[chromium]
name=Chromium build for Fedora $releasever - $basearch
baseurl=http://spot.fedorapeople.org/chromium/F$releasever/
enabled=1
gpgcheck=0
在 Django 的 View 中调用 syncdb
完全吃不消 SAE 的 MySQL 各种限制了,无数次地清空数据库 -> 重新初始化 -> 导入 SQL 文件。
为什么不能在 Django 中建立好 Model 后,直接从 Django 的 View 里 syncdb 呢。
from django.http import HttpResponse
def syncdb(request):
from django.core.management import call_command
from cStringIO import StringIO
import sys
old_stdout = sys.stdout
sys.stdout = mystdout = StringIO()
mystdout.write('<pre>')
call_command('syncdb')
mystdout.write('</pre>')
sys.stdout = old_stdout
mystdout.seek(0)
return HttpResponse(mystdout.read())
什么时候再把 South 整合进去就完美啦~~~ ;-)
Long polling
这两天在公司的项目里用了 Long polling,了解了它的实现原理,其实不像它的名字那么玄乎,只是 Ajax 和 HTTP 的类似小妙招的办法。
先解释一下 Long polling 是什么:
首先得说到传统的 Polling,Polling 是 Ajax 隔一段时间去抓取服务器上的数据,检查数据是否更新,但这样有很大问题,首先是每次请求会实用一个 HTTP request,对应的服务器就得建一个新的线程来处理这个 HTTP request,消耗网络流量、服务器资源不说,绝大多数情况下,数据短时间内是不会更新的,也就是说绝大多数的 Ajax 请求都只能无功而返。
而 Long polling 就是用来解决这个问题的。
它的核心是:
1. 做一个超时非常长的 Ajax 请求,并且在错误捕获代码里不断执行自己。2. CGI 部分接收到请求后在限定的时间内(Ajax 超时时间内)每隔一段时间(例如一秒)对数据库进行查询,可以使用 sleep 类似的方法。
3. 如果有新的数据则返回,如果即将到 Ajax 超时的时间则返回一个错误值,比如 404,这样那个非常长的 Ajax 请求会再发一个过来,继续查询。
这个办法的最大价值是有效减少了 HTTP 请求数,对服务器而言就不用开启新的线程去处理它,旧的线程如果不是因为超时,则只会在数据已经更新的情况下返回数据。可以节约大量资源,而且实时性更高。
目前,人人网的消息提示、Web 版阿里旺旺、新浪微博的新微博提示应该都是使用这种方法做的。
但这个办法对开发有
所以最好做好两套配置,一套用于产品环境的多线程环境,
我依然对那位在现有架构下想出这种办法的人表示钦佩。
这儿有范例代码,简单又实用:http://stackoverflow.com/questions/333664/simple-long-polling-example-code
QPID 消息队列初步
QPID 是一种高性能 Message Bus,目前因为牵扯到工具的 SOA 架构,我的项目中将会整合它,以将自身对数据库的修改提交到 Message Bus 中, 供其它程序监听调用。
目前主流的 Message Bus 主要有以下几种:
而之所以选择 QPID 是因为它有以下几个优点(引用源):
- Supports transactions
- Persistence using a pluggable layer — I believe the default is Apache Derby
- This like the other Java based product is HIGHLY configurable
- Management using JMX and an Eclipse Management Console application - http://www.lahiru.org/2008/08/what-qpid-management-console-can-do.html
- The management console is very feature rich
- Supports message Priorities
-
Automatic client failover using configurable connection properties -
- http://qpid.apache.org/cluster-design-note.html
- http://qpid.apache.org/starting-a-cluster.html
- http://qpid.apache.org/cluster-failover-modes.html
- Cluster is nothing but a set of machines have all the queues replicated
- All queue data and metadata is replicated across all nodes that make up a cluster
- All clients need to know in advance which nodes make up the cluster
- Retry logic lies in the client code
- Durable Queues/Subscriptions
- Has bindings in many languages
- For the curious: http://qpid.apache.org/current-architecture.html
而对我而言,QPID 比较有优势的地方是,一有 Python 的 bindding(Perl 的兄弟对不起了),二是源代码比较充足。
为此我写了两个基类,简单地调用了 QPID Python 中的 Receiver 和 Sender,相对于 message_transfer 方法,这种方法可以传递 Dictionary 对象,一共三个文件,其实也可以合在一起使用。
#!/usr/bin/python
import qpid
import qpid.messaging
import logging
logging.basicConfig()
class QPIDBase(object):
def __init__(self, host='10.66.93.193', port='5672', queue_name='tmp.testing', username='guest', password='guest'):
"""
Arguments:
host
port
queue_name
username
password
"""
self.host = host
self.port = port
self.queue_name = queue_name
self.username = username
self.password = password
self.connection = None
self.session = None
def init_connect(self, mechanism='PLAIN'):
"""Initial the connection"""
url = 'amqp://guest/guest@%s:%s' %(self.host, self.port)
self.connection = qpid.messaging.Connection(
url = url, sasl_mechanisms=mechanism,
reconnect=True, reconnect_interval=60, reconnect_limit=60,
username=self.username, password=self.password
)
self.connection.open()
def init_session(self):
"""Initial the session"""
if not self.connection:
self.init_connect()
self.session = self.connection.session()
def close(self):
"""Close the connection and session"""
self.session.close()
self.connection.close()
#!/usr/bin/python
import qpid.messaging
from datetime import datetime
from base import QPIDBase
class QPIDSender(QPIDBase):
def __init__(self, **kwargs):
super(QPIDSender, self).__init__(**kwargs)
self.sender = None
def init_sender(self):
"""Initial the sender"""
if not self.session:
self.init_session()
self.sender = self.session.sender(self.queue_name)
def send(self, content, t = 'test'):
"""Sending the content"""
if not self.sender:
self.init_sender()
props = {'type': t}
message = qpid.messaging.Message(properties=props, content = content)
self.sender.send(message)
def typing(self):
"""Sending the contents real time with typing"""
content = ''
while content != 'EOF':
content = raw_input('Start typing:')
self.send(content)
if __name__ == '__main__':
s = QPIDSender()
s.send('Testing at %s' % datetime.now())
s.close()
#!/usr/bin/python
from pprint import pprint
from base import QPIDBase
class QPIDReceiver(QPIDBase):
def __init__(self, **kwargs):
super(QPIDReceiver, self).__init__(**kwargs)
self.receiver = None
def init_receiver(self):
"""Initial the receiver"""
if not self.session:
self.init_session()
self.receiver = self.session.receiver(self.queue_name)
def receive(self):
"""Listing the messages from server"""
if not self.receiver:
self.init_receiver()
try:
while True:
message = self.receiver.fetch()
content = message.content
pprint({'props': message.properties})
pprint(content)
self.session.acknowledge(message)
except KeyboardInterrupt:
pass
self.close()
# Test code
if __name__ == '__main__':
r = QPIDReceiver()
r.receive()
代码非常简单,容易读懂,使用方法是在一台 Linux Server 上安装好 qpid-cpp-server, 并且启动后,在 Client 上安装 python-qpid,然后修改一下 base.py __init__ 方法的 host 字段,或者在代码中自行指定好服务器地址,即可直接执行测试。
需要说明的是 QPID 返回的数据结构,包含可以为 Dictionary 对象的 properties 和只能为纯文本的 content 两个属性,也就是说可以将数据结构保存到 properties,而消息名称保存成 content 中,即:
try:
while True:
message = self.receiver.fetch()
content = message.content
pprint({'props': message.properties})
pprint(content)
self.session.acknowledge(message)
except KeyboardInterrupt:
pass
一个终端执行 receiver.py 监听消息,再开一个终端执行 sender.py,将会如以下输出:
$ python ./receiver.py
{'props': {u'type': u'test', 'x-amqp-0-10.routing-key': u'tmp.testing'}}
'Testing at 2010-12-06 14:54:59.536093'
如果有兴趣试下 QPIDSender.typing() 方法,再把 Kerberos 的用户名读出来,就可以做一个 IM 啦~
问题:现在似乎 Sender 发出的消息一次只能有一个 Receiver 接收,也就是现有代码不能用于 SOA,而这理论上应该是不应该的,依然在探索。
(可以尝试打开两个 receiver.py 测试)
Django 应用程序调试
这里要介绍的是,全面的 Django app 调试,从最简单的打印变量,到使用 Django 自带的 Debug Middleware 调试 SQL,最后到全面的 Django debug toolbar 的使用。
2. Django debug context processor[1](中级)
3. Django debug toolbar[2](更简单而强大。。。 -_-#)
这是最简单的办法,在启动了 django-admin runserver 后,可将变量打印到终端上,适用于临时性的排错,当然还有其它办法,只是我觉得这种办法最简单。
下面是简单范例。
from pprint import pprint from django.http import HttpResponse from myapp.core.models import Case def index(request, template = 'index.html'): c = Case.objects.select_related('author').get(pk = 100) pprint(str(c.query)) # 打印 C.objects.get(pk = 100) 调用的 SQL pprint(dict(c)) # 打印 C.objects.get(pk = 100) 的世纪内容。 return HttpResponse(c.__dict__)
二、Django debug context processor[1]
该 Middleware 主要用于调试 SQL 执行情况,能够将所有的数据库查询 SQL 及花费时间打印出来,但是它要求代码使用 RequestContext,普通的 Context 和 render_to_response() 便无法直接使用了,如果之前代码使用 Context 构建,可能需要重写这部分代码。
其实我推荐在开始编写代码的时候,就使用 django.views.generic.simple.direct_to_template 来渲染页面,像如下:
from django.views.generic.simple import direct_to_template def index(request, template = 'index.html'): ... return direct_to_template(request, template, { 'parameters': parameters, 'case': c, })
下面说安装和使用方法:
在 settings.py 的 'TEMPLATE_CONTEXT_PROCESSORS' 段中加入 'django.core.context_processors.debug',如下:
# RequestContext settings
TEMPLATE_CONTEXT_PROCESSORS = (
'django.core.context_processors.auth',
'django.core.context_processors.request',
'django.core.context_processors.media',
'django.core.context_processors.debug',
'myapp.core.context_processors.processor',
...
)
在 settings.py 中加入 'INTERNAL_IPS',用于识别开发机地址,内容写入本机 IP 地址即可:
# Needed by django.core.context_processors.debug:
# See http://docs.djangoproject.com/en/dev/ref/templates/api/#django-core-context-processors-debug
INTERNAL_IPS = ('127.0.0.1', )
然后,在共享模板的开头(别告诉我你一个页面一个模板文件。。。),加入生成 SQL 列表的代码:
<body id="body">
{% if debug %}
<div id="debug">
<p>
{{ sql_queries|length }} Quer{{ sql_queries|pluralize:"y,ies" }}
{% ifnotequal sql_queries|length 0 %}
(<span style="cursor: pointer;" onclick="var s=document.getElementById('debugQueryTable').style;s.display=s.display=='none'?'':'none';this.innerHTML=this.innerHTML=='Show'?'Hide':'Show';">Show</span>)
{% endifnotequal %}
</p>
<table id="debugQueryTable" style="display: none;">
<tr class="odd">
<td>#</td>
<td>SQL</td>
<td>Time</td>
</tr>
{% for query in sql_queries %}
<tr class="{% cycle odd,even %}">
<td>{{ forloop.counter }}</td>
<td>{{ query.sql|escape }}</td>
<td>{{ query.time }}</td>
</tr>{% endfor %}
</table>
</div>
{% endif %}
...
</body>
最终生成的效果是在页面顶部,增加了一个 XX Quueries 项,点击 (Show) 后如下:

Django debug toolbar 是我到目前为止见过的安装最简单,功能最强大的调试工具,它的主要特性有:
* 更加完善的 SQL 调试(比 Django debug processor 更加精准,Django debug contect processor 无法处理关系查询(Select related))
* 记录 CPU 使用时间(可惜没有针对代码级的 profile,希望未来的版本能增加这个功能)
* 完整记录 HTTP Headers 和 Request 请求
* 完整记录模板 Context 内容,包括 RequestContext 和直接传入的变量
* 记录 Signals
* python logging 模块的日志支持
安装也比较简单,可以使用 yum 直接安装,也从上面的地址下载后,直接使用 setuptools 通用的安装方法安装即可。
$ tar zxvf robhudson-django-debug-toolbar-7ba80e0.tar.gz $ cd robhudson-django-debug-toolbar-7ba80e0 $ python ./setup.py build $ sudo python ./setup.py install
如需确保安装正常,从 Python shell 里看看能否 import 即可,不出错,即安装正常:
$ python Python 2.6.1 (r261:67515, Feb 11 2010, 00:51:29) [GCC 4.2.1 (Apple Inc. build 5646)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import debug_toolbar >>>
然后是配置你的 settings.py。
我的调试 settings.py 和在产品服务器上运行的是不一样的,我也建议最好将二者分开,因为 Django app 开启 Debug 后对性能损耗非常严重。
将下面红字加入你自己的 settings.py 文件:
MIDDLEWARE_CLASSES = (
...
'debug_toolbar.middleware.DebugToolbarMiddleware',
)
INSTALLED_APPS = (
...
'debug_toolbar'
)
TEMPLATE_DIRS = (
...
'/Library/Python/2.6/site-packages/django_debug_toolbar-0.8.3-py2.6.egg/debug_toolbar/templates/', #按需修改!指向 debug_toolbar 的模板目录。
)
DEBUG_TOOLBAR_PANELS = (
'debug_toolbar.panels.version.VersionDebugPanel',
'debug_toolbar.panels.timer.TimerDebugPanel',
'debug_toolbar.panels.settings_vars.SettingsVarsDebugPanel',
'debug_toolbar.panels.headers.HeaderDebugPanel',
'debug_toolbar.panels.request_vars.RequestVarsDebugPanel',
'debug_toolbar.panels.template.TemplateDebugPanel',
'debug_toolbar.panels.sql.SQLDebugPanel',
'debug_toolbar.panels.signals.SignalDebugPanel',
'debug_toolbar.panels.logger.LoggingPanel'
)
然后使用 django-admin.py runserver 启动测试服务器,下图是 Django debug toolbar 的 SQL 查询页面。
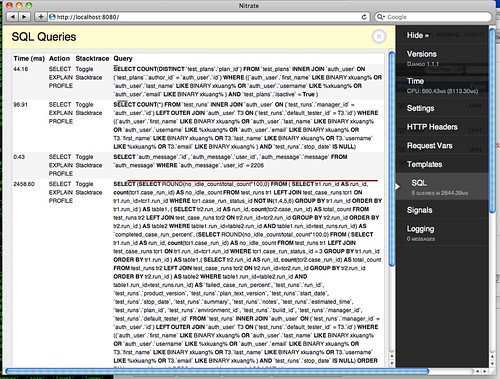
相关链接:
[1] http://www.djangosnippets.org/snippets/93/
[2] http://github.com/robhudson/django-debug-toolbar/downloads
Django 下的 Kerberos 登录
Kerberos 这种统一用户名和密码进行登录的方式在各大公司(尤其外企)内部应该都得到广泛应用,它以其安全、高效和易于管理等特性得到了很多系统管理员的喜爱。
目前网上对于 Kerberos 登录原理的描述都过于复杂,其实它的实现非常简单,当你向一个部署了 Kerberos 的应用服务器发起登录请求的时候,服务器会去 /etc/krb5.conf 里描述的 KDC 服务器用 Kerberos 协议发起一个登录请求,如果用户名密码验证通过,将会向服务器发一个票(Ticket),否则将会引出一个错误。然后服务器可以将票发给客户端,以后客户端就可以用这张票进行其它操作。与火车票和电影票一样,Kerberos 的票,也是有使用时间限制的,如果不经过特殊设置,这张票的超时时间大约是 6 个小时。
而在 Django 里使用 Kerberos 登录,有两种办法,一种是由 Django 直接向 KDC 验证密码,另一种是在 Apache 上使用 mod_auth_kerb 模块,由浏览器来处理登录请求。
这两种办法其实都是对 Django Auth Backend 的重载,所有的 Auth Backend 都位于 django/contrib/auth/backends.py 里,这里[2]也有一个使用 Email 来进行验证的范例,我受此启发,写了这两个例子,希望也能抛砖引玉,能给你们更多启发。
第一种 - 由 Django 直接向 KDC 验证密码:
这种办法比较简单,需要在 web server 上装好 python-kerberos 包,并且配置好 /etc/krb5.conf,详细的配置方法,最好咨询 IT 部门,配置成功后在服务器上用 Kerberos 上有的普通用户运行 kinit,如果能够密码验证通过就行。
并且在 Django 的 settings.py 里写入类似下面这行,定义 Kerberos 的 Realm:
# Kerberos settings KRB5_REALM = 'EXAMPLE.COM'
与上面的 Email 验证例子类似的是,我们需要对 authenticate 方法进行重载,加入 kerberos 认证代码,python-kerberos 已经提供了 checkPassword 方法。
try:
auth = kerberos.checkPassword(
username, password, '',
settings.KRB5_REALM
)
except kerberos.BasicAuthError, e:
return None
完整代码如下:
import kerberos
from django.conf import settings
from django.contrib.auth.backends import ModelBackend
from django.contrib.auth.models import User
class KerberosBackend(ModelBackend):
"""
Kerberos authorization backend for TCMS.
Required python-kerberos backend, correct /etc/krb5.conf file,
And correct KRB5_REALM settings in settings.py.
Example in settings.py:
# Kerberos settings
KRB5_REALM = 'EXAMPLE.COM'
"""
def authenticate(self, username=None, password=None):
try:
auth = kerberos.checkPassword(
username, password, '',
settings.KRB5_REALM
)
except kerberos.BasicAuthError, e:
return None
try:
user = User.objects.get(username=username)
except User.DoesNotExist:
user = User.objects.create_user(
username = username,
email = '%s@%s' % (username, settings.KRB5_REALM.lower())
)
user.set_unusable_password()
user.save()
return user
第二种:Apache 上使用 mod_auth_kerb:
这种方法略有复杂,部署它需要向 KDC 申请一个 keytab 文件,以授权该 Web Server 向 KDC 发起请求,并且需要安装和配置 mod_auth_kerb(很简单,后面有),并且 /etc/krb5.conf 一点也不能少。
但是好处也是非常明显的,上面那种依然是使用 Django Auth Contrib 的 Session Manager 来负责登录信息的维持,但是这种方法将能够完全使用 Kerberos 自身提供的 Features,包括登录维持,和 kinit 的支持,也就是说,只要在本机上使用 kinit 成功登录过一次,用 Firefox (目前似乎在 Linux 上只支持该浏览器)访问部署了 mod_auth_kerb 的网站,将都不再需要登录。
它的原理包括两种条件,一种是没有在本机执行 kinit 的,使用 Firefox 直接访问服务器,服务器将会返回一个 401 Authorization Required 错误,这时 Firefox 会弹出对话框询问你的 Kerberos 用户名和密码,并提交你的密码。另一种在本机已经执行过 kinit 的,Firefox 会去读取你客户端的 Kerberos ticket 缓存,如果没有过期的话,就会使用它。无论哪种办法,Firefox 都将在 HTTP Header 里添加一个 'Authorization' 段,并且加入 Basic Authorization 验证方式,例如我本机上的:
Authorization Basic eGt1YW5nOkxvdmVvZnJvYWQuMTIz
使用这种部署方式,在 Django 1.1 版本以下,还没有比较好的解决办法,但好在 Django 1.1 提供了 RemoteUserBackend 后端,依然在 django/contrib/auth/backends.py 路径里,通过阅读它的代码,我们可以看到它其实依然是个 ModelBackend 的继承,而 Django 的 Request Handler 已经默认将 HTTP Meta 里的 REMOTE_USER 段给加入处理范围之内了,因此 RemoteUserBackend 的 ’authenticate‘ 与 ModelBackend 不太一样。 :-)
其实代码都已经写好,我们只需要处理一下拿到用户后的处理办法('configure_user' 方法)和处理用户名的方法('clean_username' 方法)就可以了。
我这里在拿到用户后,出于保护密码的原则,为该用户设置了一个无效密码('user.set_unusable_password()' 方法),并且设置了该用户的 Email。 同时,因为 RemoteUserBackend 默认返回的用户名是 ‘[username]@[KRB5_REALM]',所以我也把后面的 REALM 给去掉,直接贴代码:
from django.conf import settings
from django.contrib.auth.backends import RemoteUserBackend
class ModAuthKerbBackend(RemoteUserBackend):
"""
mod_auth_kerb modules authorization backend for TCMS.
Based on DjangoRemoteUser backend.
Required correct /etc/krb5.conf, /etc/krb5.keytab and
Correct mod_auth_krb5 module settings for apache.
Example apache settings:
# Set a httpd config to protect krb5login page with kerberos.
# You need to have mod_auth_kerb installed to use kerberos auth.
# Httpd config /etc/httpd/conf.d/<project>.conf should look like this:
<Location "/">
SetHandler python-program
PythonHandler django.core.handlers.modpython
SetEnv DJANGO_SETTINGS_MODULE <project>.settings
PythonDebug On
</Location>
<Location "/auth/krb5login">
AuthType Kerberos
AuthName "<project> Kerberos Authentication"
KrbMethodNegotiate on
KrbMethodK5Passwd off
KrbServiceName HTTP
KrbAuthRealms EXAMPLE.COM
Krb5Keytab /etc/httpd/conf/http.<hostname>.keytab
KrbSaveCredentials off
Require valid-user
</Location>
"""
def configure_user(self, user):
"""
Configures a user after creation and returns the updated user.
By default, returns the user unmodified.
Here, the user will changed to a unusable password
and set the email.
"""
user.email = user.username + '@' + settings.KRB5_REALM.lower()
user.set_unusable_password()
user.save()
return user
def clean_username(self, username):
"""
Performs any cleaning on the "username" prior to using it to get or
create the user object. Returns the cleaned username.
For more info, reference clean_username function in
django/auth/backends.py
"""
return username.replace('@' + settings.KRB5_REALM, '')
Django 是一个很强大的框架,虽然缺点和优点都同样的明显,有些甚至是由于 Python 语言或者类库造成的问题,但是因为其使用的便利性,高效的开发,而且其开发小组也非常活跃,使其特性的添加非常频繁,而且网上也有大量资源,例如 Django Snippets 网站,因此依然有着非常巨大优势。而通过阅读它的代码,往往都能获得更多启发。
链接:
写了个监视酷讯火车票的 Python 程序
受不了了,买火车票买不到,只好盯上黄牛票了,可是没法不停地刷页面啊,刚刚就错过了一个发布了 20 分钟的黄牛票,打电话回去时已经打不通了。。。-_-#
就写了个程序来解决这个问题,粘了一堆代码(参考太多,头一次写这种东西,原作者勿怪),总算成了,可能有 bug,欢迎提交 patch 或者更好的解决办法。
可以通过修改下面的参数来修改程序执行:
url = "http://piao.kuxun.cn/beijing-jinggangshan/" # 把火车票的搜索地址粘在这里,这里假设是北京到井冈山的 key = "2张" # 搜索关键字,我得俩人啊。。。 sequence = 60#60 * 5 # 搜索间隔,给服务器压力别太大,每分钟一次就行了。
#!/usr/bin/python
# encoding: utf-8
import urllib2
import mailbox
import time
import os
import re
from sgmllib import SGMLParser
class URLListName(SGMLParser):
is_a=""
name=[]
def start_a(self, attrs):
self.is_a=1
def end_a(self):
self.is_a=""
def handle_data(self, text):
if self.is_a:
self.name.append(text)
url = "http://piao.kuxun.cn/beijing-jinggangshan/"
key = "2张"
sequence = 60#60 * 5
request = urllib2.Request(url)
request.add_header('User-Agent', 'Mozilla/5.0')
opener = urllib2.build_opener()
data = opener.open(request).read()
ticket_name = URLListName()
ticket_name.feed(data)
cache=[]
while 1:
try:
print "beign retrive"
data = opener.open(request).read()
ticket_name.feed(data)
print "beign scan"
for result in ticket_name.name:
if result and result.find(key) >= 0:
if result in cache:
pass
else:
print "found:" + result
cache.append(result)
print "scan finished, begin sleep " + str(sequence) + " seconds."
time.sleep(sequence)
except:
raise
Google Wave 使用体验
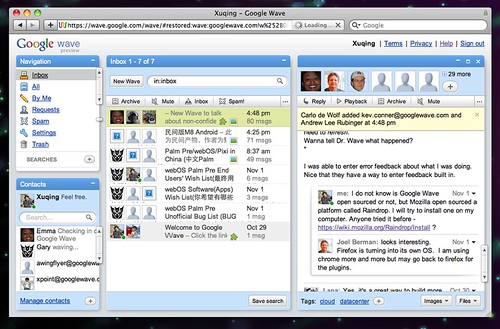
Google Wave 拿到有些日子了,写写这两天对它的感觉。
这东西到底是什么?团队协作平台?Email 接替者?Wiki?BBS?它给我的感觉什么都不是,而是展示 Google 网页开发实力,和最新 Web 开发技术的一个测试产品,也有可能是因为它目前的不完善导致定位不明确吧。
打开 Wave 之后,就会看到浏览器的加载小滚轮一刻不停地滚动着,因为它需要时刻不断地连接到服务器上,获取好友以及消息的信息,在 Wave 的演示视频上我们可以看到,当 Contacts 在某个”波“里打的字,会即时显示在页面上。这是 Google 强大云计算的佐证。
奇异的滚动条,有点像 Aperture 里的风格,颠覆了传统滚动条的概念,点击直接贴伏在 Bar 上地向上按钮的时候,页面会轻轻地向上地滚动一点点,但是将 Bar 直接向下拖到底,页面不是跟着滚动着到底,而是会像开了”平滑滚动“似地划过浏览器。加上所有可以随意伸缩、最小化的面板。这是最新 Web 开发技术的佐证,而这其中有 Google 很大的功劳。
不过我依然觉得它定位不明确,缺乏 BBS 的公开,Wiki 的开放,Email 的便于查询,团队协作平台的目标性
一个 Wave 就是一个话题,用空格键在所有未读的回复间切换,对于不感兴趣的 Wave 可以 Archive 掉。用户可以很轻易地上传各种文档到自己的 Wave 中(拖拽上传对 Safari 似乎无效)。超酷的操作方式似乎才是 Wave 的全部。
我倒希望它能在未来的版本中进一步完善。
有账号的可以加我 Wave - xuqingkuang # googlewave.com
十月总结
到月末了,对这两个月做一下总结。
首先是 VirtLAB,这个从三月开始的自动化测试项目,该项目用于在 QE 团队内部替代 RHTS,由于是重新设计的 Database schema,所以我可以充分发挥 Django 自身的优势,也是因为通过 VirtLAB,使我的 Django 水平得到了极大提高,同时由于 UI 前端是自己编写的,所以对 Javascript 也远远胜过之前。现在无论是 Django 本身的 ORM,Template,Form 都很难难到我了,自定义 ORM model field、Form 的 RequestContext Processor,Field 和 Template 的 Tag、Filter 也都得心应手。
在这两个月里,VirtLAB 发展到了 2.0,主要是增加了 Queue,用于在一台机器上建立一个 Job 队列,可以同时在一台机器上排上多个 Job,一个一个重启电脑,重装系统后执行测试脚本的特性;另一个就是晚上趁着没人的时候,自动根据数据库覆盖率(在哪些机器上运行过),跑测试的功能,所以界面也换成了夜间的风格。
新版本极大地提高了自动化功能,由测试人员编写好测试脚本,白天可以由测试人员自己提交 Job 在不同的机器上执行并实时观测运行过程,晚上下班后程序也会将那些在一些机器上没有跑过的测试执行一遍,最终做到每一个测试脚本在所有的机器上都执行一遍,以检查系统是否能够在不同类型的机器上稳定运行。
另一个是用于手动测试的 TCMS(与 Testopia database schema 完全兼容的 Test Case Management System),半年前将它撂下,现在又重新捡起来了,经过 VirtLAB 的磨砺,而且新版本里可以加表,所以我对这个代码进行了重构,使用了大量 Django 自身的特性,比如 ACL 和自带的 Admin Page。和 VirtLAB 一样,使用了 python-kerberos 做了个 Kerberos 的用户名密码验证。因为 Testopia 的数据表结构比较复杂,所以对整个 Models 进行了重构,用 ForeignKey 和 ManyToManyField 重新进行了组织,自行编写了 TimeAsTimeDeltaField 来处理 Test Case 的 Estimated Time。
UI 也经过丹青的重新设计,变得更加的方便、易用。
总之,是个脱胎换骨的版本。
明天,30 号就是正式内部使用的日子,svn 的版本号也相当吉利 2046。我们将正式用它来代替服役了很长时间的 Test Runner 和根本不成熟且有版权问题的 Testopia。
下一步计划 - 更加地自动化:
VirtLAB 将对每台机器加上 Tag,以后选机器不用去看主机名了,只要选好自己需要的配制,比如要 Intel 的处理器啊,要超过 4G 内存啊,就可以自动根据所选条件,自动选择空闲的机器,最快速地完成需要完成的 Job。
TCMS 将进一步对代码进行重构,进一步 Django app 化,同时完成 Report,以及和外部程序沟通的功能,目前只能将 Failed 的 Case 用 File a bug 链接直接提交到 Bugzilla 上,下一步将和 VirtLAB 和 ATP 整合,直接在 TCMS 里操作 VirtLAB 里的测试脚本。
BTW: 前一端时间公司内部开始使用 Redmine 进行内部项目管理,这个用 Rails 编写的工具确实有很多独到的特性,可以看看。
又加了三台电脑的 nbench 测试成绩
这次把自己的笔记本和台式机,还有一台虚拟机服务器都跑了一下,得到了以下结果。
其中我的笔记本,Macbook Pro (2008 Early),内置了 Intel Core 2 Duo T8300 的处理器,得到测试冠军,工作站 HP XW4600 虽然使用的处理器是 2.5Ghz E7200 的,但是比起 2.4GHz 的 T8300,性能还是有一定差距的。所以不要迷信 Intel 处理器的主频,真的有差别。
跑自己的服务器纯粹是因为我的 Web server 在上面反应真的比较慢,所以跑了一下,那个 Xen 的版本比较老了,还是 3.0.x 的,新版本能够支持 Intel VT 和 AMD-V 技术,相信性能会好不少,因为是处理器直接支持虚拟化的,只是我手头暂时没有机器测试,RHEL 5.4 里将要内置的 KVM 也很值得期待。
| Macbook Pro(T8300) | Mac OS X 10.6.0 Beta1 | 20.190 | 37.898 | 22.963 |
| HP XW4600(E7200) | Fedora 11 | 17.013 | 36.669 | 16.797 |
| RHEL in Xen(AMD 8356) | RHEL 5.3 Running in Xen | 11.694 | 14.412 | 9.201 |
详情请到 http://xuqingkuang.is-programmer.com/2006/10/10/nbench.6107.html 查看,测试的详细日志那里都有。
Rate My Life Quiz!
| This Is My Life, Rated | |
| Life: | |
| Mind: | |
| Body: | |
| Spirit: | |
| Friends/Family: | |
| Love: | |
| Finance: | |
| Take the Rate My Life Quiz | |
刚看到 TualatriX 上 Rate My Life Quiz 的链接,顺道也给自己做了下测试,结果还行,除了 Friends/Family 以外都还可以。
很奇怪我的 Body 指数居然是最高的,难道是因为没什么不良嗜好而且保持了良好睡眠?!不过北京的气候真的让人感觉很不舒服,在“你是否生活在一个有污染的环境中”的选项上,我毫不犹豫地打了一个勾,要没它估计就 10 分满分了。。。
Friends/Family 和 Love 虽然是最低,可能因为我已经有了稳定关系了,而且比较恋家,所以还是相对地高的~(^_^)
Finance 项现在在开源节流,还是颇有成效的,每个月还能有少许赢余,要点是买东西之前好好想想那个东西是否真的对你的生活有促进作用,而不仅仅是一时冲动或者 Hobby,家里有个财务顾问还是很不错的。 ^o^
别的人的测试地址在下面,请允许我把你们的地址贴出来:
Contrast: http://contrast.yo2.cn/archives/41840
TualatriX: http://imtx.cn/archives/1282.html
在 Fedora 上安装并使用 Chromium
Chromium 官方只提供了 for 乌班兔的 deb 包,好在从 Solidot 上看到已经有好心人在 Fedora 上也编译了一份,经过试验运行起来没有问题,功能也已经比较完备了,可以满足最基本使用需求,速度却比 Firefox 要快了很多,基于对 Webkit 的好感,以后它就是我的主力浏览器了(这话前两天好像刚说过 :-p)。
我也写了个的 repo 文件,以便于用 yum 升级,内容很简单,把下面内容以文件名 chromium.repo 存放到 /etc/yum.repos.d 里就好了:
如果想偷一把小懒的话,也可以去 http://www.box.net/shared/rbyeny0bge 里下载,并放到 /etc/yum.repos.d,不过 box.net 好像被墙了,可能需要翻墙。。。
然后在终端里运行 # yum install chromium,就可以了
让闲着没事干的机器去算外星人去。
办公室有闲电脑?拿来算外星人吧。
前一段时间 SETI@Home 项目组又发了好几封邮件,需要更多计算力量和赞助来处理大量的数据(有说是共有 15T,有说是每天 10G,一年300G ?! -_-#)。
装上服务器的 Linux(其它平台也可以),装上 Boinc,就让它自己跑吧,有 NVIDIA 显卡的可以开启 CUDA,确实可以提高运算速度。
详情可以参考:
http://zh.wikipedia.org/wiki/SETI
也有更多项目等待你的参与:
寻找引力波的 Einstein@Home: http://einstein.phys.uwm.edu/
了解了解蛋白质折叠的 Folding@home: http://folding.stanford.edu/
BTW: 现在电脑的性能确实突飞猛进,几天算的相当我之前一个月的运算量了。
[转帖] Python 中 switch 的解决办法
其他语言中,switch语句大概是这样的
switch (var)
{
case value1: do_some_stuff1();
case value2: do_some_stuff2();
…
case valueN: do_some_stuffN();
default: do_default_stuff();
}
{
case value1: do_some_stuff1();
case value2: do_some_stuff2();
…
case valueN: do_some_stuffN();
default: do_default_stuff();
}
而python本身没有switch语句,解决方法有以下3种:
Spotify - 超好用的音乐共享软件
从 CNBeta 的新闻上看有 Spotify 这款音乐共享软件,据说是 uTorrent 的创始人 Ludvig Strigeus 写的,Down 下来了一份,试了一下,果然不同凡响。
延时很短(几乎没有),而且都是很新的金曲,最关键的是曲子都很好听!
下载链接在: www.spotify.com/en/download/
目前只支持 Windows 和 Mac,如果想在 Linux 上用,可以使用 wine,这里有篇 Guide:
www.spotify.com/en/help/faq/wine/
=========================================================
我这里只对如何注册说一下,现在 Spotify 对英国境外的人都使用邀请方式(在英国的朋友有福了;-)),而包括我在内都是没有邀请码的。
所以按照新闻走,去 www.proxz.com/proxy_list_uk_0_ext.html 上找个英国的代理,在使用前最好 ping 一下,看看能否连上。
我用的是 212.241.180.239:81 这个地址。
然后去改代理,Mac OS X 在 System Preferences 的 Network 的 Advanced 里。
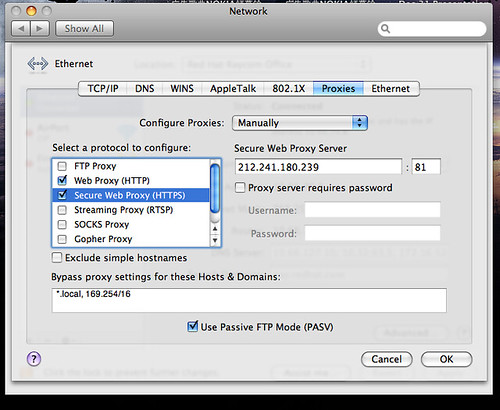
把 HTTP 和 HTTPS 的代理都选上,都改掉,然后访问:
www.spotify.com/en/get-started/
应该就是注册新帐号的页面了 ;-)

Spotify 不但是很好的音乐共享软件(其实仅限于从服务器上抓下音乐来,好像不能自己把音乐共享出去),而且还是很好的 Last.FM 客户端,在 Preferences 里填入 Last.FM 帐号后就可以自动连接 Last.FM。
最关键的是它是完整长度的试听,只是不能下载(可以 HiJack 下来,哈~)
很值得一试喔 ;-)
=========================================================
手头有五个邀请,想要的可以留邮箱。
=========================================================
用邀请码注册还是会区分国家,所以还得用代理注册。
QuartzGL ?!
这 Tiger 里据称就是原来的 Quartz 2D Exteme,到 Leopard 里换了个名字叫 QuartzGL 了。刚刚在 Quartz Debug 的 Tools 菜单里看见有开启它的选项,所以就开了一下,用 xbench 跑了跑测试,结果居然比不开性能还差,而且还导致一些应用程序的不兼容现象出现(QuickSliver 启动画面成一半透明白框,据说Dashboard也会有问题),所以我还是关了。
开启方法是:
$ sudo defaults write /Library/Preferences/com.apple.windowserver QuartzGLEnabled -boolean YES
恢复方法是:
$ sudo defaults write /Library/Preferences/com.apple.windowserver QuartzGLEnabled -boolean NO
注销即可,不过我为了测试结果的准确性重启了电脑。
开了后的结果:
Results 179.93 System Info Xbench Version 1.3 System Version 10.5.5 (9F33) Physical RAM 2048 MB Model MacBookPro4,1 Drive Type FUJITSU MHY2200BH Quartz Graphics Test 144.47 Line 181.54 12.09 Klines/sec [50% alpha] Rectangle 145.47 43.43 Krects/sec [50% alpha] Circle 235.46 19.19 Kcircles/sec [50% alpha] Bezier 78.55 1.98 Kbeziers/sec [50% alpha] Text 190.48 11.92 Kchars/sec OpenGL Graphics Test 164.98 Spinning Squares 164.98 209.29 frames/sec User Interface Test 271.05 Elements 271.05 1.24 Krefresh/sec
没开的结果:
Results 206.56 System Info Xbench Version 1.3 System Version 10.5.5 (9F33) Physical RAM 2048 MB Model MacBookPro4,1 Drive Type FUJITSU MHY2200BH Quartz Graphics Test 192.86 Line 176.63 11.76 Klines/sec [50% alpha] Rectangle 232.50 69.41 Krects/sec [50% alpha] Circle 189.12 15.42 Kcircles/sec [50% alpha] Bezier 189.01 4.77 Kbeziers/sec [50% alpha] Text 185.73 11.62 Kchars/sec OpenGL Graphics Test 167.72 Spinning Squares 167.72 212.76 frames/sec User Interface Test 296.17 Elements 296.17 1.36 Krefresh/sec
完整的测试结果在:http://db.xbench.com/merge.xhtml?doc1=327066&doc2=327063
注意:因为单独的图形结果和完整测试不是同一个时间完成,所以数据有所偏差
一个 Django 的超简单的数据库应用
昨天 Launch & Learn 的时候,做了个简单的 Django 的数据库应用,以配合 Li Li Zhang 的 ORM Course。
其实用 Django 做数据库应用真的很简单,不过比较适合用于重头设计的 Database Schema,然后用 syncdb 来同步数据库。
目前 Django 对 ForeignKey 和 One to One, One to Many, Many to Many 支持得都不错,最大的缺陷还是缺乏 Join 的支持导致多表联查的性能不好,这也是我在做开发的过程中碰到的最大问题。
其实用 Django 重头做一个数据库开发非常简单,用下面几步就可以了。
FIRST: Create new project and a new app with django-admin.py $ django-admin.py startproject [project_name] $ cd [project_name] $ django-admin.py startapp [app_name] SECOND: Edit the settings.py file to adjust db settings and installed apps. THIRD: Edit the [app_name]/models.py to modeling the database schema FOURTH: Edit the [prject_name]/urls.py to adjust the path of URL. FIFTH: Edit the [app_name]/views.py to realize your function. SIXTH: To run the manage.py to start the test server in the project. $ ./manage.py runserver THE END: Use your browser to navigate to your http://localhost:8000 and enjoy in it. :-)
这里提供了一个范例,也是昨天在 Launch and Learn 上演示过的:www.box.net/shared/6036abumgv 中的 lnl.tar.bz2 文件,里面提供的 Steps 其实就是上面那段,只是代码中也提供了注释以方便阅读。