高内聚、低耦合、SOA 和测试驱动。
软件工程:
随着软件工程的不断膨胀,功能的扩展变得愈发困难,因为增加一点点小功能而导致的 Regression 可能会越来越多,同时,因为项目越来越大,参与的人越来越多,代码的结构化、模块化便成了高质量产品非常重要的特性之一。
高内聚和低耦合,其实是好的模块化编程必须具备的两项特点,高内聚,我的理解模块独立完成特定,不重复实现其他模块已经实现过的逻辑,而低耦合,即模块与模块之间的直接连接要尽量低下,耦合性高,会导致牵一发而动全身,将导致未来的代码维护和功能扩展愈发艰难。
最简单的模块化即现在 Web 开发的 MVC 架构,数据库的建模部分由 Model 完成,页面展示由 Views 完成,而之间的协调和逻辑关系由 Controller 完成,以一个 Product 项目的创建为例,它会在创建时同时创建好另外两个字段的默认值 - Version 和 Component,当 Views 接收到用户的输入后,然后将它传递给 Controller,Controller 将会判断输入的合法性并同时创建好另外两个字段的类,再通过调用 Models 提供的方法将这三个类在数据库中持久化下来。
这需要在开发前定一套统一的 API,这样各个模块才能无障碍地随意调用。
那么这样的好处在哪里?其实是非常明显的,页面显示部分不用关注数据库会提供什么养的类型,而数据库也不用关注用户会提供什么格式的数据,都会因为中间 Controller 的调度和转化被统一起来,进而达到程序的模块化,以及开发人员的专职化。
以我自身经验为例,如果要和前端配合同时完成一套功能,我们会约定好我给他什么样的 Ajax method,参数是什么,返回的是什么样的格式,这样我们两个能够同时编写不同的代码,但到功能完成之时,将两个代码放在一起,直接就能运行起来。
SOA:
那么程序与程序之间的整合,使之同时完成一项功能如何才能做到?
传统的方法有提供 RPC 接口,轮询数据库或者文件系统,但是问题在哪里?
- XML-RPC 同样会出现错误,而且缺乏 Error handler
- 数据库和文件系统的轮询有很高的风险,首先轮询文件系统就以为着这个目录里的文件要小心放置了,因为不小心就会被程序轮询到,而因为轮询造成的数据库损坏的可能性更加难以纠正。
- 很低的内聚性,很高的耦合性,为了同步两个程序间的数据,可能得克隆一份对方程序里的数据结构和逻辑方法,一旦任何一方的数据结构或逻辑改变,将导致同步失败。
- 不实时,因为轮询总是有时间间隔的,轮询频繁会导致系统负载加重,轮询频率低了又容易等待时间过长。
那么程序之间的整合如何才能更好地做到,这就需要将 SOA 的思想引入进来了,SOA - Service Orient Architechture,面向服务的架构,程序与程序之间不再是程序,而是一个个的服务,这个服务可以通过 RPC 来实现对自身方法的调用,但是还有很重要的一点,是要将自身正在做的事情告诉别的程序。
下图是 Nitrate 项目目前的结构,其实我觉得它是模块化开发的一个典范了。
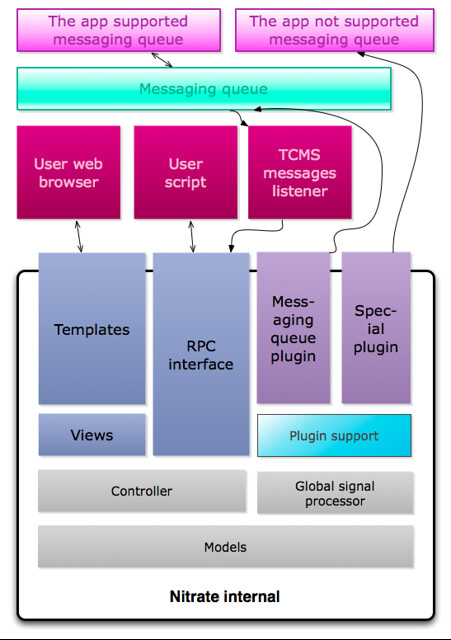
Nitrate 是标准的 MVC 架构,我来解释一下它的工作流,除了基本的 Web UI 界面和 XML-RPC 界面外,我们还提供了 Global signal processor(后简称 GSP)用于监听所有 Models 的信号,目前信号有三种 - Initial,对应于数据库的 SELECT 语句,Create 对应于数据库的 Insert 语句,Update 对应于数据库的 Update 语句,所有被注册的 Models 一旦发生以上动作将会出发对应的信号,然后 GSP 将信号推入 Plugin support(后简称PS),由它以线程方式将 Signal,Models 和触发消息的 Model Instance 交由 Plugin 处理。
这里我将 Plugin 分为了两类:
一类是 Special plugin,用于整合一些特殊的程序,这些程序不带有消息队列支持,它是以传统工具整合方式工作的,接受到信号后会根据已经定义好的参数判断信号是否符合条件,如符合则通过该 Special 程序提供的 RPC 接口将 TCMS 中的改动同步进该程序中,事实上该方法危险性较高,而且需要将对方的数据库表格和参数定义在插件里。
第二类是 Messaging queue plugin,这是我最偏好的方法,目前支持的 Messaging queue(以后简称 MQ)是 QPID,它将 Models 的 Signal 转译成 MQ 的数据格式,然后直接推入 MQ,然后别的需要 Nitrate 数据的程序可以提供第三方的一个 Sync middleware,作为两个程序间的桥梁对数据进行选择性的同步,这样的好处是逻辑不用重复实现,双方共享的数据之需要存在 Sync middleware 程序中即可,不影响双方逻辑和数据库结构。而 Nitrate 本身也提供了 TCMS Messenging listener 用于监听 MQ 内的 message,例如如果 Bugzilla 新创建了一个 Product,Nitrate 将很快便能监听到并在数据库中创建一份相同的 Product 供用户使用,全程自动化,智能化,无人干预。
“能听能说”的程序才能较好地整合到其它程序中,“听” 提供了 XML-RPC 接口,别的程序可以通过它更改 Nitrate 中的数据,“说”提供了 MQ 的支持,别的程序可以监听 Nitrate 中数据的变化,并以此为依据对自身数据进行添加、更改,而且不用存储对方数据表,不用了解对方的业务逻辑,只需要写好中间的 Sync middleware 即可,好处多多,其乐无穷。
测试驱动
在之前的 Scrum 培训总结中,我说到了 CI(Continuous Integration)是 Scrum 所要求必备的,那么为什么单元测试如此重要?
下面的图可以充分说明这点:
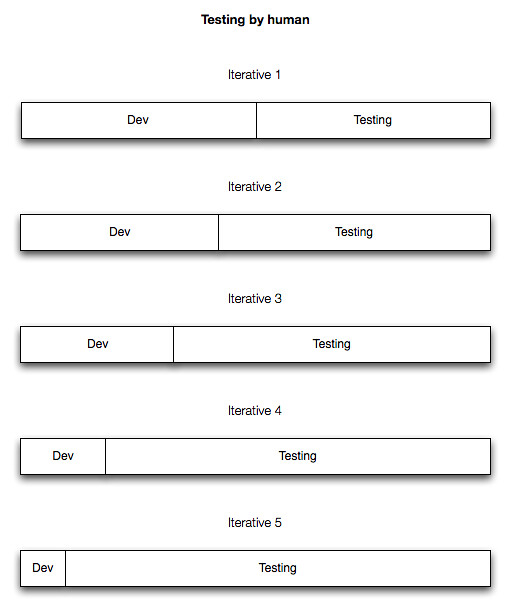
尽管手工测试可以降低编码时间,但这也仅仅是在项目非常非常小,而且没有后期维护成本的情况下。从上图可以看出,在第一个迭代的时候,开发如果和测试的时间是一样长,这或许可以生产出一个高质量的产品,但是到第二个迭代的时候,开发人员仅仅向软件中加入了很少的 Feature,但是测试却不能减少他们的工作量,依然要进行一遍完整的测试,而且还要检查是否有因为新加入的 Feature 导致的 Regression,到第三个迭代的时候开发的时间更加少,到第五个迭代后开发已经完全没用了,尽管测试占用的时间比例很大,但是依然无法保证测试完成,产品推到生产环境下会发现问题多多,开发人员就成了救火队员,下个迭代可能要用整个迭代的时间,去修上个迭代造成的 Bug,软件将停滞不前。
那么针对不同类型的语言和软件类型,有什么 Unit Testing 的方式呢?
这要从语言的类型和特点说起了。
* HTML,CSS - 前段,结构远远大于逻辑的语言。因为浏览器的兼容性问题,它是最难进行自动化测试的语言,但是依然是有办法的,可以使用类似 Dogtail 类的自动UI点击程序,判断 Console 中的错误输出,或者使用 W3C Validator 一类的工具,对它进行错误判断。
* Python/PHP/Java - 后端,结构和逻辑并重的语言。其实它是最好编写 Unit testing 的语言,因为它只负责一件事情:提供 API 供调用,我们只需要模拟输入,判断程序是否会出现 Error 即可,Django 提供了很好的 Unit testing 框架,可以模拟客户端的提交数据,以检测 Views 和 Controller 能否正常工作,Models 能否对数据库正常读写,或者 ForeignKey 的正确性也可以通过 UT 进行验证,Java 也提供了 JUnit 等工具。
* Javascript/其它 UI 语言 - 前端,结构和逻辑并重的语言。这是最有意思的地方,很多人说 UI 类的语言的 UT 非常难以编写,因为无法验证最终的正确性,其实仔细观察就可以看出,这类语言,其实只是调用了后端提供的 API,也就是说,对于此类语言,一检查提供给后端的 API 的参数是否正确,二检查能否将后端的返回正常生成数据结构并反应在页面上即可。前者依然可以通过检查后端的出错情况,而后者可以通过更改编码方式,将逻辑层和显示层拆分解决,例如后端返回的数据需要生成一个按钮,只需要将生成按钮的代码拆分,并通过单元测试检查按钮是否正常生成并符合条件即可,因为只要能正常生成,基本上现实在页面上不会出太大问题,这是基本功能了。
另外说一句有意思的事情,前两天听说了另一种 UT 的方式,名称叫 Monkey,写一个程序在屏幕上随机乱点,只要程序能稳定跑上几个小时就算通过,这来源于让猴子敲键盘,总有一天能敲出莎士比亚全集的传说。这也算是很有创意了,只是我觉得这不能叫 UT,可能只能叫 RT(Random Testing)了,缺点很明显,一是无法针对某个功能,二难以重现(可重现的 Bug 对开发人员很重要),三难以统计。
 Comments (0)
Comments (0)