。。。。
给爷爷奶奶拍照
费了千辛万苦,总算把势不两立的爷爷和奶奶撮合到一起,留下了经典的一刻。

爷爷和奶奶
只是辛苦了小姑和小妹提着毛毯做背景啊。 :-D
爷爷和奶奶
只是辛苦了小姑和小妹提着毛毯做背景啊。 :-D
趁着黑夜里没人把网站赶出来了
今天主要是干了以下几件事情:
- 买好了明天回北京的卧铺票,T108 特快,总算摆脱硬座的痛苦
- 买好了给海媛姐的零食,有永新特产的陈皮、李子干和杨梅,满足一下那个小谗猫去见了于斌那个家伙,那小伙子居然开店了,去他店里还看见一个皮肤白皙身材不错的小 MM,口水哗啦啦啊。。。-_-#
- 给老爸拍了不少照片,有不少喜欢的,可是老爸总爱摆酷,不喜欢生活照,反正是我自己留纪念,不管他。明天给爷爷奶奶拍去
首次使用 blogger
将 blogchina 上的文章都迁移过来。。。好大的工程啊。。。。
查找 Mac 上能够离线编写 blog 的工具,这才是使用 blogger.com 的真正目的。 ;-)
查找 Mac 上能够离线编写 blog 的工具,这才是使用 blogger.com 的真正目的。 ;-)